Wenn Sie noch nicht mit baumbasierten Modellen im maschinellen Lernen vertraut sind, sollten Sie einen Blick auf unseren R-Kurs zu diesem Thema werfen.
Der Random-Forests-Algorithmus
Lassen Sie uns den Algorithmus in Laiensprache verstehen. Nehmen wir an, Sie wollen eine Reise machen und Sie möchten an einen Ort reisen, der Ihnen gefallen wird.
Was tun Sie also, um einen Ort zu finden, der Ihnen gefallen wird? Sie können online suchen, Bewertungen auf Reiseblogs und -portalen lesen, oder Sie können auch Ihre Freunde fragen.
Angenommen, Sie haben sich entschieden, Ihre Freunde zu fragen und mit ihnen über ihre vergangenen Reiseerfahrungen zu verschiedenen Orten zu sprechen. Sie werden von jedem Freund einige Empfehlungen erhalten. Nun müssen Sie eine Liste mit diesen empfohlenen Orten erstellen. Dann bitten Sie sie, aus der Liste der empfohlenen Orte abzustimmen (oder einen besten Ort für die Reise auszuwählen). Der Ort mit den meisten Stimmen wird Ihre endgültige Wahl für die Reise sein.
Der obige Entscheidungsprozess besteht aus zwei Teilen. Erstens: Sie fragen Ihre Freunde nach ihren individuellen Reiseerfahrungen und erhalten eine Empfehlung aus mehreren Orten, die sie besucht haben. Dieser Teil ähnelt der Verwendung des Entscheidungsbaum-Algorithmus. Hier trifft jeder Freund eine Auswahl der Orte, die er oder sie bisher besucht hat.
Der zweite Teil, nachdem alle Empfehlungen gesammelt wurden, ist das Abstimmungsverfahren zur Auswahl des besten Ortes in der Liste der Empfehlungen. Dieser ganze Prozess, Empfehlungen von Freunden zu erhalten und darüber abzustimmen, um den besten Ort zu finden, ist als Random-Forests-Algorithmus bekannt.
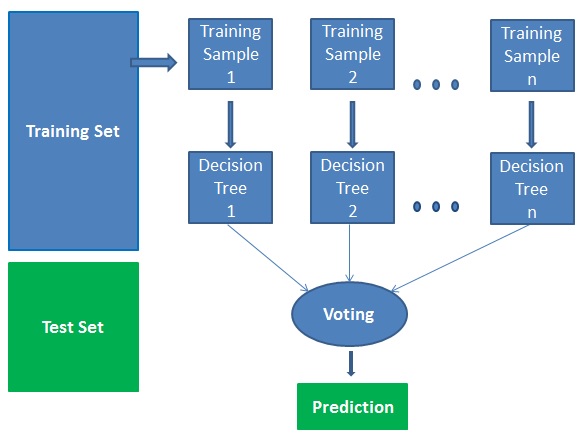
Es handelt sich technisch gesehen um ein Ensemble-Verfahren (basierend auf dem Divide-and-Conquer-Ansatz) von Entscheidungsbäumen, die auf einem zufällig aufgeteilten Datensatz erzeugt werden. Diese Sammlung von Entscheidungsbaum-Klassifikatoren wird auch als Wald bezeichnet. Die einzelnen Entscheidungsbäume werden unter Verwendung eines Attributauswahlindikators wie z. B. Informationsgewinn, Gewinnverhältnis und Gini-Index für jedes Attribut generiert. Jeder Baum hängt von einer unabhängigen Zufallsstichprobe ab. Bei einem Klassifizierungsproblem stimmt jeder Baum ab und die beliebteste Klasse wird als Endergebnis ausgewählt. Im Falle der Regression wird der Durchschnitt aller Baumausgaben als Endergebnis betrachtet. Er ist einfacher und leistungsfähiger als andere nicht-lineare Klassifizierungsalgorithmen.
Wie funktioniert der Algorithmus?
Er arbeitet in vier Schritten:
- Wählen Sie zufällige Stichproben aus einem gegebenen Datensatz.
- Konstruieren Sie einen Entscheidungsbaum für jede Stichprobe und erhalten Sie ein Vorhersageergebnis von jedem Entscheidungsbaum.
- Führen Sie eine Abstimmung für jedes vorhergesagte Ergebnis durch.
- Wählen Sie das Vorhersageergebnis mit den meisten Stimmen als endgültige Vorhersage aus.
