Le volume des données conservées, gérées et consultées aujourd’hui est sans précédent. Les entreprises attendent du service informatique qu’il maintienne les données en ligne et accessibles indéfiniment, ce qui exerce une pression intense sur les bases de données nécessaires pour les stocker et les gérer. Pour répondre aux besoins d’aujourd’hui, nous devons remplacer les anciens processus obsolètes et inefficaces par de nouvelles techniques plus souples. La réplication SQL Server est l’une des techniques permettant de répondre à de telles demandes.
-
Note : pour en savoir plus sur la réplication des bases de données, veuillez lire Différentes parties prenantes, différents points de vue : Pourquoi la gestion des bases de données nécessite une approche systématique.
Dans cet article, façonnez votre compréhension de la topographie complète de la réplication SQL Server, y compris les composants, les internes et le SQL pour lier le tout. Après avoir terminé la lecture de cet article, vous comprendrez :
- La réplication SQL Server, en général
- Composants de la réplication transactionnelle SQL Server, en particulier
- Comment obtenir les propriétés du distributeur
- Comment trouver l’éditeur utilisant le même distributeur
- Quelles sont les bases de données utilisées pour la réplication SQL Server
- La topologie générale d’un environnement de réplication
- Quels sont les articles qui sont mis en correspondance avec le type de modèle de réplication SQL Server
- Comment obtenir la publication. détails
- Comment obtenir les détails de l’abonnement
- Les agents de réplication SQL Server
- Et plus…
Réplication
La réplication SQL Server est une technologie permettant de copier et de distribuer des données et des objets de base de données d’une base de données à une autre, puis de synchroniser entre les bases de données pour maintenir la cohérence et l’intégrité des données. Dans la plupart des cas, la réplication est un processus de reproduction des données aux cibles souhaitées. La réplication SQL Server est utilisée pour copier et synchroniser les données en continu ou peut également être planifiée pour s’exécuter à des intervalles prédéterminés. Il existe plusieurs techniques de réplication différentes qui prennent en charge une variété d’approches de synchronisation des données ; unidirectionnelle ; un-à-plusieurs ; plusieurs-à-un ; et bidirectionnelle, et maintiennent plusieurs ensembles de données synchronisés les uns avec les autres.
Composants de la réplication transactionnelle de SQL Server
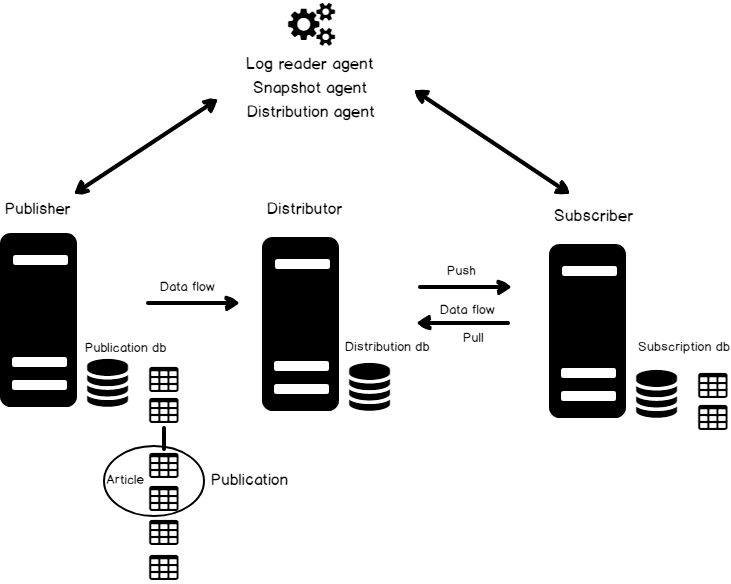
Le diagramme suivant décrit les composants de la réplication transactionnelle de SQL Server.
Y compris la réplication SQL Server …
- Éditeur
- Base de données de publication
- Publication
- Articles
- Distributeur
- Base de données de distribution
- Abonné
- Base de données d’abonnement.
- Abonnement
- Agents de réplication
Diagramme de réplication du serveur SQL
Article
Un article est l’unité de base de la réplication du serveur SQL. Un article peut être constitué de tables, de procédures stockées et de vues. Il est possible de mettre à l’échelle l’article, horizontalement et verticalement en utilisant une option de filtre. Nous pouvons également créer plusieurs articles sur le même objet avec quelques restrictions et limitations.
