Introduction
Toute application ou site web qui connaît une croissance importante devra éventuellement évoluer pour s’adapter à l’augmentation du trafic. Pour les applications et les sites Web axés sur les données, il est essentiel que la mise à l’échelle soit effectuée de manière à garantir la sécurité et l’intégrité de leurs données. Il peut être difficile de prédire la popularité d’un site web ou d’une application ou la durée pendant laquelle il conservera cette popularité, c’est pourquoi certaines organisations choisissent une architecture de base de données qui leur permet de faire évoluer leurs bases de données de manière dynamique.
Dans cet article conceptuel, nous allons aborder une telle architecture de base de données : les bases de données sharded. Le sharding a reçu beaucoup d’attention ces dernières années, mais beaucoup ne comprennent pas bien ce que c’est ou les scénarios dans lesquels il pourrait être judicieux de sharder une base de données. Nous allons passer en revue ce qu’est le sharding, certains de ses principaux avantages et inconvénients, ainsi que quelques méthodes de sharding courantes.
Qu’est-ce que le sharding ?
Le sharding est un modèle d’architecture de base de données lié au partitionnement horizontal – la pratique consistant à séparer les lignes d’une table en plusieurs tables différentes, appelées partitions. Chaque partition possède le même schéma et les mêmes colonnes, mais aussi des lignes entièrement différentes. De même, les données détenues dans chacune d’elles sont uniques et indépendantes des données détenues dans les autres partitions.
Il peut être utile de penser au partitionnement horizontal en fonction de sa relation avec le partitionnement vertical. Dans une table partitionnée verticalement, des colonnes entières sont séparées et placées dans de nouvelles tables distinctes. Les données contenues dans une partition verticale sont indépendantes des données contenues dans toutes les autres, et chacune contient des lignes et des colonnes distinctes. Le schéma suivant illustre comment une table pourrait être partitionnée à la fois horizontalement et verticalement:
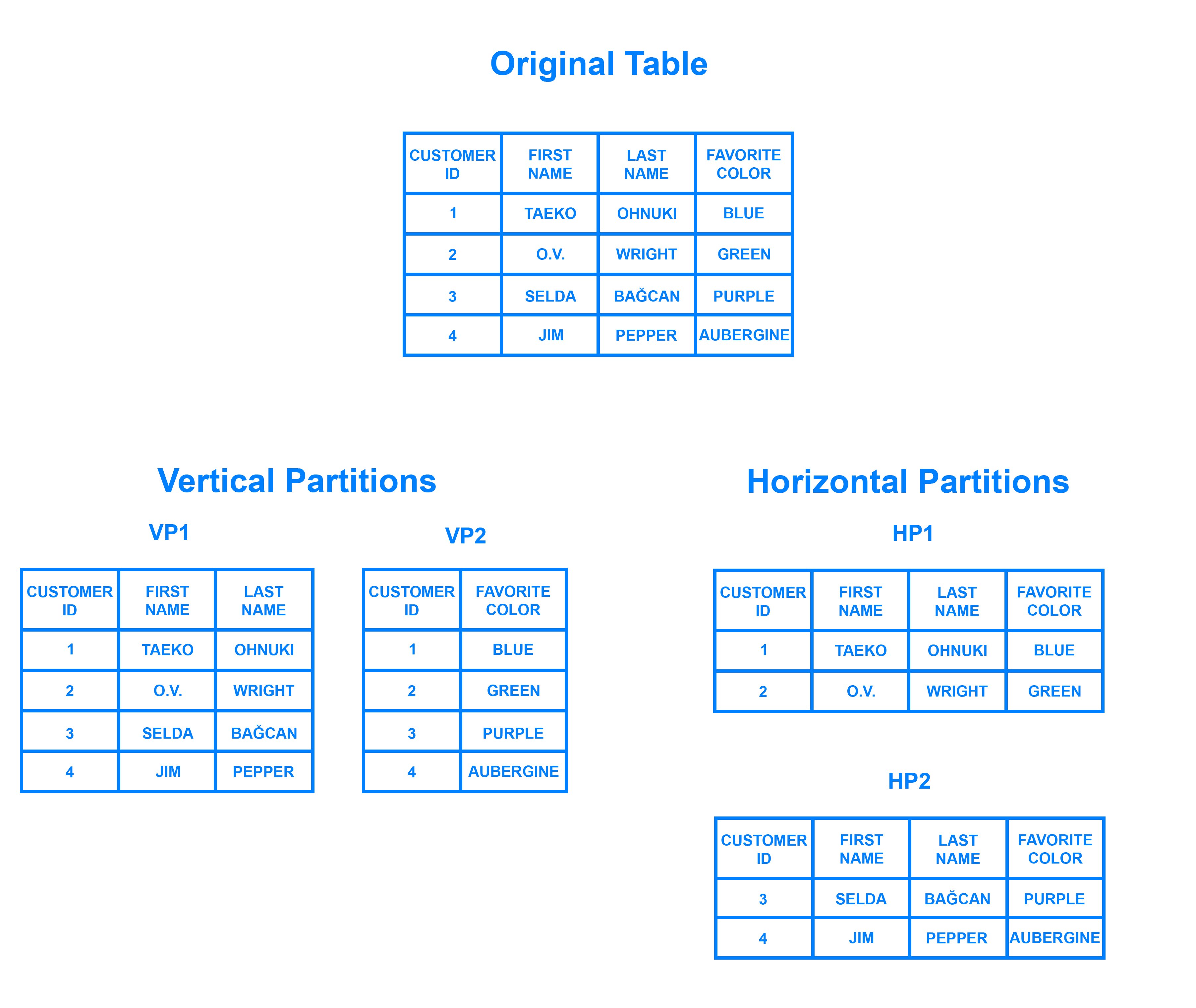