Vorteile:
- Random Forests gilt aufgrund der Anzahl der am Prozess beteiligten Entscheidungsbäume als eine sehr genaue und robuste Methode.
- Sie leidet nicht unter dem Overfitting-Problem. Der Hauptgrund dafür ist, dass der Durchschnitt aller Vorhersagen genommen wird, was die Verzerrungen ausgleicht.
- Der Algorithmus kann sowohl bei Klassifizierungs- als auch bei Regressionsproblemen verwendet werden.
- Random Forests können auch mit fehlenden Werten umgehen. Es gibt zwei Möglichkeiten, damit umzugehen: die Verwendung von Medianwerten, um kontinuierliche Variablen zu ersetzen, und die Berechnung des näherungsgewichteten Durchschnitts der fehlenden Werte.
- Sie können die relative Merkmalsbedeutung erhalten, die bei der Auswahl der wichtigsten Merkmale für den Klassifikator hilft.
Nachteile:
- Random Forests ist langsam bei der Erstellung von Vorhersagen, weil es mehrere Entscheidungsbäume hat. Jedes Mal, wenn er eine Vorhersage macht, müssen alle Bäume im Forest eine Vorhersage für dieselbe gegebene Eingabe machen und dann eine Abstimmung darüber durchführen. Dieser ganze Prozess ist zeitaufwändig.
- Das Modell ist schwer zu interpretieren im Vergleich zu einem Entscheidungsbaum, bei dem man einfach eine Entscheidung treffen kann, indem man dem Pfad im Baum folgt.
Finden wichtiger Features
Random Forests bieten auch einen guten Indikator für die Feature-Auswahl. Scikit-learn liefert mit dem Modell eine zusätzliche Variable, die die relative Wichtigkeit oder den Beitrag jedes Merkmals zur Vorhersage anzeigt. Es berechnet automatisch den Relevanzwert jedes Merkmals in der Trainingsphase. Dann skaliert es die Relevanz nach unten, so dass die Summe aller Scores 1 ist.
Dieser Score hilft Ihnen, die wichtigsten Features auszuwählen und die weniger wichtigen für die Modellerstellung zu verwerfen.
Random Forest verwendet die Gini-Bedeutung oder die mittlere Abnahme der Unreinheit (MDI), um die Wichtigkeit der einzelnen Features zu berechnen. Die Gini-Bedeutung ist auch bekannt als die Gesamtabnahme der Knotenverunreinigung. Dies gibt an, wie stark die Modellanpassung oder Genauigkeit abnimmt, wenn Sie eine Variable weglassen. Je größer die Abnahme ist, desto signifikanter ist die Variable. Hier ist die mittlere Abnahme ein wichtiger Parameter für die Variablenauswahl. Der Gini-Index kann die gesamte Erklärungskraft der Variablen beschreiben.
Random Forests vs. Entscheidungsbäume
- Random Forests ist ein Satz von mehreren Entscheidungsbäumen.
- Tiefe Entscheidungsbäume können unter Overfitting leiden, aber Random Forests verhindern Overfitting, indem Bäume auf zufälligen Teilmengen erstellt werden.
- Entscheidungsbäume sind rechnerisch schneller.
- Random Forests sind schwer zu interpretieren, während ein Entscheidungsbaum leicht zu interpretieren ist und in Regeln umgewandelt werden kann.
Erstellen eines Klassifikators mit Scikit-learn
Sie werden ein Modell auf dem Irisblumen-Datensatz erstellen, der ein sehr berühmtes Klassifizierungsset ist. Er umfasst die Länge des Kelchblattes, die Breite des Kelchblattes, die Länge des Blütenblattes, die Breite des Blütenblattes und die Art der Blüte. Es gibt drei Arten oder Klassen: setosa, versicolor und virginia. Sie werden ein Modell erstellen, um die Art der Blüte zu klassifizieren. Der Datensatz ist in der scikit-learn-Bibliothek verfügbar oder kann vom UCI Machine Learning Repository heruntergeladen werden.
