Votre table peut contenir des valeurs en double dans une colonne et dans certains scénarios, vous pouvez avoir besoin de récupérer uniquement des enregistrements uniques de la table.
Pour supprimer les enregistrements en double pour les données récupérées avec l’instruction SELECT, vous pouvez utiliser la clause DISTINCT comme indiqué dans les exemples ci-dessous.
Une démo de SELECT simple – DISTINCT
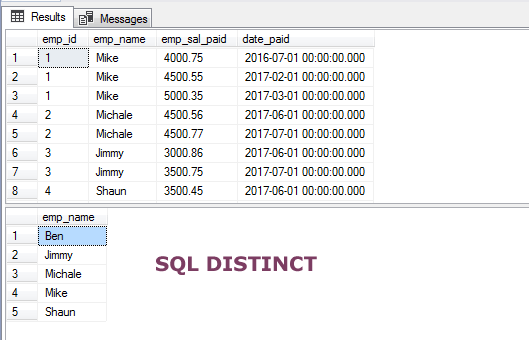
Dans le premier exemple, j’ai utilisé la clause DISTINCT avec l’instruction SELECT pour récupérer uniquement les noms uniques de notre table de démonstration, sto_emp_salary_paid. Cette table stocke les salaires des employés avec leurs noms. Donc, l’occurrence en double des noms des employés se produit dans la table.
En utilisant la clause DISTINCT, nous obtenons uniquement les noms uniques des employés :
Query :
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid ;
(S’applique aux bases de données SQL Server et MySQL)
Utilisation de la clause WHERE avec DISTINCT
Dans cet exemple, j’ai utilisé la clause WHERE avec l’instruction SELECT/DISTINCT pour récupérer uniquement les employés uniques auxquels le salaire payé est supérieur ou égal à 4500. Voir la requête et le jeu de résultats:
La requête :
|
1
. 2
. 3
|
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
WHERE emp_sal_paid >= 4500 ;
|

L’exemple de la fonction COUNT avec DISTINCT
Vous pouvez également utiliser la fonction SQL COUNT pour obtenir le nombre d’enregistrements comme en utilisant la clause DISTINCT. La fonction renvoie uniquement le compte pour les lignes retournées après la clause DISTINCT.
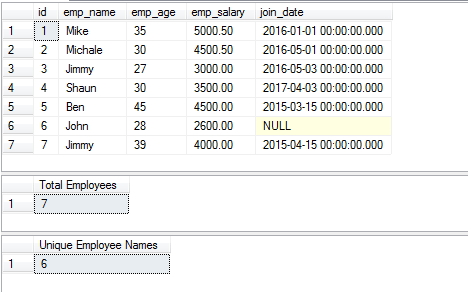
Pour la démo, j’utilise la table employee qui stocke les informations sur les employés. Trois requêtes sont utilisées dans la démo comme suit :
- La première requête renvoie l’enregistrement complet de la table
- La deuxième requête obtient le nombre d’employés en utilisant l’ID (COUNT et DISTINCT)
- Tandis que la troisième renvoie les noms uniques des employés en utilisant la colonne emp_name.
Les trois requêtes sont :
|
1
2
. 3
4
5
6
7
|
SELECT * FROM sto_employees ;
Select COUNT(DISTINCT id) AS « Total des employés » FROM sto_employees
Select COUNT(DISTINCT emp_name) AS « Noms uniques des employés » FROM sto_employees
|
. 
La clause DISTINCT avec exemple GROUP BY
La requête suivante récupère les enregistrements de la même table que celle utilisée dans les exemples ci-dessus et regroupe les employés payés en salaires. Pour cela, les clauses GROUP BY et DISTINCT sont utilisées comme suit :
La requête :
|
1
2
3
|
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As « Total Paid » FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id ;
|
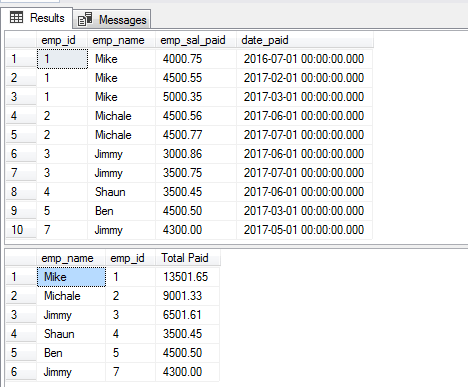
L’enregistrement pour le « Jimmy » apparaît deux fois car il a deux ID différents.
Utilisation de la clause HAVING avec DISTINCT
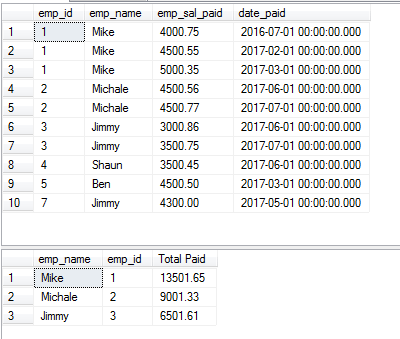
Comme pour l’utilisation de la clause GROUP BY avec DISTINCT, vous pouvez également ajouter la clause HAVING pour récupérer les enregistrements. Dans la requête suivante, la clause HAVING est ajoutée dans l’exemple ci-dessus et nous allons récupérer les enregistrements dont le SUM est supérieur à 5000.
La requête :
|
1
2
3
4
5
. |
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As « Total Paid » FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id
HAVING SUM(emp_sal_paid) > 5000 ;
|
La clause DISTINCT avec ORDER BY exemple
La clause SQL ORDER BY peut être utilisée avec la clause DISTINCT pour trier les résultats après avoir supprimé les valeurs en double. Voir la requête et le résultat ci-dessous :
|
1
2
3
|
Select DISTINCT(emp_name) FROM sto_emp_salary_paid
Order BY emp_name ;
|
Le résultat :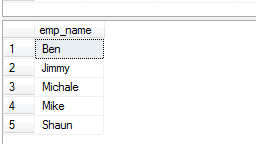
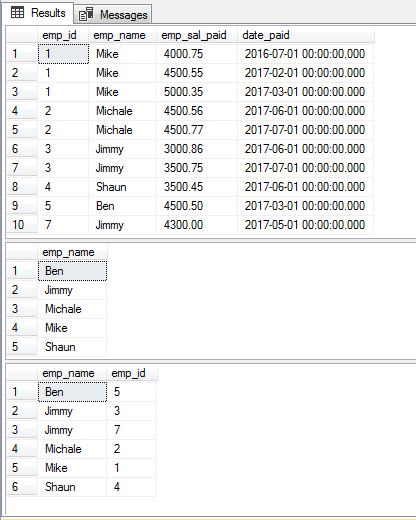
Utilisation de plusieurs colonnes dans la clause DISTINCT
Vous pouvez également spécifier deux colonnes ou plus comme en utilisant la clause SELECT – DISTINCT. En tant que tel, notre tableau d’exemple contient des valeurs en double pour les employés et leurs ID, il sera donc bon d’apprendre à voir comment la clause DISTINCT renvoie les enregistrements comme utilisant ces deux colonnes dans la requête unique.
Pour voir la différence, j’ai d’abord écrit une requête avec DISTINCT (emp_name) qui est suivie par l’utilisation des deux colonnes :
La requête :
|
1
2
3
4
5
6
7
8
9
|
Select DISTINCT emp_name FROM sto_emp_salary_paid
ORDER BY emp_name ;
Select DISTINCT emp_name,emp_id FROM sto_emp_salary_paid
Order par emp_name ;
|
Les résultats pour les requêtes table complète, DISTINCT emp_name et DISTINCT emp_name,emp_id :
.