La partition consiste à diviser ses données en deux ou plusieurs petits morceaux, appelés tessons logiques. Les tessons logiques sont ensuite répartis sur des nœuds de base de données distincts, appelés tessons physiques, qui peuvent contenir plusieurs tessons logiques. Malgré cela, les données détenues au sein de tous les shards représentent collectivement un ensemble de données logiques entier.
Les shards de base de données illustrent une architecture sans partage. Cela signifie que les shards sont autonomes ; ils ne partagent aucune des mêmes données ou ressources informatiques. Dans certains cas, cependant, il peut être judicieux de répliquer certaines tables dans chaque shard pour servir de tables de référence. Par exemple, supposons qu’il existe une base de données pour une application qui dépend de taux de conversion fixes pour les mesures de poids. En répliquant une table contenant les données de taux de conversion nécessaires dans chaque shard, cela permettrait de s’assurer que toutes les données requises pour les requêtes sont détenues dans chaque shard.
Souvent, le sharding est mis en œuvre au niveau de l’application, ce qui signifie que l’application inclut le code qui définit à quel shard transmettre les lectures et les écritures. Cependant, certains systèmes de gestion de base de données ont des capacités de sharding intégrées, ce qui vous permet de mettre en œuvre le sharding directement au niveau de la base de données.
Compte tenu de cet aperçu général du sharding, passons en revue certains des points positifs et négatifs associés à cette architecture de base de données.
Avantages du sharding
Le principal attrait du sharding d’une base de données est qu’il peut contribuer à faciliter la mise à l’échelle horizontale, également connue sous le nom de scaling out. La mise à l’échelle horizontale consiste à ajouter des machines supplémentaires à une pile existante afin de répartir la charge et de permettre un trafic plus important et un traitement plus rapide. On l’oppose souvent à la mise à l’échelle verticale, autrement appelée mise à l’échelle ascendante, qui consiste à mettre à niveau le matériel d’un serveur existant, généralement en ajoutant plus de RAM ou de CPU.
