Einführung
Jede Anwendung oder Website, die ein signifikantes Wachstum verzeichnet, muss irgendwann skaliert werden, um dem steigenden Datenverkehr gerecht zu werden. Für datengesteuerte Anwendungen und Websites ist es entscheidend, dass die Skalierung auf eine Weise erfolgt, die die Sicherheit und Integrität der Daten gewährleistet. Es kann schwierig sein, vorherzusagen, wie populär eine Website oder Anwendung werden wird oder wie lange sie diese Popularität beibehalten wird, weshalb einige Unternehmen eine Datenbankarchitektur wählen, die es ihnen ermöglicht, ihre Datenbanken dynamisch zu skalieren.
In diesem konzeptionellen Artikel werden wir eine solche Datenbankarchitektur besprechen: Sharded-Datenbanken. Sharding hat in den letzten Jahren viel Aufmerksamkeit erhalten, aber viele haben kein klares Verständnis davon, was es ist oder in welchen Szenarien es sinnvoll sein könnte, eine Datenbank zu sharen. Im Folgenden wird erläutert, was Sharding ist, welche Vor- und Nachteile es hat und welche Sharding-Methoden es gibt.
Was ist Sharding?
Sharding ist ein Datenbankarchitekturmuster, das mit der horizontalen Partitionierung verwandt ist – der Praxis, die Zeilen einer Tabelle in mehrere verschiedene Tabellen, so genannte Partitionen, aufzuteilen. Jede Partition hat das gleiche Schema und die gleichen Spalten, aber auch völlig unterschiedliche Zeilen. Ebenso sind die Daten in jeder Partition eindeutig und unabhängig von den Daten in anderen Partitionen.
Es kann hilfreich sein, die horizontale Partitionierung in Bezug auf die vertikale Partitionierung zu betrachten. In einer vertikal partitionierten Tabelle werden ganze Spalten herausgetrennt und in neue, getrennte Tabellen gelegt. Die Daten in einer vertikalen Partition sind unabhängig von den Daten in allen anderen, und jede enthält sowohl unterschiedliche Zeilen als auch Spalten. Das folgende Diagramm veranschaulicht, wie eine Tabelle sowohl horizontal als auch vertikal partitioniert werden kann:
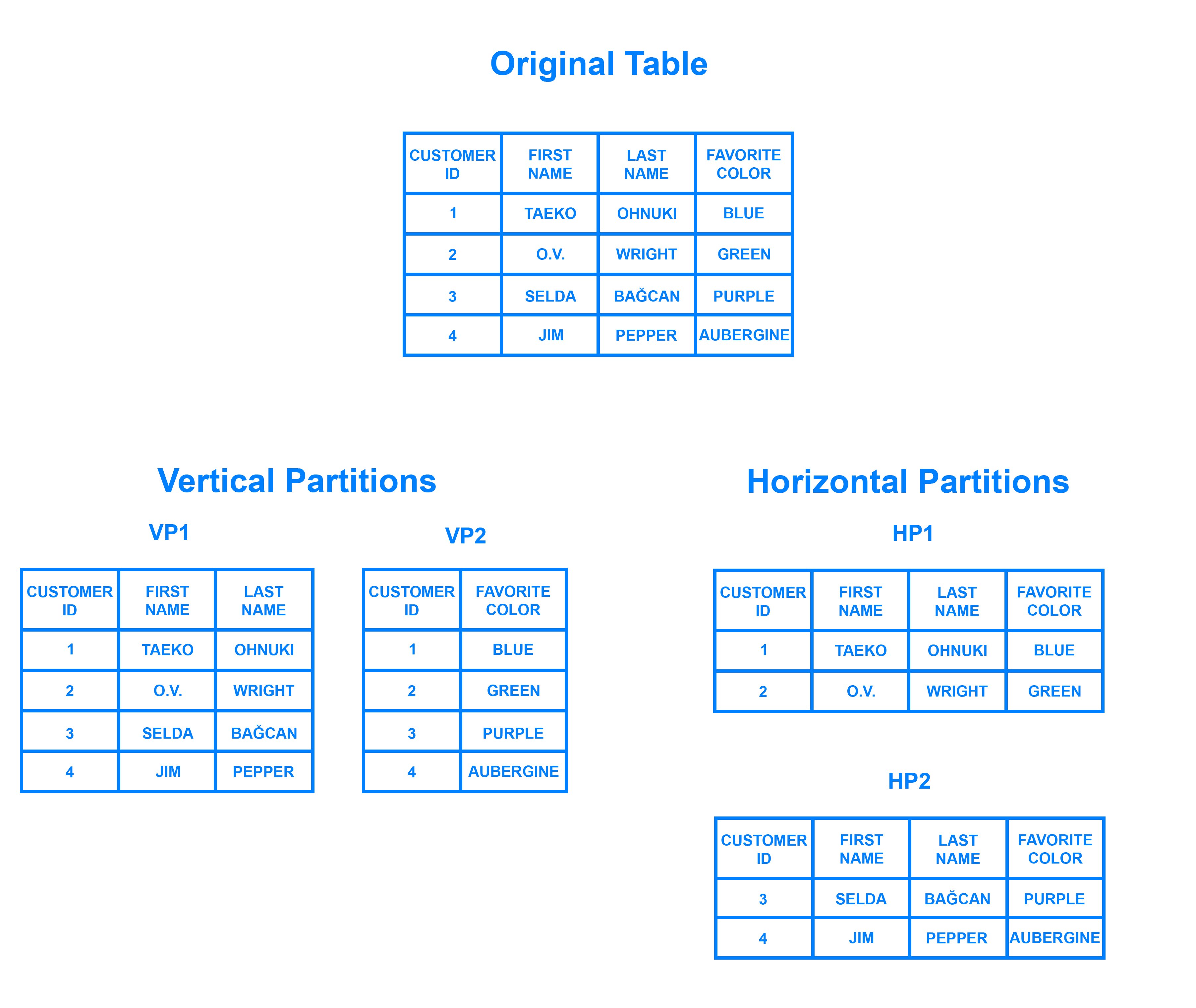
Sharding beinhaltet die Aufteilung der Daten in zwei oder mehr kleinere Teile, die sogenannten logischen Shards. Die logischen Shards werden dann auf separate Datenbankknoten verteilt, die als physische Shards bezeichnet werden und mehrere logische Shards enthalten können. Trotzdem stellen die Daten in allen Shards zusammen einen gesamten logischen Datenbestand dar.
Datenbank-Shards sind ein Beispiel für eine Shared-Nothing-Architektur. Das bedeutet, dass die Shards autonom sind; sie teilen sich keine der gleichen Daten oder Rechenressourcen. In einigen Fällen kann es jedoch sinnvoll sein, bestimmte Tabellen in jeden Shard zu replizieren, um als Referenztabellen zu dienen. Nehmen wir zum Beispiel an, es gibt eine Datenbank für eine Anwendung, die auf feste Umrechnungsraten für Gewichtsmessungen angewiesen ist. Durch die Replikation einer Tabelle mit den erforderlichen Umrechnungsdaten in jeden Shard würde sichergestellt, dass alle für Abfragen erforderlichen Daten in jedem Shard vorhanden sind.
Oftmals wird Sharding auf Anwendungsebene implementiert, d. h. die Anwendung enthält Code, der definiert, in welchen Shard Lese- und Schreibvorgänge übertragen werden sollen. Einige Datenbankmanagementsysteme verfügen jedoch über integrierte Sharding-Funktionen, die es ermöglichen, Sharding direkt auf Datenbankebene zu implementieren.
Nach diesem allgemeinen Überblick über Sharding wollen wir nun einige positive und negative Aspekte dieser Datenbankarchitektur betrachten.
