Si vous n’êtes pas encore familier avec les modèles basés sur les arbres en apprentissage automatique, vous devriez jeter un coup d’œil à notre cours R sur le sujet.
L’algorithme Random Forests
Comprenons l’algorithme en termes simples. Supposons que vous voulez partir en voyage et que vous aimeriez vous rendre dans un endroit qui vous plaira.
Alors, que faites-vous pour trouver un endroit qui vous plaira ? Vous pouvez faire des recherches en ligne, lire des avis sur des blogs et des portails de voyage, ou vous pouvez aussi demander à vos amis.
Supposons que vous ayez décidé de demander à vos amis, et que vous ayez parlé avec eux de leurs expériences de voyage passées dans divers endroits. Vous obtiendrez quelques recommandations de chaque ami. Maintenant, vous devez faire une liste de ces endroits recommandés. Ensuite, vous leur demandez de voter (ou de sélectionner le meilleur endroit pour le voyage) à partir de la liste des endroits recommandés que vous avez établie. Le lieu ayant reçu le plus grand nombre de votes sera votre choix final pour le voyage.
Dans le processus de décision ci-dessus, il y a deux parties. Tout d’abord, demander à vos amis leur expérience de voyage individuelle et obtenir une recommandation parmi les multiples endroits qu’ils ont visités. Cette partie revient à utiliser l’algorithme de l’arbre de décision. Ici, chaque ami fait une sélection des endroits qu’il a visités jusqu’à présent.
La deuxième partie, après avoir collecté toutes les recommandations, est la procédure de vote pour sélectionner le meilleur endroit dans la liste des recommandations. Tout ce processus consistant à obtenir des recommandations d’amis et à voter pour trouver le meilleur endroit est connu sous le nom d’algorithme des forêts aléatoires.
Il s’agit techniquement d’une méthode d’ensemble (basée sur l’approche diviser pour mieux régner) d’arbres de décision générés sur un ensemble de données divisées au hasard. Cet ensemble d’arbres décisionnels classificateurs est également connu sous le nom de forêt. Les arbres de décision individuels sont générés à l’aide d’un indicateur de sélection d’attribut tel que le gain d’information, le ratio de gain et l’indice de Gini pour chaque attribut. Chaque arbre dépend d’un échantillon aléatoire indépendant. Dans un problème de classification, chaque arbre vote et la classe la plus populaire est choisie comme résultat final. Dans le cas de la régression, la moyenne de toutes les sorties des arbres est considérée comme le résultat final. Il est plus simple et plus puissant par rapport aux autres algorithmes de classification non linéaires.
Comment fonctionne l’algorithme ?
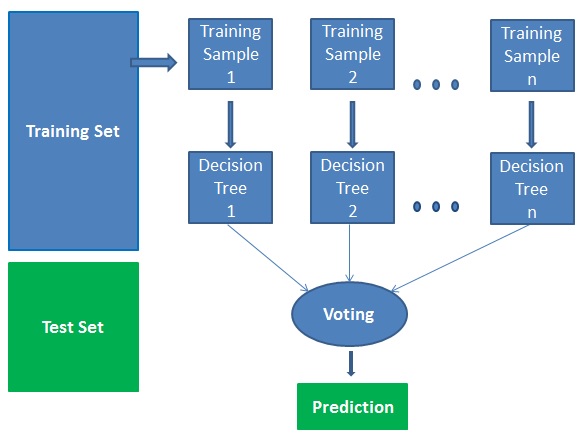
Il fonctionne en quatre étapes :
- Sélectionner des échantillons aléatoires à partir d’un ensemble de données donné.
- Construire un arbre de décision pour chaque échantillon et obtenir un résultat de prédiction de chaque arbre de décision.
- Réaliser un vote pour chaque résultat prédit.
- Sélectionner le résultat de prédiction avec le plus de votes comme prédiction finale.
Avantages:
- Les forêts aléatoires sont considérées comme une méthode très précise et robuste en raison du nombre d’arbres de décision participant au processus.