Il est relativement simple d’avoir une base de données relationnelle fonctionnant sur une seule machine et de la mettre à l’échelle si nécessaire en mettant à niveau ses ressources informatiques. En fin de compte, cependant, toute base de données non distribuée sera limitée en termes de stockage et de puissance de calcul, donc avoir la liberté d’évoluer horizontalement rend votre configuration beaucoup plus flexible.
Une autre raison pour laquelle certains pourraient choisir une architecture de base de données sharded est d’accélérer les temps de réponse des requêtes. Lorsque vous soumettez une requête sur une base de données qui n’a pas été sharded, il se peut qu’elle doive rechercher chaque ligne de la table que vous interrogez avant de trouver l’ensemble de résultats que vous recherchez. Pour une application comportant une grande base de données monolithique, les requêtes peuvent devenir excessivement lentes. En shardant une table en plusieurs, cependant, les requêtes doivent parcourir moins de lignes et leurs ensembles de résultats sont retournés beaucoup plus rapidement.
Le sharding peut également contribuer à rendre une application plus fiable en atténuant l’impact des pannes. Si votre application ou votre site Web repose sur une base de données non shardée, une panne a le potentiel de rendre toute l’application indisponible. En revanche, avec une base de données sharded, une panne est susceptible de n’affecter qu’un seul shard. Même si cela peut rendre certaines parties de l’application ou du site Web indisponibles pour certains utilisateurs, l’impact global serait toujours moindre que si la base de données entière tombait en panne.
Les inconvénients du sharding
Si le sharding d’une base de données peut faciliter la mise à l’échelle et améliorer les performances, il peut également imposer certaines limites. Ici, nous allons discuter de certaines d’entre elles et pourquoi elles pourraient être des raisons d’éviter complètement le sharding.
La première difficulté que les gens rencontrent avec le sharding est la complexité même de la mise en œuvre correcte d’une architecture de base de données sharded. S’il est mal fait, il y a un risque important que le processus de sharding conduise à des pertes de données ou à des tables corrompues. Cependant, même lorsqu’il est effectué correctement, le sharding est susceptible d’avoir un impact majeur sur les flux de travail de votre équipe. Plutôt que d’accéder à ses données et de les gérer à partir d’un seul point d’entrée, les utilisateurs doivent gérer les données à travers plusieurs emplacements de shard, ce qui pourrait potentiellement être perturbant pour certaines équipes.
Un problème que les utilisateurs rencontrent parfois après avoir shardé une base de données est que les shards finissent par être déséquilibrés. À titre d’exemple, disons que vous avez une base de données avec deux shards distincts, l’un pour les clients dont le nom de famille commence par les lettres A à M et l’autre pour ceux dont le nom commence par les lettres N à Z. Cependant, votre application sert une quantité démesurée de personnes dont le nom de famille commence par la lettre G. En conséquence, le shard A-M accumule progressivement plus de données que le shard N-Z, ce qui entraîne un ralentissement et un blocage de l’application pour une partie importante de vos utilisateurs. Le shard A-M est devenu ce que l’on appelle un hotspot de base de données. Dans ce cas, tous les avantages du partage de la base de données sont annulés par les ralentissements et les pannes. La base de données devrait probablement être réparée et reshardée pour permettre une distribution plus uniforme des données.
Un autre inconvénient majeur est qu’une fois qu’une base de données a été shardée, il peut être très difficile de la ramener à son architecture non shardée. Toute sauvegarde de la base de données effectuée avant qu’elle ne soit sharded n’inclura pas les données écrites depuis le partitionnement. Par conséquent, reconstruire l’architecture originale non sharded nécessiterait de fusionner les nouvelles données partitionnées avec les anciennes sauvegardes ou, alternativement, de retransformer la BD partitionnée en une seule BD, deux entreprises coûteuses et longues à mettre en œuvre.
