Nous avons quelques fichiers personnalisés que nous recevons de différents fournisseurs et pour ces situations, nous ne pouvons pas utiliser les programmes ETL standard sans aucune personnalisation. Comme nous étendons notre capacité à lire ces fichiers personnalisés avec .NET, nous recherchons des moyens efficaces de lire les fichiers avec PowerShell que nous pouvons utiliser dans les agents de travail SQL Server, les planificateurs de tâches Windows ou avec notre programme personnalisé, qui peut exécuter des scripts PowerShell. Nous disposons de nombreux outils d’analyse syntaxique des données et nous voulions connaître les moyens efficaces de lire les données pour l’analyse syntaxique, ainsi que d’obtenir des lignes spécifiques de données à partir de fichiers par numéro, ou par la première ou la dernière ligne du fichier. Pour lire efficacement les fichiers, quelles sont les fonctions ou les bibliothèques que nous pouvons utiliser ?
Aperçu
Pour lire les données des fichiers, nous voulons généralement nous concentrer sur trois fonctions principales pour accomplir ces tâches, ainsi que quelques exemples listés à côté de celles-ci dans la pratique :
- Comment lire un fichier entier, une partie d’un fichier ou sauter dans un fichier. Nous pouvons être confrontés à une situation où nous voulons lire chaque ligne sauf la première et la dernière.
- Comment lire un fichier en utilisant peu de ressources système. Nous pouvons avoir un fichier de 100 Go que nous ne voulons lire que pour 108 Ko de données.
- Comment lire un fichier d’une manière qui nous permet facilement d’analyser les données dont nous avons besoin ou qui nous permet d’utiliser des fonctions ou des outils que nous utilisons avec d’autres données. Étant donné que de nombreux développeurs disposent d’outils d’analyse syntaxique des chaînes de caractères, le déplacement des données vers un format de chaîne de caractères – si possible – nous permet de réutiliser de nombreux outils d’analyse syntaxique des chaînes de caractères.
Ce qui précède s’applique à la plupart des situations impliquées dans l’analyse syntaxique des données à partir de fichiers. Nous commencerons par examiner une fonction PowerShell intégrée pour lire des données, puis nous examinerons une façon personnalisée de lire des données à partir de fichiers à l’aide de PowerShell.
La fonction Get-Content de PowerShell
La dernière version de PowerShell (version 5) et de nombreuses versions antérieures de PowerShell sont fournies avec la fonction Get-Content et cette fonction nous permet de lire rapidement les données d’un fichier. Dans le script ci-dessous, nous sortons les données d’un fichier entier sur l’écran PowerShell ISE – un écran que nous utiliserons à des fins de démonstration tout au long de cet article :
|
….
1
|
Get-Content « C :\logging.txt »
|
Nous pouvons enregistrer toute cette quantité de données dans une chaîne, appelée ourfilesdata :
|
1
2
.. |
$nosfilesdata = Get-Content « C :\logging.txt »
$nosfilesdata
|
Nous obtenons le même résultat que ci-dessus, la seule différence ici est que nous avons enregistré le fichier entier dans une variable. Nous faisons face à un inconvénient cependant, si nous enregistrons un fichier entier dans une variable ou si nous sortons un fichier entier : si la taille du fichier est grande, nous devrons lire le fichier entier dans la variable ou sortir le fichier entier sur l’écran. Cela commence à nous coûter des performances, car nous traitons des tailles de fichiers plus importantes.
