Als u nog niet bekend bent met Tree-Based Models in Machine Learning, moet u eens kijken naar onze R-cursus over dit onderwerp.
Het Random Forests Algoritme
Laten we het algoritme eens in lekentaal begrijpen. Stel, je wilt op reis gaan en je wilt naar een plek die je leuk vindt.
Dus wat doe je om een plek te vinden die je leuk vindt? U kunt online zoeken, recensies lezen op reisblogs en portals, of u kunt het ook aan uw vrienden vragen.
Stel dat u hebt besloten uw vrienden te vragen, en met hen hebt gesproken over hun eerdere reiservaringen naar verschillende plaatsen. U zult van elke vriend een aantal aanbevelingen krijgen. Nu moet je een lijst maken van deze aanbevolen plaatsen. Dan vraagt u hen om te stemmen (of één beste plaats voor de reis te kiezen) van de lijst van aanbevolen plaatsen die u hebt gemaakt. De plaats met het hoogste aantal stemmen wordt je definitieve keuze voor de reis.
In het bovenstaande beslissingsproces zijn er twee delen. Ten eerste vraag je je vrienden naar hun individuele reiservaring en krijg je één aanbeveling uit meerdere plaatsen die ze hebben bezocht. Dit deel is als het gebruik van het beslissingsboom algoritme. Hier maakt elke vriend een selectie van de plaatsen die hij of zij tot nu toe heeft bezocht.
Het tweede deel, na het verzamelen van alle aanbevelingen, is de stemprocedure voor het selecteren van de beste plaats in de lijst van aanbevelingen. Dit hele proces van aanbevelingen krijgen van vrienden en daarop stemmen om de beste plaats te vinden staat bekend als het random forests algoritme.
Het is technisch gezien een ensemble-methode (gebaseerd op de verdeel-en-heers-aanpak) van beslisbomen die worden gegenereerd op een willekeurig gesplitste dataset. Deze verzameling beslisboomclassificeerders wordt ook wel het bos genoemd. De individuele beslissingsbomen worden gegenereerd met behulp van een attribuutselectie-indicator zoals informatiewinst, winstverhouding en Gini-index voor elk attribuut. Elke boom is afhankelijk van een onafhankelijke willekeurige steekproef. In een classificatieprobleem stemt elke boom en wordt de meest populaire klasse als eindresultaat gekozen. In het geval van regressie wordt het gemiddelde van alle boomoutputs beschouwd als het eindresultaat. Het is eenvoudiger en krachtiger in vergelijking met de andere niet-lineaire classificatiealgoritmen.
Hoe werkt het algoritme?
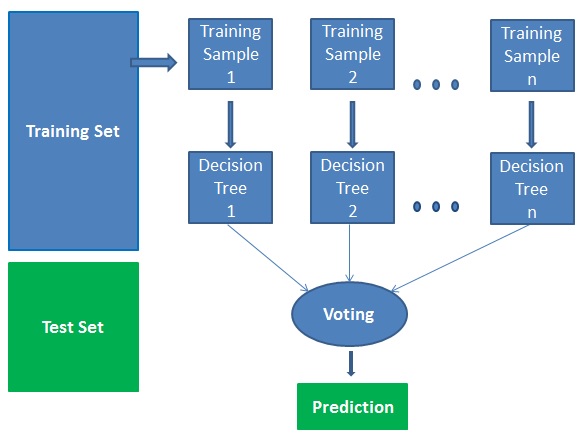
Het werkt in vier stappen:
- Selecteer willekeurige monsters uit een gegeven dataset.
- Bouw voor elk monster een beslissingsboom en krijg een voorspellend resultaat van elke beslissingsboom.
- Voer een stemming uit voor elk voorspeld resultaat.
- Selecteer het voorspellingsresultaat met de meeste stemmen als de uiteindelijke voorspelling.
Voordelen:
- Random forests wordt beschouwd als een zeer nauwkeurige en robuuste methode vanwege het aantal beslisbomen dat aan het proces deelneemt.
- Het heeft geen last van het overfitting-probleem. De belangrijkste reden hiervoor is dat het het gemiddelde neemt van alle voorspellingen, waardoor de biases worden geannuleerd.
- Het algoritme kan worden gebruikt in zowel classificatie- als regressieproblemen.
- Random forests kan ook omgaan met ontbrekende waarden. Er zijn twee manieren om hiermee om te gaan: het gebruik van mediane waarden om continue variabelen te vervangen, en het berekenen van het proximity-weighted average van ontbrekende waarden.
- Je kunt het relatieve feature-belang krijgen, wat helpt bij het selecteren van de meest bijdragende features voor de classifier.
Nadelen:
- Random forests is traag in het genereren van voorspellingen omdat het meerdere beslisbomen heeft. Telkens wanneer het een voorspelling doet, moeten alle bomen in het bos een voorspelling doen voor dezelfde gegeven input en er dan over stemmen. Dit hele proces is tijdrovend.
- Het model is moeilijk te interpreteren vergeleken met een beslisboom, waar je gemakkelijk een beslissing kunt nemen door het pad in de boom te volgen.
Het vinden van belangrijke features
Random forests biedt ook een goede feature selectie-indicator. Scikit-learn levert een extra variabele bij het model, die het relatieve belang of de bijdrage van elk kenmerk in de voorspelling weergeeft. Het berekent automatisch de relevantiescore van elk kenmerk in de trainingsfase. Daarna schaalt het de relevantie naar beneden, zodat de som van alle scores 1 is.
Deze score helpt je om de belangrijkste features te kiezen en de minst belangrijke te laten vallen voor de modelbouw.