Un dernier inconvénient à prendre en compte est que le sharding n’est pas nativement supporté par tous les moteurs de base de données. Par exemple, PostgreSQL n’inclut pas le sharding automatique comme fonctionnalité, bien qu’il soit possible de sharder manuellement une base de données PostgreSQL. Il existe un certain nombre de forks Postgres qui incluent le sharding automatique, mais ils sont souvent en retard sur la dernière version de PostgreSQL et ne disposent pas de certaines autres fonctionnalités. Certaines technologies de base de données spécialisées – comme MySQL Cluster ou certains produits de base de données en tant que service comme MongoDB Atlas – incluent le sharding automatique comme fonctionnalité, mais les versions vanilles de ces systèmes de gestion de base de données ne le font pas. Pour cette raison, le sharding nécessite souvent une approche de type « roll your own ». Cela signifie que la documentation sur le sharding ou les conseils pour résoudre les problèmes sont souvent difficiles à trouver.
Ce ne sont, bien sûr, que des questions générales à prendre en compte avant de procéder au sharding. Il peut y avoir beaucoup plus d’inconvénients potentiels au sharding d’une base de données en fonction de son cas d’utilisation.
Maintenant que nous avons couvert quelques inconvénients et avantages du sharding, nous allons passer en revue quelques architectures différentes pour les bases de données shardées.
Architectures de sharding
Une fois que vous avez décidé de sharder votre base de données, la prochaine chose que vous devez déterminer est la façon dont vous allez le faire. Lors de l’exécution de requêtes ou de la distribution de données entrantes vers des tables ou des bases de données shardées, il est crucial qu’elles aillent vers le bon shard. Dans le cas contraire, cela pourrait entraîner la perte de données ou des requêtes terriblement lentes. Dans cette section, nous allons passer en revue quelques architectures de sharding courantes, chacune d’entre elles utilisant un processus légèrement différent pour distribuer les données entre les shards.
Key Based Sharding
Key based sharding, également connu sous le nom de hash based sharding, implique l’utilisation d’une valeur prise dans les données nouvellement écrites – comme le numéro d’identification d’un client, l’adresse IP d’une application client, un code postal, etc. et de la brancher dans une fonction de hachage pour déterminer vers quel shard les données doivent aller. Une fonction de hachage est une fonction qui prend en entrée un élément de données (par exemple, l’adresse électronique d’un client) et produit une valeur discrète, appelée valeur de hachage. Dans le cas du sharding, la valeur de hachage est un shard ID utilisé pour déterminer sur quel shard les données entrantes seront stockées. Dans l’ensemble, le processus se présente comme suit :

Pour garantir que les entrées sont placées dans les bons shards et de manière cohérente, les valeurs entrées dans la fonction de hachage doivent toutes provenir de la même colonne. Cette colonne est connue sous le nom de clé de shard. En termes simples, les clés shard sont similaires aux clés primaires, car ce sont toutes deux des colonnes utilisées pour établir un identifiant unique pour les lignes individuelles. D’une manière générale, une clé shard doit être statique, c’est-à-dire qu’elle ne doit pas contenir de valeurs susceptibles de changer au fil du temps. Sinon, cela augmenterait la quantité de travail qui entre dans les opérations de mise à jour, et pourrait ralentir les performances.
Bien que le sharding basé sur les clés soit une architecture de sharding assez courante, il peut rendre les choses délicates lorsque vous essayez d’ajouter ou de supprimer dynamiquement des serveurs supplémentaires à une base de données. Lorsque vous ajoutez des serveurs, chacun d’entre eux aura besoin d’une valeur de hachage correspondante et beaucoup de vos entrées existantes, si ce n’est toutes, devront être remappées à leur nouvelle valeur de hachage correcte, puis migrées vers le serveur approprié. Lorsque vous commencerez à rééquilibrer les données, ni les nouvelles ni les anciennes fonctions de hachage ne seront valides. Par conséquent, votre serveur ne sera pas en mesure d’écrire de nouvelles données pendant la migration et votre application pourrait être soumise à des temps d’arrêt.