À l’aide de l’assistant de nouvelle publication, on peut naviguer dans l’article. Il nous permet de visualiser les propriétés d’un article et de fournir des options pour définir les propriétés des articles. Dans certains cas, les propriétés peuvent être définies au moment de la création de la publication et c’est une propriété en lecture seule.
Après la création d’une publication de réplication SQL Server, par exemple, si une certaine propriété nécessite une modification, elle nécessitera, à son tour, la génération d’un nouvel instantané de réplication. Si la publication possède un ou plusieurs abonnements, alors la modification nécessite la réinitialisation de tous les abonnements. Pour plus d’informations, voir l’article Comment ajouter/supprimer des articles à/de la publication existante dans SQL Server.
Pour répertorier tous les articles qui sont publiés, exécutez la commande T- suivanteSQL
|
.
1
. 2
… 3
4
. 5
6
7
8
9
10
11
12
|
SELECT
Public.
,Art.
,Art.
,Art.
,Art.
FROM
.. Art
INNER JOIN … Pub
ON Art. = Pub.
ORDONNER PAR
Pub., Art.
|
Pour obtenir les détails des articles dans une réplication SQL Server transactionnelle ou de fusion dans une base de données publiée, exécutez la T-SQL suivante.
|
1
2
3
4
5
6
7
8
|
SELECT st.name , st.schema_id, st.is_published , st.is_merge_published, is_schema_published
FROM sys.tables st WHERE st.is_published = 1 or st.is_merge_published = 1 or st.is_schema_published = 1
UNION
SELECT sp.name, sp.schema_id, 0, 0, sp.is_schema_published
FROM sys.procedures sp WHERE sp.is_schema_published = 1
Union
Select sv.name, sv.schema_id, 0, 0, sv.is_schema_published
From sys.views sv WHERE sv.is_schema_published = 1 ;
|
Pour obtenir des informations détaillées sur un article dans l’éditeur listé, exécutez le T-SQL
|
1
2
3
4
5
6
7
|
DECLARE @publication AS sysname ;
SET @publication = N’PROD_HIST_Pub’ ;
USE MES_PROD_AP
EXEC sp_helparticle
@publication = @publication ;
GO
|
Pour obtenir des détails au niveau des colonnes, exécutez le T-SQL
|
1
2
3
|
USE MES_PROD_AP
GO
sp_helparticlecolumns @publication = N’PROD_HIST_Pub’ , @article = ‘tb_Branche_Plant’
|
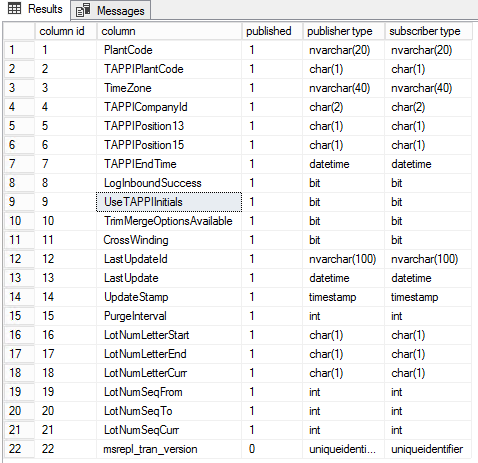
Pour lister les colonnes qui sont publiées en réplication transactionnelle dans la base de données de publication, exécutez le T-SQL
|
1
|
SELECT object_name(object_id) , nom FROM sys.columns sc WHERE sc.is_replicated = 1 ;
|
Publications
Une publication est une collection logique d’articles provenant d’une base de données. L’entité nous permet de définir et de configurer les propriétés des articles au niveau supérieur afin que les propriétés soient héritées à tous les articles de ce groupe.
|
1
|
EXEC sp_helppublication ;
|
Base de données de l’éditeur
L’éditeur est une base de données qui contient une liste d’objets désignés comme articles de réplication SQL Server sont connus comme base de données de publication. L’éditeur peut avoir une ou plusieurs publications. Chaque éditeur définit un mécanisme de propagation des données en créant plusieurs procédures stockées de réplication internes.
|
1
2
3
|
USE Distribution
GO
select * from MSpublications
|

Éditeur
L’éditeur est une instance de base de données qui met des données à la disposition d’autres emplacements via la réplication SQL Server. Le Publisher peut avoir une ou plusieurs publications, chacune définissant un ensemble logiquement lié d’objets et de données à répliquer.