Random forest gebruikt gini belang of gemiddelde afname in onzuiverheid (MDI) om het belang van elk kenmerk te berekenen. Gini belang is ook bekend als de totale afname in knooppunt onzuiverheid. Dit is hoeveel de model fit of nauwkeurigheid afneemt wanneer je een variabele laat vallen. Hoe groter de afname, hoe significanter de variabele is. Hier is de gemiddelde afname een belangrijke parameter voor variabelenselectie. De Gini-index kan de totale verklarende kracht van de variabelen beschrijven.
Random Forests vs Decision Trees
- Random forests is een set van meerdere beslisbomen.
- Diepe beslisbomen kunnen last hebben van overfitting, maar random forests voorkomt overfitting door bomen te maken op willekeurige subsets.
- Decision trees zijn rekenkundig sneller.
- Random forests is moeilijk te interpreteren, terwijl een beslisboom gemakkelijk te interpreteren is en in regels kan worden omgezet.
Building a Classifier using Scikit-learn
Je gaat een model bouwen op de irisbloemen dataset, een zeer bekende classificatieset. Hij omvat de kelklengte, kelkbreedte, kroonbladlengte, kroonbladbreedte en bloemtype. Er zijn drie soorten of klassen: setosa, versicolor, en virginia. U zult een model bouwen om het type bloem te classificeren. De dataset is beschikbaar in de scikit-learn bibliotheek of je kunt hem downloaden van de UCI Machine Learning Repository.
Start met het importeren van de datasets bibliotheek van scikit-learn, en laad de iris dataset met load_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Je kunt de doel- en kenmerknamen afdrukken, om er zeker van te zijn dat je de juiste dataset hebt, als volgt:
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)Het is een goed idee om je data altijd een beetje te verkennen, zodat je weet waar je mee werkt. Hier zie je dat de eerste vijf rijen van de dataset worden afgedrukt, evenals de doelvariabele voor de hele dataset.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Hier kun je op de volgende manier een DataFrame van de iris dataset maken.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| petaallengte | pootbreedte | pootlengte | pootbreedte | soort | |
|---|---|---|---|---|---|
| 0 | 1.4 | 0.2 | 5.1 | 3.5 | 0 |
| 1 | 1.4 | 0.2 | 4.9 | 3.0 | 0 |
| 2 | 1.3 | 0.2 | 4.7 | 3.2 | 0 |
| 3 | 1.5 | 0.2 | 4.6 | 3.1 | 0 |
| 4 | 1.4 | 0.2 | 5.0 | 3.6 | 0 |
Eerst verdeelt u de kolommen in afhankelijke en onafhankelijke variabelen (of kenmerken en labels). Vervolgens splitst u die variabelen in een training- en een testset.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testNa de splitsing traint u het model op de trainingsset en voert u voorspellingen uit op de testset.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Na de training controleert u de nauwkeurigheid aan de hand van de werkelijke en de voorspelde waarden.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)U kunt ook een voorspelling doen voor een enkel item, bijvoorbeeld:
- pootlengte = 3
- pootbreedte = 5
- pootbladlengte = 4
- pootbladbreedte = 2
Nu kun je voorspellen welk type bloem het is.
clf.predict(])array()Hier geeft 2 het bloemtype Virginica aan.
Vinden van belangrijke features in Scikit-learn
Hier vindt u belangrijke features of selecteert u features in de IRIS dataset. In scikit-learn kun je deze taak in de volgende stappen uitvoeren:
- Eerst moet je een random forests model maken.
- Tweede, gebruik de feature importance variabele om de feature importance scores te zien.
- Derde, visualiseer deze scores met behulp van de seaborn bibliotheek.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64Je kunt het feature belang ook visualiseren. Visualisaties zijn eenvoudig te begrijpen en te interpreteren.
Voor visualisatie kun je een combinatie van matplotlib en seaborn gebruiken. Omdat seaborn is gebouwd bovenop matplotlib, biedt het een aantal aangepaste thema’s en biedt het extra plottypen. Matplotlib is een superset van seaborn en beide zijn even belangrijk voor goede visualisaties.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()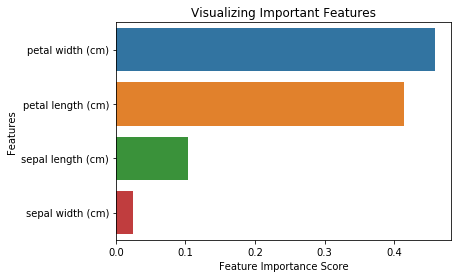
Het model genereren op geselecteerde kenmerken
Hier kunt u het kenmerk “kelkbreedte” verwijderen omdat het van zeer gering belang is, en de 3 resterende kenmerken selecteren.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testNa het splitsen genereert u een model op de geselecteerde kenmerken van de trainingsset, voert u voorspellingen uit op de geselecteerde kenmerken van de testset, en vergelijkt u de werkelijke en de voorspelde waarden.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Je kunt zien dat na het verwijderen van de minst belangrijke kenmerken (kelkbladlengte) de nauwkeurigheid is toegenomen. Dit komt omdat je misleidende gegevens en ruis hebt verwijderd, wat resulteert in een grotere nauwkeurigheid. Een kleiner aantal kenmerken vermindert ook de trainingstijd.
Conclusie
Gefeliciteerd, u heeft het einde van deze tutorial gehaald!
In deze tutorial heeft u geleerd wat random forests is, hoe het werkt, het vinden van belangrijke kenmerken, de vergelijking tussen random forests en beslisbomen, de voor- en nadelen. Je hebt ook geleerd modellen te bouwen, te evalueren en belangrijke kenmerken te vinden in scikit-learn. B
Als je meer wilt leren over machine learning, raad ik je aan onze Supervised Learning in R: Classificatie cursus.