Le principal attrait de cette stratégie est qu’elle peut être utilisée pour distribuer uniformément les données afin d’éviter les points chauds. De plus, comme elle distribue les données de manière algorithmique, il n’est pas nécessaire de maintenir une carte de l’emplacement de toutes les données, comme c’est le cas avec d’autres stratégies comme le sharding basé sur les plages ou les répertoires.
Range Based Sharding
Le sharding basé sur les plages implique le sharding des données en fonction des plages d’une valeur donnée. Pour illustrer, disons que vous avez une base de données qui stocke des informations sur tous les produits du catalogue d’un détaillant. Vous pourriez créer quelques shards différents et diviser les informations de chaque produit en fonction de la fourchette de prix dans laquelle il se trouve, comme ceci:

Le principal avantage du sharding basé sur la fourchette est qu’il est relativement simple à mettre en œuvre. Chaque shard contient un ensemble de données différent, mais ils ont tous un schéma identique les uns aux autres, ainsi que la base de données d’origine. Le code de l’application lit simplement dans quelle plage se trouvent les données et les écrit dans le shard correspondant.
En revanche, le sharding basé sur les plages ne protège pas les données d’une distribution inégale, ce qui conduit aux points chauds de la base de données mentionnés plus haut. Si l’on regarde le diagramme de l’exemple, même si chaque shard contient une quantité égale de données, il y a de fortes chances pour que des produits spécifiques reçoivent plus d’attention que d’autres. Leurs shards respectifs recevront, à leur tour, un nombre disproportionné de lectures.
Directory Based Sharding
Pour mettre en œuvre le sharding basé sur le répertoire, il faut créer et maintenir une table de consultation qui utilise une clé de shard pour garder la trace de quel shard détient quelles données. En un mot, une table de consultation est une table qui contient un ensemble statique d’informations sur l’endroit où des données spécifiques peuvent être trouvées. Le diagramme suivant montre un exemple simpliste de sharding basé sur un répertoire:
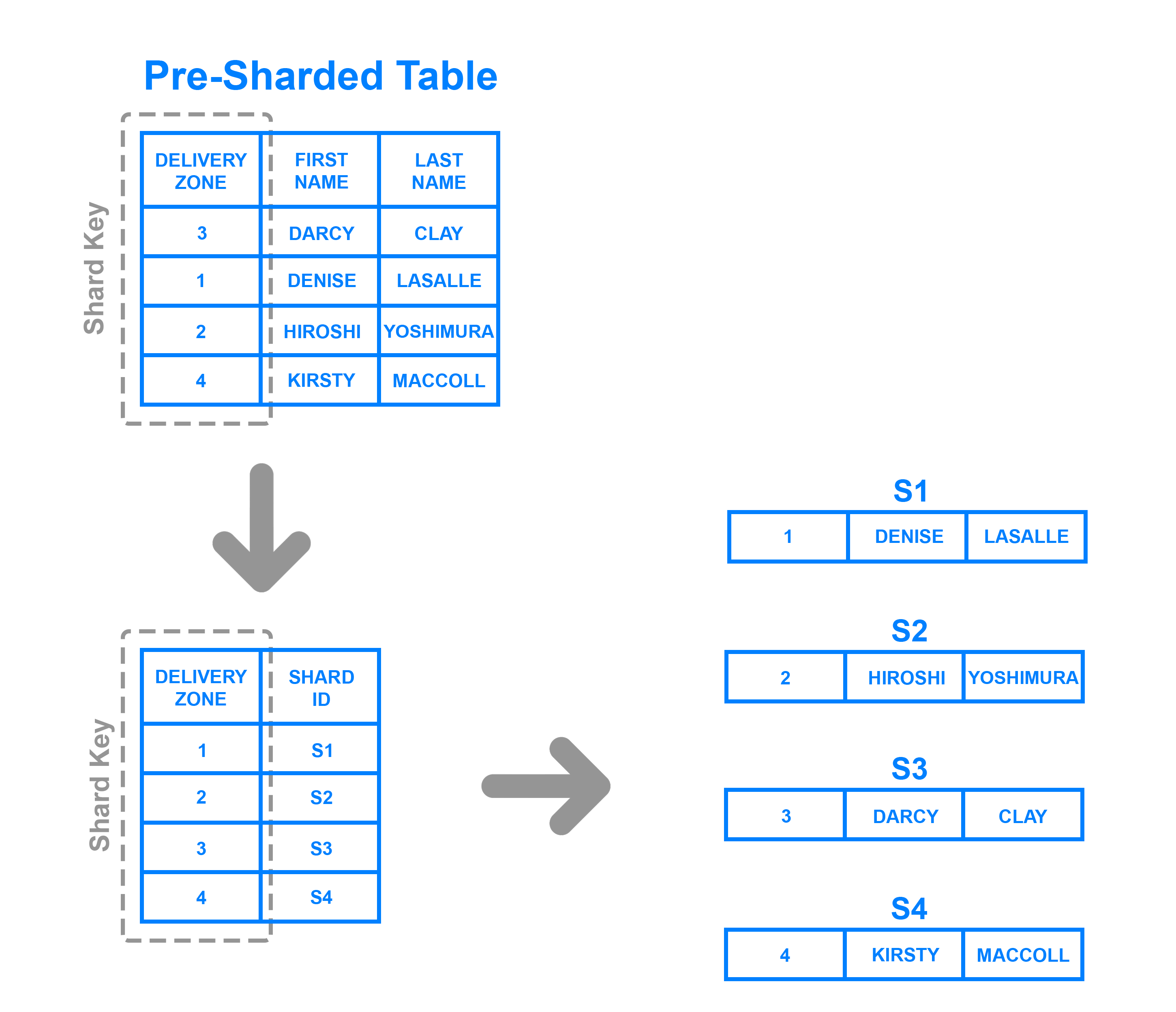