Vorteile von Sharding
Der Hauptvorteil von Sharding ist, dass es die horizontale Skalierung, auch bekannt als Skalierung nach außen, erleichtert. Unter horizontaler Skalierung versteht man das Hinzufügen weiterer Maschinen zu einem bestehenden Stack, um die Last zu verteilen und mehr Verkehr und schnellere Verarbeitung zu ermöglichen. Im Gegensatz dazu wird bei der vertikalen Skalierung die Hardware eines bestehenden Servers aufgerüstet, in der Regel durch Hinzufügen von mehr RAM oder CPU.
Es ist relativ einfach, eine relationale Datenbank auf einem einzigen Rechner laufen zu lassen und sie bei Bedarf durch Aufrüsten der Rechenressourcen zu erweitern. Letztendlich ist jedoch jede nicht verteilte Datenbank in Bezug auf Speicher- und Rechenleistung begrenzt, so dass die Freiheit, horizontal zu skalieren, Ihr Setup viel flexibler macht.
Ein weiterer Grund, warum sich manche für eine Sharded-Datenbankarchitektur entscheiden, ist die Beschleunigung der Antwortzeiten auf Abfragen. Wenn Sie eine Abfrage an eine Datenbank stellen, die nicht geshared wurde, muss sie möglicherweise jede Zeile in der Tabelle, die Sie abfragen, durchsuchen, bevor sie die gesuchte Ergebnismenge finden kann. Für eine Anwendung mit einer großen, monolithischen Datenbank können Abfragen unerschwinglich langsam werden. Durch das Sharding einer Tabelle in mehrere, müssen Abfragen jedoch über weniger Zeilen gehen und ihre Ergebnismengen werden viel schneller zurückgegeben.
Sharding kann auch dazu beitragen, eine Anwendung zuverlässiger zu machen, indem die Auswirkungen von Ausfällen gemildert werden. Wenn Ihre Anwendung oder Website auf einer nicht gesharten Datenbank basiert, kann ein Ausfall dazu führen, dass die gesamte Anwendung nicht mehr verfügbar ist. Bei einer Sharded-Datenbank hingegen wird ein Ausfall wahrscheinlich nur einen einzigen Shard betreffen. Auch wenn dadurch einige Teile der Anwendung oder der Website für einige Benutzer nicht verfügbar sind, sind die Auswirkungen insgesamt geringer, als wenn die gesamte Datenbank abstürzt.
Nachteile von Sharding
Während das Sharding einer Datenbank die Skalierung vereinfachen und die Leistung verbessern kann, kann es auch gewisse Einschränkungen mit sich bringen. Hier besprechen wir einige davon und warum sie Gründe sein könnten, Sharding ganz zu vermeiden.
Die erste Schwierigkeit, auf die man beim Sharding stößt, ist die schiere Komplexität der korrekten Implementierung einer Sharded-Datenbankarchitektur. Wenn es falsch gemacht wird, besteht ein erhebliches Risiko, dass der Sharding-Prozess zu Datenverlusten oder beschädigten Tabellen führen kann. Aber auch wenn es richtig gemacht wird, hat Sharding wahrscheinlich einen großen Einfluss auf die Arbeitsabläufe Ihres Teams. Anstatt von einem einzigen Einstiegspunkt aus auf die eigenen Daten zuzugreifen und sie zu verwalten, müssen die Benutzer die Daten über mehrere Sharding-Speicherorte hinweg verwalten, was für einige Teams potenziell störend sein kann.