Nous pouvons sélectionner une partie du fichier en traitant notre variable (objet étant un autre nom) comme une requête SQL où nous sélectionnons une partie des fichiers au lieu de la totalité. Dans le code ci-dessous, nous sélectionnons les cinq premières lignes du fichier, plutôt que le fichier entier :
|
1
2
|
$nosfilesdata = Get-Content « C :\logging.txt »
$nosfilesdata | Select-Object -First 5
|
Nous pouvons également utiliser la même fonction pour obtenir les cinq dernières lignes du fichier, en utilisant une syntaxe similaire :
|
1
2
|
$nosfilesdata = Get-Content « C :\logging.txt »
$nosfilesdata | Select-Object -Last 5
|
La fonction Get-Content intégrée de PowerShell peut être utile, mais si nous voulons stocker très peu de données à chaque lecture pour des raisons d’analyse syntaxique, ou si nous voulons lire ligne par ligne pour analyser un fichier, nous pouvons utiliser la classe StreamReader de .NET, qui nous permettra de personnaliser notre utilisation pour une efficacité accrue. Cela fait de Get-Content un excellent lecteur de base pour les données de fichiers.
La bibliothèque StreamReader
Dans une nouvelle fenêtre PowerShell ISE, nous allons créer un objet StreamReader et disposer de ce même objet en exécutant le code PowerShell ci-dessous :
|
1
2
3
|
$newstreamreader = New-Objet System.IO.StreamReader(« C:\logging\logging.txt »)
#### Lecture du fichier ici
$newstreamreader.Dispose()
|
En général, chaque fois que nous créons un nouvel objet, c’est une bonne pratique de supprimer cet objet, car cela libère les ressources informatiques sur cet objet. S’il est vrai que .NET le fera automatiquement, je recommande toujours de le faire manuellement, car vous pourriez travailler avec des langages qui ne le font pas automatiquement à l’avenir et c’est une bonne pratique.
Il ne se passe rien lorsque nous exécutons le code ci-dessus car nous n’avons appelé aucune méthode – nous avons seulement créé un objet et l’avons supprimé. La première méthode que nous allons examiner est la méthode ReadToEnd() :
|
1
2
3
|
$newstreamreader = New-Objet System.IO.StreamReader(« C:\logging.txt »)
$newstreamreader.ReadToEnd()
$newstreamreader.Dispose()
|
Comme nous le voyons dans la sortie, nous pouvons lire toutes les données du fichier comme avec Get-Content en utilisant la méthode ReadToEnd() ; comment lire chaque ligne de données ? La classe StreamReader comprend la méthode ReadLine() et si nous l’appelions au lieu de ReadToEnd(), nous obtiendrions la première ligne de données de nos fichiers :
|
1
2
3
|
$newstreamreader = New-Objet System.IO.StreamReader(« C:\logging\logging.txt »)