Ici, la colonne Zone de livraison est définie comme une clé de shard. Les données de la clé de shard sont écrites dans la table de consultation avec le shard dans lequel chaque ligne respective doit être écrite. Cette méthode est similaire au sharding basé sur la plage, mais au lieu de déterminer la plage dans laquelle se trouvent les données de la clé shard, chaque clé est liée à son propre shard spécifique. Le sharding basé sur le répertoire est un bon choix par rapport au sharding basé sur la plage dans les cas où la clé du shard a une faible cardinalité et où il n’est pas logique qu’un shard stocke une plage de clés. Notez qu’il se distingue également du key based sharding en ce sens qu’il ne traite pas la clé de shard par le biais d’une fonction de hachage ; il vérifie simplement la clé par rapport à une table de consultation pour savoir où les données doivent être écrites.
Le principal attrait du directory based sharding est sa flexibilité. Les architectures de sharding basées sur les plages vous limitent à spécifier des plages de valeurs, tandis que celles basées sur les clés vous limitent à l’utilisation d’une fonction de hachage fixe qui, comme mentionné précédemment, peut être excessivement difficile à modifier par la suite. Le sharding basé sur les répertoires, en revanche, vous permet d’utiliser le système ou l’algorithme que vous voulez pour affecter les entrées de données aux shards, et il est relativement facile d’ajouter dynamiquement des shards en utilisant cette approche.
Bien que le sharding basé sur les répertoires soit la plus flexible des méthodes de sharding abordées ici, la nécessité de se connecter à la table de consultation avant chaque requête ou écriture peut avoir un impact négatif sur les performances d’une application. En outre, la table de consultation peut devenir un point de défaillance unique : si elle est corrompue ou tombe en panne d’une autre manière, cela peut avoir un impact sur la capacité d’une personne à écrire de nouvelles données ou à accéder à ses données existantes.
Dois-je sharder ?
La mise en œuvre ou non d’une architecture de base de données sharded est presque toujours un sujet de débat. Certains considèrent le sharding comme un résultat inévitable pour les bases de données qui atteignent une certaine taille, tandis que d’autres le considèrent comme un casse-tête qu’il faut éviter sauf si c’est absolument nécessaire, en raison de la complexité opérationnelle que le sharding ajoute.