Distributeur
Le Distributeur est une base de données qui agit comme un entrepôt pour les données spécifiques à la réplication associées à un ou plusieurs Publishers. Dans de nombreux cas, le distributeur est une base de données unique qui joue à la fois le rôle de l’éditeur et du distributeur. Dans le contexte de la réplication SQL Server, on parle alors de « distributeur local ». En revanche, s’il est configuré sur un serveur distinct, on parle alors de « distributeur distant ». Chaque éditeur est associé à une seule base de données appelée « base de données de distribution » alias le « distributeur ».
La base de données de distribution identifie et stocke les données d’état de la réplication SQL Server, les métadonnées relatives à la publication et, dans certains cas, sert de file d’attente pour les données passant de l’Éditeur aux Abonnés.
Selon le modèle de réplication, le Distributeur peut également être chargé de notifier aux Abonnés qui se sont abonnés à une publication qu’un article a été modifié. Aussi, la base de données de distribution maintient l’intégrité des données.
Bases de données de distribution
Chaque Distributeur doit avoir au moins une base de données de distribution. La base de données de distribution est constituée de détails sur les articles, de métadonnées de réplication et de données. Un Distributeur peut détenir plus d’une base de données de distribution ; cependant, toutes les publications définies sur un même Éditeur doivent utiliser la même base de données de distribution.
Pour savoir si …
-
un serveur est un distributeur ou non ?
1SELECT @@ServerName Servername, case when is_distributor=1 then ‘Yes’ else ‘No’ end status FROM sys.servers WHERE name=’repl_distributor’ AND data_source=@@servername ;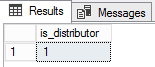
-
une base de données de distribution installée ou non ?
1SELECT name FROM sys.databases WHERE is_distributor = 1 -
Un éditeur utilise ce distributeur ou pas ?
1EXEC sp_get_distributor
-
ou simplement pour interroger diverses propriétés des bases de données Distributeur et Distribution ?
123EXEC sp_helpdistributor ;EXEC sp_helpdistributiondb ;EXEC sp_helpdistpublisher ;Subscriber
Une instance de base de données qui consomme les données de réplication SQL Server d’une publication est appelée un Subscriber. L’abonné peut recevoir des données d’un ou plusieurs éditeurs et publications. L’abonné peut également renvoyer les modifications de données à l’éditeur ou republier les données vers d’autres abonnés, selon le type de conception et de modèle de réplication.
1EXEC sp_helpsubscriberinfo ;Abonnements
Un abonnement est une demande de livraison d’une copie d’une publication à un Abonné. L’abonnement définit les données de la publication qui seront reçues, où et quand.
Il existe deux types d’abonnements : les abonnements push et les abonnements pull
- Abonnement push : Le Distributeur met directement à jour les données dans la base de données de l’Abonné
- Abonnement pull : l’Abonné est programmé pour vérifier chez le Distributeur régulièrement si de nouveaux changements sont disponibles, puis met à jour lui-même les données dans la base de données de l’abonnement.
1EXEC sp_helpsubscription ;Bases de données d’abonnement
Une base de données cible d’un modèle de réplication est appelée base de données d’abonnement.
Agents de réplication
La réplication SQL Server utilise un ensemble prédéfini de programmes et d’événements autonomes sont appelés agents, pour effectuer les tâches associées aux données. Par défaut, les agents de réplication SQL Server s’exécutent en tant que tâches planifiées sous SQL Server Agent. Les agents de réplication peuvent également être exécutés à partir de la ligne de commande et par des applications qui utilisent les objets de gestion de réplication (RMO). Les agents de réplication SQL Server peuvent être surveillés et administrés à l’aide de Replication Monitor et de SQL Server Management Studio.
L’agent de réplication snapshot
L’agent de réplication snapshot est utilisé avec tous les types de technologie de réplication SQL Server car il fournit l’ensemble de données requis pour effectuer la synchronisation initiale des données de la base de données de publication avec la base de données d’abonnement. Il prépare le schéma et les données initiales des articles publiés, les fichiers d’instantanés, et enregistre les informations relatives au type de synchronisation dans la base de données de distribution.