$newstreamreader.ReadLine()
Wewstreamreader.Dispose()
|

Comme nous avons dit au StreamReader de lire la ligne, il a lu la première ligne du fichier et s’est arrêté. La raison en est que la méthode ReadLine() ne lit que la ligne en cours (dans ce cas, la première ligne). Nous devons continuer à lire le fichier jusqu’à ce que nous atteignions la fin du fichier. Comment savoir quand un fichier se termine ? La dernière ligne est nulle. En d’autres termes, nous voulons que le StreamReader continue à lire le fichier (boucle while) tant que chaque nouvelle ligne n’est pas nulle (en d’autres termes, contient des données). Pour démontrer cela, ajoutons un compteur de ligne à chaque ligne sur laquelle nous itérons afin de voir la logique avec des chiffres et du texte :
|
1
2
3
4
5
. 6
7
8
|
$newstreamreader = New-Objet System.IO.StreamReader(« C:\logging\logging.txt »)
$eachlinenumber = 1
while (($readeachline =$newstreamreader.ReadLine()) -ne $null)
{
Ecrire-Host « $eachlinenumber $readeachline »
$eachlinenumber++
}
$newstreamreader.Dispose()
|
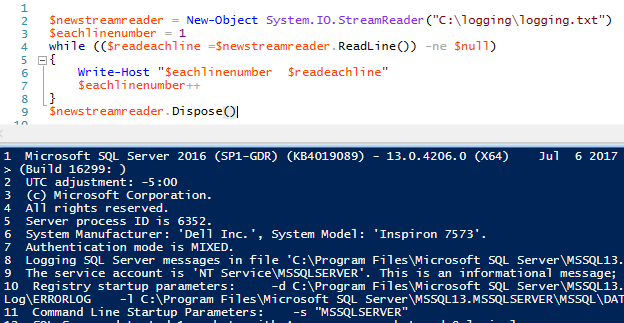
Lorsque StreamReader lit chaque ligne, il stocke les données de la ligne dans l’objet que nous avons créé $readeachline. Nous pouvons appliquer des fonctions de chaîne à cette ligne de données à chaque passage, comme par exemple obtenir les dix premiers caractères de la ligne de données :
|
1
2
3
4
5
6
7
|
$newstreamreader = New-Objet System.IO.StreamReader(« C:\logging\logging.txt »)
$eachlinenumber = 1
while (($readeachline = $newstreamreader.ReadLine()) -ne $null)
{
$readeachline.Substring(0,10)
}
$newstreamreader.Dispose()
|
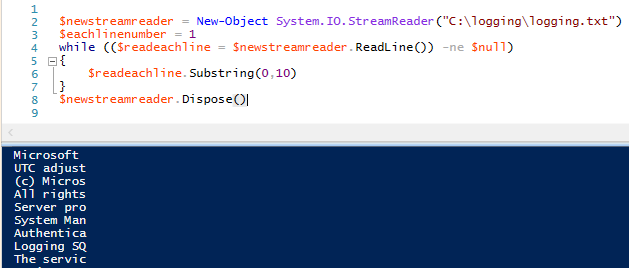
.
Nous pouvons étendre cet exemple et appeler deux autres méthodes de chaîne de caractères – en incluant cette fois les méthodes de chaîne de caractères IndexOf et Replace(). Nous n’appelons ces méthodes que sur les deux premières lignes en ne récupérant que les lignes inférieures à la ligne 3 :
|
1
2
3
4
5
6
7
8
9
10
. 11
12
13
14
|
$newstreamreader = New-Objet System.IO.StreamReader(« C:\logging\logging.txt »)
$eachlinenumber = 1
while (($readeachline = $newstreamreader.ReadLine()) -ne $null)
{
si ($eachlinenumber -lt 3)
{
Ecriture-Hôte « $eachlinenumber »
$readeachline.Substring(0,12)
$readeachline.IndexOf( » « )
$readeachline.Replace( » « , « replace »)
}
$eachlinenumber++
}
$newstreamreader.Dispose()
|
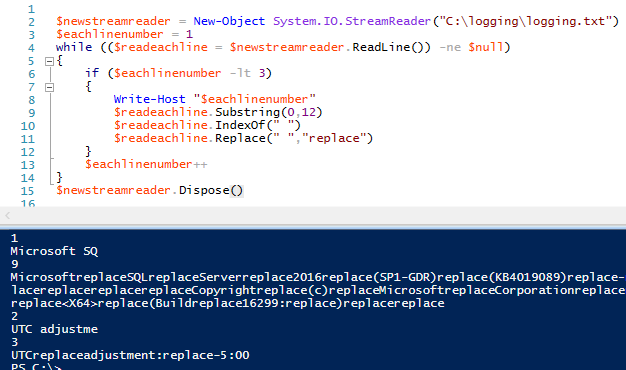
Pour l’analyse des données, nous pouvons utiliser nos méthodes de chaîne sur chaque ligne du fichier – ou sur une ligne spécifique du fichier – à chaque itération de la boucle.