- Elle ne souffre pas du problème de surajustement. La raison principale est qu’il prend la moyenne de toutes les prédictions, ce qui annule les biais.
- L’algorithme peut être utilisé dans les problèmes de classification et de régression.
- Les forêts aléatoires peuvent également traiter les valeurs manquantes. Il existe deux façons de les traiter : l’utilisation de valeurs médianes pour remplacer les variables continues et le calcul de la moyenne pondérée par la proximité des valeurs manquantes.
- Vous pouvez obtenir l’importance relative des caractéristiques, ce qui aide à sélectionner les caractéristiques les plus contributives pour le classificateur.
Inconvénients:
- Les forêts aléatoires sont lentes à générer des prédictions parce qu’elles comportent plusieurs arbres de décision. Chaque fois qu’il fait une prédiction, tous les arbres de la forêt doivent faire une prédiction pour la même entrée donnée et ensuite effectuer un vote sur celle-ci. L’ensemble de ce processus prend du temps.
- Le modèle est difficile à interpréter par rapport à un arbre de décision, où vous pouvez facilement prendre une décision en suivant le chemin dans l’arbre.
Formations importantes
Les forêts aléatoires offrent également un bon indicateur de sélection des fonctionnalités. Scikit-learn fournit une variable supplémentaire avec le modèle, qui indique l’importance ou la contribution relative de chaque caractéristique dans la prédiction. Il calcule automatiquement le score de pertinence de chaque caractéristique dans la phase de formation. Ensuite, il met la pertinence à l’échelle de sorte que la somme de tous les scores soit égale à 1.
Ce score vous aidera à choisir les caractéristiques les plus importantes et à laisser tomber les moins importantes pour la construction du modèle.
La forêt aléatoire utilise l’importance de Gini ou la diminution moyenne de l’impureté (MDI) pour calculer l’importance de chaque caractéristique. L’importance de Gini est également connue comme la diminution totale de l’impureté des nœuds. Il s’agit de la mesure dans laquelle l’ajustement ou la précision du modèle diminue lorsque vous laissez tomber une variable. Plus la diminution est importante, plus la variable est significative. Ici, la diminution moyenne est un paramètre important pour la sélection des variables. L’indice de Gini peut décrire le pouvoir explicatif global des variables.
Forêts aléatoires vs arbres de décision
- Les forêts aléatoires sont un ensemble de multiples arbres de décision.
- Les arbres de décision profonds peuvent souffrir de surajustement, mais les forêts aléatoires empêchent le surajustement en créant des arbres sur des sous-ensembles aléatoires.
- Les arbres de décision sont plus rapides en termes de calcul.
- Les forêts aléatoires sont difficiles à interpréter, alors qu’un arbre de décision est facilement interprétable et peut être converti en règles.
Construire un classificateur à l’aide de Scikit-learn
Vous allez construire un modèle sur le jeu de données de fleurs d’iris, qui est un jeu de classification très célèbre. Il comprend la longueur du sépale, la largeur du sépale, la longueur du pétale, la largeur du pétale et le type de fleurs. Il y a trois espèces ou classes : setosa, versicolor et virginia. Vous allez construire un modèle pour classifier le type de fleur. Le jeu de données est disponible dans la bibliothèque scikit-learn ou vous pouvez le télécharger à partir du Machine Learning Repository de l’UCI.