En raison de cette complexité supplémentaire, le sharding n’est généralement effectué que lorsqu’on traite de très grandes quantités de données. Voici quelques scénarios courants où il peut être bénéfique de sharder une base de données :
- La quantité de données d’application augmente au point de dépasser la capacité de stockage d’un seul nœud de base de données.
- Le volume d’écritures ou de lectures dans la base de données dépasse ce qu’un seul nœud ou ses répliques de lecture peuvent gérer, ce qui entraîne un ralentissement des temps de réponse ou des délais d’attente.
- La bande passante réseau requise par l’application dépasse la bande passante disponible pour un seul nœud de base de données et ses éventuelles répliques de lecture, ce qui entraîne un ralentissement des temps de réponse ou des délais d’attente.
Avant de procéder au sharding, vous devez épuiser toutes les autres options d’optimisation de votre base de données. Voici quelques optimisations que vous pourriez envisager :
- Configuration d’une base de données distante. Si vous travaillez avec une application monolithique dans laquelle tous ses composants résident sur le même serveur, vous pouvez améliorer les performances de votre base de données en la déplaçant sur sa propre machine. Cela n’ajoute pas autant de complexité que le sharding, puisque les tables de la base de données restent intactes. Cependant, cela vous permet toujours de faire évoluer verticalement votre base de données à l’écart du reste de votre infrastructure.
- Mise en œuvre de la mise en cache. Si les performances de lecture de votre application sont ce qui vous pose problème, la mise en cache est une stratégie qui peut aider à les améliorer. La mise en cache consiste à stocker temporairement en mémoire des données qui ont déjà été demandées, ce qui vous permet d’y accéder beaucoup plus rapidement par la suite.
- Créer une ou plusieurs répliques de lecture. Une autre stratégie qui peut aider à améliorer les performances de lecture, cela consiste à copier les données d’un serveur de base de données (le serveur primaire) sur un ou plusieurs serveurs secondaires. Ensuite, chaque nouvelle écriture est effectuée sur le serveur primaire avant d’être copiée sur les serveurs secondaires, tandis que les lectures sont effectuées exclusivement sur les serveurs secondaires. En répartissant les lectures et les écritures de cette manière, on évite qu’une seule machine ne prenne une trop grande part de la charge, ce qui permet d’éviter les ralentissements et les pannes. Notez que la création de répliques de lecture implique plus de ressources informatiques et coûte donc plus cher, ce qui pourrait être une contrainte importante pour certains.
- Mise à niveau vers un serveur plus grand. Dans la plupart des cas, la mise à l’échelle de son serveur de base de données vers une machine disposant de plus de ressources nécessite moins d’efforts que le sharding. Comme pour la création de répliques de lecture, un serveur mis à niveau avec plus de ressources coûtera probablement plus cher. En conséquence, vous ne devriez aller jusqu’au bout du redimensionnement que si cela finit vraiment par être votre meilleure option.
Ne perdez pas de vue que si votre application ou votre site Web se développe au-delà d’un certain point, aucune de ces stratégies ne suffira à améliorer les performances à elle seule. Dans ce cas, le sharding peut effectivement être la meilleure option pour vous.
Conclusion
Le sharding peut être une excellente solution pour ceux qui cherchent à faire évoluer leur base de données horizontalement. Cependant, il ajoute également beaucoup de complexité et crée plus de points de défaillance potentiels pour votre application. Le sharding peut être nécessaire pour certains, mais le temps et les ressources nécessaires pour créer et maintenir une architecture sharded pourraient l’emporter sur les avantages pour d’autres.
En lisant cet article conceptuel, vous devriez avoir une compréhension plus claire des avantages et des inconvénients du sharding. En allant de l’avant, vous pouvez utiliser cet aperçu pour prendre une décision plus éclairée sur la question de savoir si une architecture de base de données sharded convient ou non à votre application.
Les avantages de l’architecture sharded sont nombreux.