Ein Problem, auf das Benutzer manchmal stoßen, nachdem sie eine Datenbank geshardet haben, ist, dass die Shards irgendwann unausgewogen werden. Nehmen wir an, Sie haben eine Datenbank mit zwei separaten Shards, einen für Kunden, deren Nachnamen mit den Buchstaben A bis M beginnen, und einen für Kunden, deren Namen mit den Buchstaben N bis Z beginnen. Ihre Anwendung bedient jedoch eine übermäßige Anzahl von Personen, deren Nachnamen mit dem Buchstaben G beginnen. Der A-M-Shard ist zu einem so genannten Datenbank-Hotspot geworden. In diesem Fall werden alle Vorteile des Shardings der Datenbank durch die Verlangsamungen und Abstürze zunichte gemacht. Die Datenbank müsste wahrscheinlich repariert und neu geshared werden, um eine gleichmäßigere Datenverteilung zu ermöglichen.
Ein weiterer großer Nachteil ist, dass es sehr schwierig sein kann, eine einmal gesharte Datenbank wieder in die nicht gesharte Architektur zurückzubringen. Alle Backups der Datenbank, die vor dem Sharding erstellt wurden, enthalten keine Daten, die seit der Partitionierung geschrieben wurden. Um die ursprüngliche Architektur wiederherzustellen, müssten die neuen partitionierten Daten mit den alten Backups zusammengeführt werden, oder die partitionierte DB müsste wieder in eine einzelne DB umgewandelt werden, was beides kostspielige und zeitaufwändige Unterfangen wären.
Ein letzter Nachteil ist, dass Sharding nicht von jeder Datenbank-Engine nativ unterstützt wird. PostgreSQL zum Beispiel bietet kein automatisches Sharding an, obwohl es möglich ist, eine PostgreSQL-Datenbank manuell zu sharen. Es gibt eine Reihe von Postgres-Forks, die automatisches Sharding enthalten, aber diese hinken oft hinter dem neuesten PostgreSQL-Release hinterher und es fehlen bestimmte andere Funktionen. Einige spezialisierte Datenbanktechnologien – wie MySQL Cluster oder bestimmte Datenbank-as-a-Service-Produkte wie MongoDB Atlas – beinhalten automatisches Sharding als Funktion, aber die Vanilla-Versionen dieser Datenbankmanagementsysteme nicht. Aus diesem Grund erfordert Sharding oft einen „Roll your own“-Ansatz. Das bedeutet, dass die Dokumentation für Sharding oder Tipps zur Fehlerbehebung oft schwer zu finden sind.
Dies sind natürlich nur einige allgemeine Aspekte, die vor dem Sharding zu beachten sind. Je nach Anwendungsfall kann es noch viele weitere potenzielle Nachteile beim Sharding einer Datenbank geben.
Nachdem wir nun einige Nachteile und Vorteile von Sharding behandelt haben, werden wir nun einige verschiedene Architekturen für gesharte Datenbanken vorstellen.
Sharding-Architekturen
Wenn Sie sich für das Sharding Ihrer Datenbank entschieden haben, müssen Sie als Nächstes herausfinden, wie Sie dabei vorgehen wollen. Wenn Sie Abfragen ausführen oder eingehende Daten auf Sharding-Tabellen oder -Datenbanken verteilen, ist es entscheidend, dass sie an den richtigen Shard gehen. Andernfalls könnte es zu Datenverlusten oder schmerzhaft langsamen Abfragen kommen. In diesem Abschnitt gehen wir auf einige gängige Sharding-Architekturen ein, die jeweils ein leicht unterschiedliches Verfahren zur Verteilung von Daten auf Shards verwenden.