Log Reader Agent
L’agent Log Reader est utilisé uniquement avec la réplication transactionnelle. Il déplace les transactions de réplication du journal des transactions en ligne de la base de données de publication vers la base de données de distribution.
Agent de distribution
L’agent de distribution est utilisé uniquement avec la réplication instantanée et la réplication transactionnelle de SQL Server. Cet agent applique le snapshot de réplication initial à la base de données d’abonnement et, plus tard, les modifications de données sont suivies et enregistrées dans la base de données de distribution et appliquées à la base de données d’abonnement.
Agent de fusion
L’agent de fusion est utilisé avec le modèle de réplication par fusion. Par défaut, l’agent de fusion télécharge les modifications de l’abonné vers l’éditeur, puis télécharge les modifications de l’éditeur vers l’abonné. Chaque abonnement dispose de son propre agent de fusion qui se connecte à la fois à l’éditeur et à l’abonné et les met à jour. L’agent de fusion fonctionne soit au niveau du distributeur pour les abonnements « push », soit au niveau de l’abonné pour les abonnements « pull ». Ici, la synchronisation est bidirectionnelle. Les conflits de données sont gérés par un ensemble de déclencheurs qui prennent en charge l’ensemble du processus
Résumé
Jusqu’à présent, nous avons vu une présentation de certains des concepts importants de la réplication SQL Server. De plus, des scripts T-SQL sont présentés pour interroger les tables système et les procédures stockées de réplication afin de répondre à la plupart des questions fréquemment posées sur la réplication SQL Server.
J’aborderai plus en détail la réplication de SQL Server dans les prochains articles. Si vous pensez, que quelque chose peut être amélioré dans cet article, n’hésitez pas à laisser votre commentaire ci-dessous…
Table des matières
La réplication SQL Server : Aperçu des composants et de la topographie
La réplication SQL : Installation et configuration de base
Comment ajouter/déposer des articles à partir de publications existantes dans SQL Server
Comment faire une comparaison estimative rapide des données dans deux grandes bases de données SQL Server pour voir si elles sont égales
Réplication transactionnelle de SQL Server : Comment réinitialiser un abonnement à l’aide d’une sauvegarde de base de données SQL Server
Comment configurer un modèle de réplication transactionnelle SQL Server personnalisé avec un abonné central et des bases de données d’éditeurs multiples
Comment configurer une réplication transactionnelle SQL Server personnalisée avec un éditeur central et des bases de données d’abonnés multiples
Comment configurer une solution de réplication transactionnelle de base de données SQL Server DDL et DML
Comment configurer une réplication transactionnelle SQL Server multiplateforme pour des bases de données d’abonnés multiples
.plateforme de réplication transactionnelle SQL Server pour le reporting de base de données sur Linux
Migrations de bases de données SQL Server avec zéro perte de données et zéro temps d’arrêt
Utilisation de la réplication transactionnelle de données pour rejouer et tester les charges de production sur un serveur de mise en scène
Comment configurer la réplication de base de données SQL Server pour un serveur de reporting
Réplication transactionnelle SQL Server : Comment réinitialiser un abonnement à l’aide d’un « support de réplication uniquement » -TBA
SQL Server Replication Monitoring and setting alerts using PowerShell -TBA
.
- Auteur
- Postages récents
 Je suis un technologue des bases de données ayant 11+ ans de rich, expérience pratique sur les technologies de base de données. Je suis un professionnel certifié Microsoft et soutenu par un diplôme de maîtrise en application informatique.
Je suis un technologue des bases de données ayant 11+ ans de rich, expérience pratique sur les technologies de base de données. Je suis un professionnel certifié Microsoft et soutenu par un diplôme de maîtrise en application informatique.
Ma spécialité réside dans la conception & la mise en œuvre de solutions de haute disponibilité et la migration de DB multiplateforme. Les technologies sur lesquelles je travaille actuellement sont SQL Server, PowerShell, Oracle et MongoDB.
Voir tous les messages de Prashanth JayaramDerniers messages de Prashanth Jayaram (voir tous)- Un aperçu rapide de l’audit de base de données en SQL – 28 janvier, 2021
- Comment configurer Azure Data Sync entre les bases de données Azure SQL et le serveur SQL sur site – 20 janvier 2021
- Comment effectuer des opérations d’importation/exportation de bases de données Azure SQL à l’aide de PowerShell – 14 janvier 2021
.