Enfin, nous voulons pouvoir obtenir une ligne spécifique du fichier – nous pouvons obtenir la première et la dernière ligne du fichier en utilisant Get-Content. Utilisons StreamReader pour parier un numéro de ligne spécifique que nous passons à une fonction personnalisée que nous créons. Nous allons créer une fonction réutilisable qui renvoie un numéro de ligne spécifique, ensuite nous voulons envelopper notre fonction pour la réutiliser tout en exigeant deux entrées : l’emplacement du fichier et le numéro de ligne spécifique que nous voulons retourner.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
Fonction Get-FileData {
Param(
notrefilelocation
, $specificline
)
Processus
{
$newstreamreader = New-Object System.IO.StreamReader($notrefilelocation)
$eachlinenumber = 1
while (($readeachline = $newstreamreader.ReadLine()) -ne $null)
{
si ($eachlinenumber -eq $specificline)
{
$readeachline
break ;
}
$eachlinenumber++
}
$newstreamreader.Dispose()
}
}
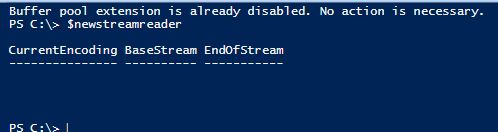
$savelinetovariable = Get-FileData -notre emplacement de fichier « C:\logging.txt » -specificline 17
$savelinetovariable
|
.
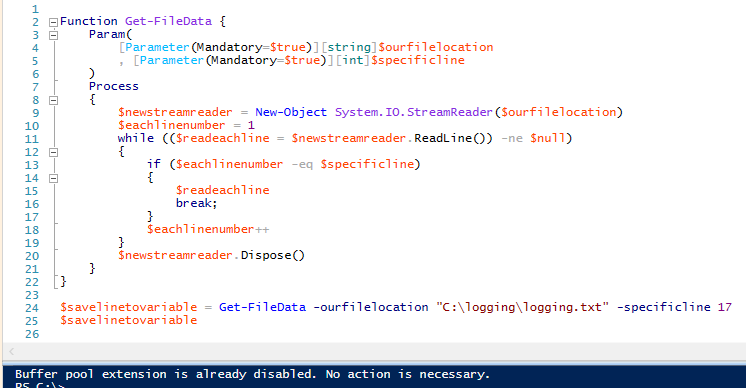
Si nous vérifions, la ligne 17 renvoie « Buffer pool extension is already disabled. Aucune action n’est nécessaire. » correctement. En outre, nous cassons l’instruction if – car il n’est pas nécessaire de continuer à lire le fichier une fois que nous avons obtenu la ligne de données que nous voulons. De plus, la méthode dispose met bien fin à l’objet, comme nous pouvons le vérifier en appelant la méthode depuis la ligne de commande dans PowerShell ISE et elle ne retournera rien (nous pourrions également vérifier dans la fonction et obtenir le même résultat) :
Pensées finales
Pour des performances personnalisées, StreamReader offre plus de potentiel, car nous pouvons lire chaque ligne de données et appliquer nos fonctions supplémentaires selon nos besoins. Mais nous n’avons pas toujours besoin de quelque chose à personnaliser et il se peut que nous ne voulions lire que quelques premières et dernières lignes de données, auquel cas la fonction Get-Content nous convient bien. En outre, les petits fichiers fonctionnent bien avec Get-Content, car nous ne recevons jamais trop de données à la fois. Il faut juste faire attention si les fichiers ont tendance à grossir avec le temps.
- Auteur
- Postes récents
 Timothy Smith
Timothy SmithIl a passé une décennie à travailler dans le secteur FinTech, ainsi que quelques années dans les secteurs BioTech et Energy Tech.
Il anime le groupe d’utilisateurs SQL Server de l’ouest du Texas, et donne des cours et écrit des articles sur SQL Server, ETL et PowerShell.
Dans son temps libre, il est un contributeur à l’industrie financière décentralisée.
Voir tous les messages de Timothy Smith
- Masquage des données ou altération des informations comportementales – 26 juin, 2020
- Test de sécurité avec des plages de volume de données extrêmes – 19 juin 2020
- Téléchargement des performances de SQL Server – Attentes RESOURCE_SEMAPHORE – 16 juin 2020
.