Schlüsselbasiertes Sharding
Schlüsselbasiertes Sharding, auch bekannt als hashbasiertes Sharding, beinhaltet die Verwendung eines Wertes aus neu geschriebenen Daten – z. B. die ID-Nummer eines Kunden, die IP-Adresse einer Client-Anwendung, eine Postleitzahl usw. – und das Einsetzen in eine Hash-Funktion, um zu bestimmen, zu welchem Shard die Daten gehen sollen. Eine Hash-Funktion ist eine Funktion, die als Eingabe einen Teil der Daten (z. B. eine Kunden-E-Mail) nimmt und einen diskreten Wert ausgibt, der als Hash-Wert bekannt ist. Im Fall von Sharding ist der Hash-Wert eine Shard-ID, die verwendet wird, um zu bestimmen, auf welchem Shard die eingehenden Daten gespeichert werden sollen. Insgesamt sieht der Prozess so aus:

Um sicherzustellen, dass Einträge in den richtigen Shards und auf konsistente Weise abgelegt werden, sollten die in die Hash-Funktion eingegebenen Werte alle aus derselben Spalte stammen. Diese Spalte wird als Shard-Schlüssel bezeichnet. Vereinfacht ausgedrückt, ähneln Shard-Schlüssel den Primärschlüsseln insofern, als es sich bei beiden um Spalten handelt, die dazu dienen, einen eindeutigen Bezeichner für einzelne Zeilen festzulegen. Grob gesagt sollte ein Shard-Schlüssel statisch sein, d. h. er sollte keine Werte enthalten, die sich im Laufe der Zeit ändern könnten. Andernfalls würde dies den Arbeitsaufwand für Aktualisierungsoperationen erhöhen und könnte die Leistung beeinträchtigen.
Während das schlüsselbasierte Sharding eine recht verbreitete Sharding-Architektur ist, kann es schwierig werden, wenn Sie versuchen, dynamisch zusätzliche Server zu einer Datenbank hinzuzufügen oder zu entfernen. Beim Hinzufügen von Servern benötigt jeder einen entsprechenden Hash-Wert, und viele der vorhandenen Einträge, wenn nicht sogar alle, müssen auf ihren neuen, korrekten Hash-Wert umgeschrieben und dann auf den entsprechenden Server migriert werden. Wenn Sie mit dem Neuabgleich der Daten beginnen, werden weder die neuen noch die alten Hash-Funktionen gültig sein. Folglich kann Ihr Server während der Migration keine neuen Daten schreiben, und Ihre Anwendung könnte ausfallen.
Der Hauptreiz dieser Strategie liegt darin, dass sie zur gleichmäßigen Verteilung von Daten verwendet werden kann, um Hotspots zu vermeiden. Da die Daten algorithmisch verteilt werden, ist es nicht notwendig, eine Karte zu führen, auf der alle Daten verzeichnet sind, wie es bei anderen Strategien wie dem bereichs- oder verzeichnisbasierten Sharding der Fall ist.
Bereichsbasiertes Sharding
Beim bereichsbasierten Sharding werden die Daten auf Basis von Bereichen eines bestimmten Werts gesharded. Zur Veranschaulichung: Nehmen wir an, Sie haben eine Datenbank, die Informationen über alle Produkte im Katalog eines Einzelhändlers speichert. Sie könnten ein paar verschiedene Shards erstellen und die Informationen der einzelnen Produkte basierend auf der Preisspanne, in die sie fallen, wie folgt aufteilen:

Der Hauptvorteil von bereichsbasiertem Sharding ist, dass es relativ einfach zu implementieren ist. Jeder Shard enthält einen anderen Datensatz, aber sie haben alle ein identisches Schema wie die Originaldatenbank. Der Anwendungscode liest einfach, in welchen Bereich die Daten fallen und schreibt sie in den entsprechenden Shard.
Auf der anderen Seite schützt das bereichsbasierte Sharding nicht davor, dass die Daten ungleichmäßig verteilt werden, was zu den bereits erwähnten Datenbank-Hotspots führt. Betrachtet man das Beispieldiagramm, so ist die Wahrscheinlichkeit groß, dass bestimmte Produkte mehr Aufmerksamkeit erhalten als andere, selbst wenn jeder Shard die gleiche Menge an Daten enthält. Deren jeweilige Shards erhalten wiederum eine überproportionale Anzahl von Lesezugriffen.