Starten Sie mit dem Importieren der Datensatz-Bibliothek von scikit-learn und laden Sie den Iris-Datensatz mit load_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Sie können die Ziel- und Merkmalsnamen ausgeben, um sicherzustellen, dass Sie den richtigen Datensatz haben:
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)Es ist eine gute Idee, Ihre Daten immer ein wenig zu untersuchen, damit Sie wissen, womit Sie arbeiten. Hier sehen Sie, dass die ersten fünf Zeilen des Datensatzes ausgegeben werden, sowie die Zielvariable für den gesamten Datensatz.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Hier können Sie einen DataFrame des Iris-Datensatzes auf folgende Weise erstellen.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| Blattbreite | Spalte Länge | Spalte Breite | Spezies | ||
|---|---|---|---|---|---|
| 0 | 1.4 | 0.2 | 5.1 | 3.5 | 0 |
| 1 | 1.4 | 0.2 | 4.9 | 3.0 | 0 |
| 2 | 1.3 | 0.2 | 4.7 | 3.2 | 0 |
| 3 | 1.5 | 0.2 | 4.6 | 3.1 | 0 |
| 4 | 1.4 | 0.2 | 5.0 | 3.6 | 0 |
Zuerst trennen Sie die Spalten in abhängige und unabhängige Variablen (oder Features und Labels). Dann teilen Sie diese Variablen in einen Trainings- und einen Testsatz auf.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testNach der Aufteilung trainieren Sie das Modell auf dem Trainingssatz und führen Vorhersagen auf dem Testsatz durch.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Nach dem Training überprüfen Sie die Genauigkeit anhand der tatsächlichen und vorhergesagten Werte.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)Sie können auch eine Vorhersage für ein einzelnes Element machen, zum Beispiel:
- Spalte Länge = 3
- Spalte Breite = 5
- Blütenblattlänge = 4
- Blütenblattbreite = 2
Nun können Sie vorhersagen, um welche Art von Blume es sich handelt.
clf.predict(])array()Hier zeigt 2 den Blumentyp Virginica an.
Finden wichtiger Merkmale in Scikit-learn
Hier finden Sie wichtige Merkmale oder wählen Merkmale im IRIS-Datensatz aus. In Scikit-learn können Sie diese Aufgabe in den folgenden Schritten durchführen:
- Erst müssen Sie ein Random-Forests-Modell erstellen.
- Zweitens verwenden Sie die Variable für die Merkmalswichtigkeit, um die Werte für die Merkmalswichtigkeit zu sehen.
- Drittens visualisieren Sie diese Werte mit der seaborn-Bibliothek.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64Sie können die Merkmalsgewichtung auch visualisieren. Die Visualisierungen sind einfach zu verstehen und zu interpretieren.
Für die Visualisierung können Sie eine Kombination aus matplotlib und seaborn verwenden. Da seaborn auf matplotlib aufbaut, bietet es eine Reihe von angepassten Themen und stellt zusätzliche Plot-Typen zur Verfügung. Matplotlib ist eine Obermenge von seaborn und beide sind gleich wichtig für gute Visualisierungen.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()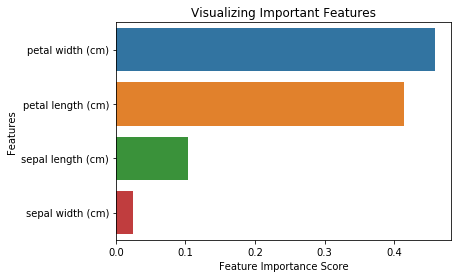
Erzeugen des Modells anhand ausgewählter Merkmale
Hier können Sie das Merkmal „Kelchblattbreite“ entfernen, da es eine sehr geringe Bedeutung hat, und die 3 verbleibenden Merkmale auswählen.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testNach der Aufteilung erzeugen Sie ein Modell auf den ausgewählten Features des Trainingssatzes, führen Vorhersagen auf den ausgewählten Features des Testsatzes durch und vergleichen tatsächliche und vorhergesagte Werte.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Sie können sehen, dass nach dem Entfernen der am wenigsten wichtigen Features (Kelchblattlänge) die Genauigkeit gestiegen ist. Das liegt daran, dass Sie irreführende Daten und Rauschen entfernt haben, was zu einer erhöhten Genauigkeit führt. Eine geringere Anzahl von Features reduziert auch die Trainingszeit.
Abschluss
Glückwunsch, Sie haben es bis zum Ende dieses Tutorials geschafft!
In diesem Tutorial haben Sie gelernt, was Random Forests sind, wie sie funktionieren, wichtige Features zu finden, den Vergleich zwischen Random Forests und Entscheidungsbäumen, Vorteile und Nachteile. Außerdem haben Sie die Modellbildung, die Evaluation und das Finden wichtiger Features in scikit-learn gelernt. B
Wenn Sie mehr über maschinelles Lernen lernen möchten, empfehle ich Ihnen unseren Kurs Supervised Learning in R: Classification course.