Débutez en important la bibliothèque de jeux de données de scikit-learn, et chargez le jeu de données iris avec load_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Vous pouvez imprimer les noms de la cible et des caractéristiques, pour vous assurer que vous avez le bon ensemble de données, comme tel :
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)C’est une bonne idée de toujours explorer un peu vos données, pour savoir avec quoi vous travaillez. Ici, vous pouvez voir que les cinq premières lignes du jeu de données sont imprimées, ainsi que la variable cible pour l’ensemble du jeu de données.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Ici, vous pouvez créer un DataFrame du jeu de données de l’iris de la manière suivante.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| longueur du pétale | La largeur du pétale | La longueur du sépale | La largeur du sépale | L’espèce | |
|---|---|---|---|---|---|
| 0 | 1.4 | 0,2 | 5,1 | 3,5 | 0 | 1 | 1,4 | 0,2 | 4,9 | 3.0 | 0 |
| 2 | 1,3 | 0,2 | 4,7 | 3,2 | 0 | 3 | 1,5 | 0,2 | 4.6 | 3,1 | 0 |
| 4 | 1,4 | 0,2 | 5,0 | 3.6 | 0 |
D’abord, vous séparez les colonnes en variables dépendantes et indépendantes (ou caractéristiques et étiquettes). Puis vous divisez ces variables en un ensemble d’entraînement et un ensemble de test.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testAprès la division, vous entraînerez le modèle sur l’ensemble d’entraînement et effectuerez des prédictions sur l’ensemble de test.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Après l’entraînement, vérifiez la précision en utilisant les valeurs réelles et prédites.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)Vous pouvez également faire une prédiction pour un seul élément, par exemple :
- Longueur du sépale = 3
- Largeur du sépale = 5
- Longueur du pétale = 4
- Largeur du pétale = 2
Maintenant, vous pouvez prédire de quel type de fleur il s’agit.
clf.predict(])array()Ici, 2 indique le type de fleur Virginica.
Finding Important Features in Scikit-learn
Ici, vous recherchez des caractéristiques importantes ou sélectionnez des caractéristiques dans le jeu de données IRIS. Dans scikit-learn, vous pouvez effectuer cette tâche en suivant les étapes suivantes :
- Premièrement, vous devez créer un modèle de forêts aléatoires.
- Deuxièmement, utilisez la variable d’importance des caractéristiques pour voir les scores d’importance des caractéristiques.
- Troisièmement, visualisez ces scores en utilisant la bibliothèque seaborn.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64Vous pouvez également visualiser l’importance des caractéristiques. Les visualisations sont faciles à comprendre et à interpréter.
Pour la visualisation, vous pouvez utiliser une combinaison de matplotlib et de seaborn. Comme seaborn est construit au-dessus de matplotlib, il offre un certain nombre de thèmes personnalisés et fournit des types de tracés supplémentaires. Matplotlib est un sur-ensemble de seaborn et les deux sont aussi importants l’un que l’autre pour de bonnes visualisations.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()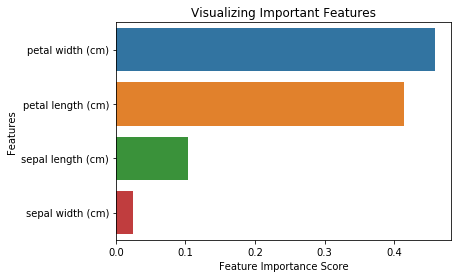
Générer le modèle sur les caractéristiques sélectionnées
Ici, vous pouvez supprimer la caractéristique « largeur du sépale » car elle a une très faible importance, et sélectionner les 3 caractéristiques restantes.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testAprès le fractionnement, vous allez générer un modèle sur les caractéristiques sélectionnées de l’ensemble d’entraînement, effectuer des prédictions sur les caractéristiques sélectionnées de l’ensemble de test, et comparer les valeurs réelles et prédites.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Vous pouvez voir qu’après avoir supprimé les caractéristiques les moins importantes (longueur des sépales), la précision a augmenté. Cela est dû au fait que vous avez supprimé les données trompeuses et le bruit, ce qui a entraîné une augmentation de la précision. Une quantité moindre de caractéristiques réduit également le temps de formation.
Conclusion
Félicitations, vous êtes arrivé à la fin de ce tutoriel !
Dans ce tutoriel, vous avez appris ce que sont les forêts aléatoires, comment elles fonctionnent, comment trouver des caractéristiques importantes, la comparaison entre les forêts aléatoires et les arbres de décision, les avantages et les inconvénients. Vous avez également appris la construction de modèles, l’évaluation et la recherche de caractéristiques importantes dans scikit-learn. B
Si vous souhaitez en savoir plus sur l’apprentissage automatique, je vous recommande de jeter un coup d’œil à notre apprentissage supervisé en R : Cours de classification.