Verzeichnisbasiertes Sharding
Um verzeichnisbasiertes Sharding zu implementieren, muss man eine Nachschlagetabelle erstellen und pflegen, die einen Shard-Schlüssel verwendet, um den Überblick darüber zu behalten, welcher Shard welche Daten enthält. Kurz gesagt ist eine Nachschlagetabelle eine Tabelle, die einen statischen Satz von Informationen darüber enthält, wo bestimmte Daten gefunden werden können. Das folgende Diagramm zeigt ein vereinfachtes Beispiel für verzeichnisbasiertes Sharding:
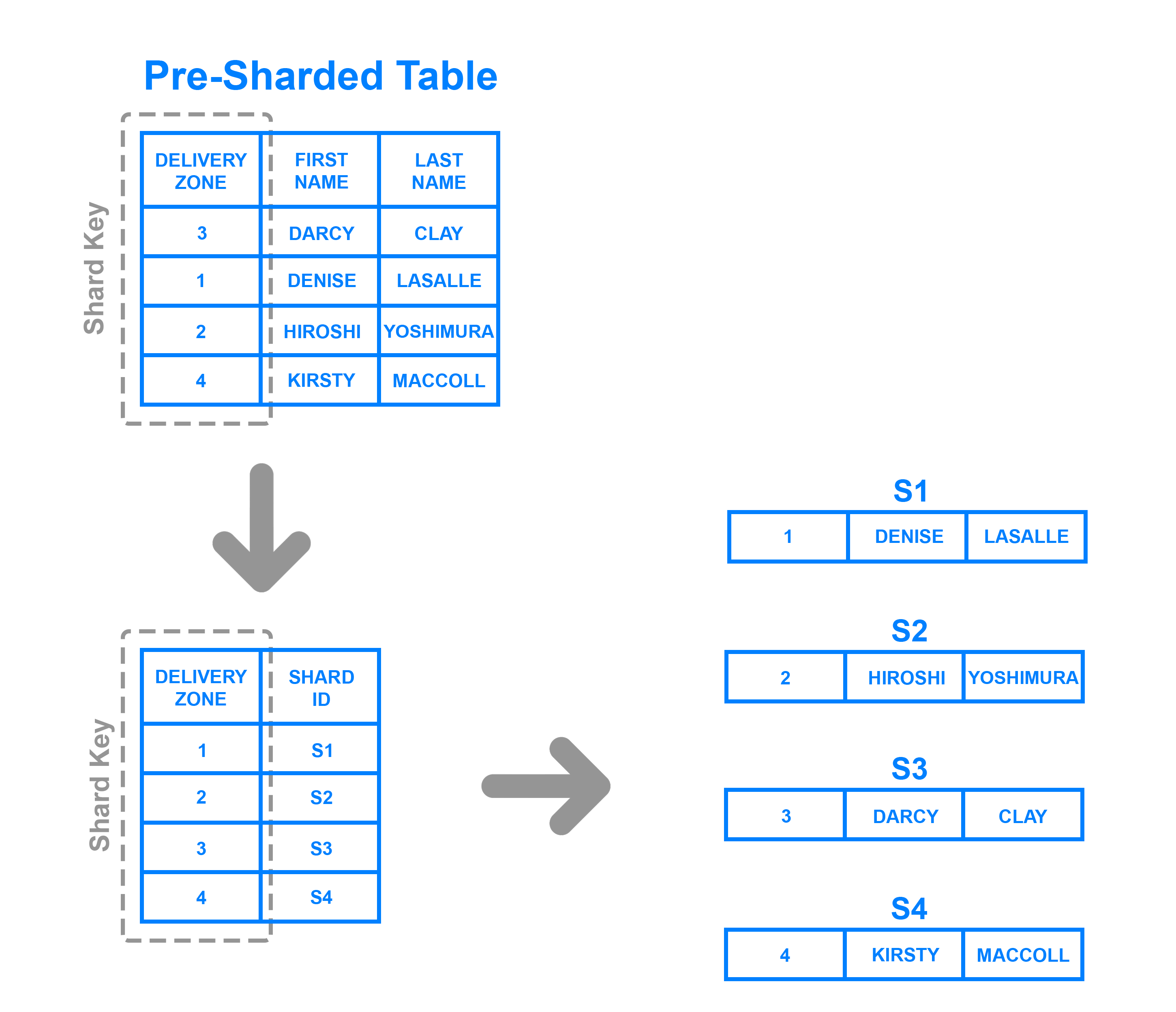
Hier ist die Spalte „Delivery Zone“ als Shard-Schlüssel definiert. Die Daten aus dem Shard-Schlüssel werden in die Lookup-Tabelle geschrieben, zusammen mit dem Shard, in den die jeweilige Zeile geschrieben werden soll. Dies ist ähnlich wie das bereichsbasierte Sharding, aber anstatt zu bestimmen, in welchen Bereich die Daten des Shard-Schlüssels fallen, ist jeder Schlüssel an seinen eigenen spezifischen Shard gebunden. Verzeichnisbasiertes Sharding ist eine gute Wahl gegenüber bereichsbasiertem Sharding in Fällen, in denen der Shard-Schlüssel eine geringe Kardinalität hat und es für einen Shard nicht sinnvoll ist, einen Bereich von Schlüsseln zu speichern. Beachten Sie, dass es sich vom schlüsselbasierten Sharding auch dadurch unterscheidet, dass es den Shard-Schlüssel nicht durch eine Hash-Funktion verarbeitet, sondern den Schlüssel nur mit einer Nachschlagetabelle abgleicht, um zu sehen, wo die Daten geschrieben werden müssen.
Der Hauptvorteil des verzeichnisbasierten Shardings ist seine Flexibilität. Bereichsbasierte Sharding-Architekturen beschränken sich auf die Angabe von Wertebereichen, während schlüsselbasierte eine feste Hash-Funktion verwenden, die, wie bereits erwähnt, später nur sehr schwer zu ändern ist. Beim verzeichnisbasierten Sharding hingegen können Sie ein beliebiges System oder einen beliebigen Algorithmus verwenden, um Dateneinträge den Shards zuzuordnen, und es ist relativ einfach, mit diesem Ansatz dynamisch Shards hinzuzufügen.
Während das verzeichnisbasierte Sharding die flexibelste der hier besprochenen Sharding-Methoden ist, kann sich die Notwendigkeit, vor jeder Abfrage oder jedem Schreibvorgang eine Verbindung zur Lookup-Tabelle herzustellen, nachteilig auf die Leistung einer Anwendung auswirken. Darüber hinaus kann die Lookup-Tabelle zu einem Single Point of Failure werden: Wenn sie beschädigt wird oder anderweitig ausfällt, kann dies die Fähigkeit beeinträchtigen, neue Daten zu schreiben oder auf die vorhandenen Daten zuzugreifen.
Sollte ich sharen?
Ob man eine sharded Datenbankarchitektur implementieren sollte oder nicht, ist fast immer eine Frage der Debatte. Einige sehen Sharding als unausweichliches Ergebnis für Datenbanken, die eine bestimmte Größe erreichen, während andere es als ein Kopfzerbrechen betrachten, das aufgrund der operativen Komplexität, die Sharding hinzufügt, vermieden werden sollte, wenn es nicht absolut notwendig ist.
Aufgrund dieser zusätzlichen Komplexität wird Sharding in der Regel nur dann durchgeführt, wenn es um sehr große Datenmengen geht. Hier sind einige häufige Szenarien, in denen das Sharding einer Datenbank von Vorteil sein kann:
- Die Menge der Anwendungsdaten übersteigt die Speicherkapazität eines einzelnen Datenbankknotens.
- Das Volumen der Schreib- oder Lesevorgänge in der Datenbank übersteigt das, was ein einzelner Knoten oder seine Lesereplikate bewältigen können, was zu verlangsamten Antwortzeiten oder Timeouts führt.
- Die von der Anwendung benötigte Netzwerkbandbreite übersteigt die Bandbreite, die einem einzelnen Datenbankknoten und den Lesereplikaten zur Verfügung steht, was zu verlangsamten Antwortzeiten oder Timeouts führt.
Bevor Sie Sharding durchführen, sollten Sie alle anderen Möglichkeiten zur Optimierung Ihrer Datenbank ausschöpfen. Einige Optimierungen, die Sie in Betracht ziehen sollten, sind:
- Einrichten einer entfernten Datenbank. Wenn Sie mit einer monolithischen Anwendung arbeiten, bei der sich alle Komponenten auf demselben Server befinden, können Sie die Leistung Ihrer Datenbank verbessern, indem Sie sie auf einen eigenen Rechner verlagern. Dies führt nicht zu so viel Komplexität wie das Sharding, da die Tabellen der Datenbank intakt bleiben. Dennoch können Sie Ihre Datenbank vertikal skalieren, unabhängig vom Rest Ihrer Infrastruktur.
- Implementieren von Caching. Wenn die Leseleistung Ihrer Anwendung Ihnen Probleme bereitet, ist Caching eine Strategie, die helfen kann, diese zu verbessern. Beim Caching werden Daten, die bereits angefordert wurden, im Speicher zwischengespeichert, so dass Sie später viel schneller darauf zugreifen können.
- Erstellen eines oder mehrerer Read-Replicas. Eine weitere Strategie, die zur Verbesserung der Leseleistung beitragen kann, ist das Kopieren der Daten von einem Datenbankserver (dem Primärserver) auf einen oder mehrere Sekundärserver. Anschließend wird jeder neue Schreibzugriff auf den primären Server ausgeführt, bevor er auf die sekundären Server kopiert wird, während die Lesezugriffe ausschließlich auf den sekundären Servern erfolgen. Durch diese Art der Verteilung von Lese- und Schreibvorgängen wird verhindert, dass ein einzelner Rechner zu viel Last aufnimmt, wodurch Verlangsamungen und Abstürze vermieden werden. Beachten Sie, dass die Erstellung von Lesereplikaten mehr Rechenressourcen erfordert und daher mehr Geld kostet, was für einige eine erhebliche Einschränkung darstellen kann.
- Aufrüsten auf einen größeren Server. In den meisten Fällen erfordert das Aufrüsten des eigenen Datenbankservers auf einen Rechner mit mehr Ressourcen weniger Aufwand als das Sharding. Wie beim Anlegen von Read Replicas wird ein aufgerüsteter Server mit mehr Ressourcen wahrscheinlich mehr Geld kosten. Dementsprechend sollten Sie die Größenanpassung nur dann durchführen, wenn sie wirklich die beste Option ist.
Berücksichtigen Sie, dass, wenn Ihre Anwendung oder Website über einen bestimmten Punkt hinaus wächst, keine dieser Strategien ausreicht, um die Leistung allein zu verbessern. In solchen Fällen kann Sharding tatsächlich die beste Option für Sie sein.
Fazit
Sharding kann eine großartige Lösung für diejenigen sein, die ihre Datenbank horizontal skalieren wollen. Es fügt jedoch auch eine große Menge an Komplexität hinzu und schafft mehr potenzielle Fehlerpunkte für Ihre Anwendung. Für einige mag Sharding notwendig sein, aber die Zeit und die Ressourcen, die für die Erstellung und Wartung einer Sharding-Architektur benötigt werden, könnten die Vorteile für andere überwiegen.
Nach der Lektüre dieses konzeptionellen Artikels sollten Sie ein klareres Verständnis für die Vor- und Nachteile von Sharding haben. In Zukunft können Sie diese Erkenntnisse nutzen, um eine fundiertere Entscheidung darüber zu treffen, ob eine Sharded-Datenbankarchitektur für Ihre Anwendung geeignet ist oder nicht.