A sua tabela pode conter valores duplicados numa coluna e em certos cenários pode necessitar de ir buscar apenas registos únicos à tabela.
Para remover os registos duplicados para os dados obtidos com a instrução SELECT, pode utilizar a cláusula DISTINCT como se mostra nos exemplos abaixo.
Uma demonstração de SELECT simples – DISTINCT
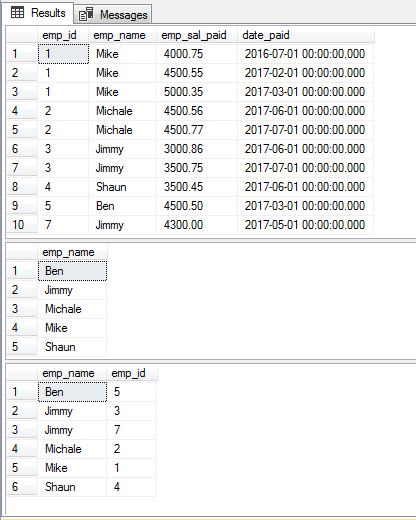
No primeiro exemplo, utilizei a cláusula DISTINCT com a instrução SELECT para recuperar apenas nomes únicos da nossa tabela de demonstração, sto_emp_salary_paid. Esta tabela armazena os salários dos funcionários juntamente com os seus nomes. Assim, a ocorrência em duplicado de nomes de empregados ocorre na tabela.
Utilizando a cláusula DISTINCT, obtemos apenas nomes únicos de empregados:
P>Query:
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid;
(Aplica-se a bases de dados SQL Server e MySQL)
Usando a cláusula WHERE com DISTINCT
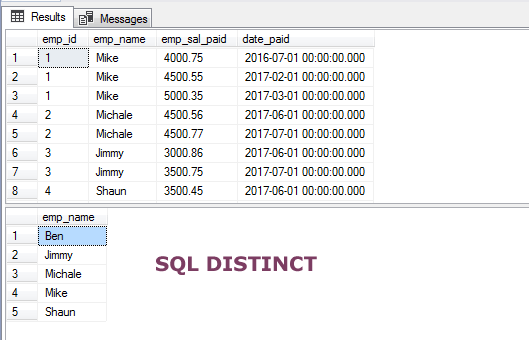
Neste exemplo, Utilizei a cláusula WHERE com a declaração SELECT/DISTINCT para recuperar apenas os empregados únicos a quem o salário pago é superior ou igual a 4500. Ver a consulta e o conjunto de resultados:
Consulta:
|
1
2
3
|
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
WHERE emp_sal_paid >= 4500;
|
 SQL DISTINCT WHERE
SQL DISTINCT WHERE
O exemplo da função COUNT com DISTINCT
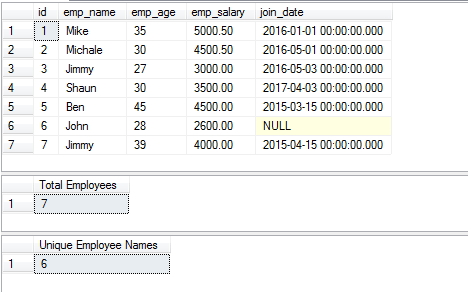
P>Pode também utilizar a função COUNT SQL para obter o número de registos como utilizando a cláusula DISTINCT. A função retorna apenas para as linhas devolvidas após a cláusula DISTINCT.
Para a demonstração, estou a utilizar a tabela de empregados que armazena a informação sobre os empregados. Três consultas são utilizadas na demonstração como se segue:
- A primeira consulta retorna o registo completo da tabela
- A segunda consulta obtém o número de empregados usando ID (COUNT e DISTINCT)
- enquanto a terceira retorna os nomes únicos dos empregados usando a coluna emp_name.
As três consultas são:
|
1
2
3
4
5
6
7
|
>div>
>div> SELECT * DE sto_employees;
SELECT COUNT(DISTINCT id) AS “Total Employees” FROM sto_employees
SELECT COUNT(DISTINCT emp_name) AS “Unique Employee Names” FROM sto_employees
|
A cláusula DISTINCT com GROUP BY example
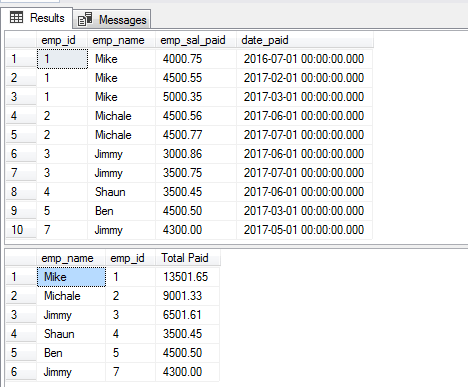
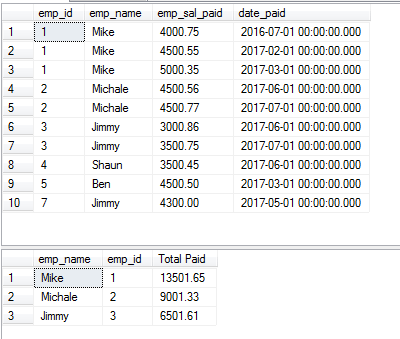
A seguinte consulta vai buscar os registos à mesma tabela utilizada nos exemplos acima e agrupa os funcionários que pagaram salários. Para isso, as cláusulas GROUP BY e DISTINCT são utilizadas da seguinte forma:
A Consulta:
|
1
2
3
|
>div>>div>
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As “Total Paid” FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id;
|
 SQL DISTINCT GROUP-BY
SQL DISTINCT GROUP-BY
O registo para o “Jimmy” aparece duas vezes, pois tem dois IDs diferentes.
Usando a cláusula HAVING com DISTINCT
Como usando a cláusula GROUP BY com DISTINCT, também se pode adicionar a cláusula HAVING para buscar registos. Na consulta seguinte, a cláusula HAVING é adicionada no exemplo acima e iremos buscar os registos cujo SUM é superior a 5000.
A consulta:
|
1
2
3
4
5
|
 O DISTINTO DISTINTO HAVING
O DISTINTO DISTINTO HAVING
A cláusula DISTINTO com ORDEM POR exemplo
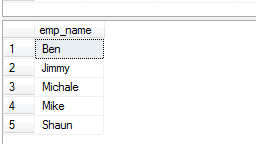
A cláusula SQL ORDER BY pode ser usada com a cláusula DISTINCT para ordenar os resultados após a remoção de valores duplicados. Ver a consulta e a saída abaixo:
|
1
2
3
|
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
ORDER BY emp_name;
|
br> O resultado:
Utilizar múltiplas colunas na cláusula DISTINCT
P>Pode também especificar duas ou mais colunas como utilizando a cláusula SELECT – DISTINCT. Como tal, a nossa tabela de exemplo contém valores duplicados para empregados e os seus IDs, pelo que será bom aprender a ver como a cláusula DISTINCT devolve os registos como utilizando ambas as colunas na consulta única.
Para ver a diferença, escrevi primeiro uma consulta com DISTINCT (emp_name) que é seguida pela utilização de ambas as colunas:
A Consulta:
|
1
2
3
4
5
6
7
8
9
/td> div>>>div>
SELECT DISTINCT emp_name FROM sto_emp_salary_paid
ORDER BY emp_name;
SELECT DISTINCT emp_name,emp_id FROM sto_emp_salary_paid
ORDER BY emp_name;
|
br> Os resultados para tabela completa, DISTINCT emp_name e DISTINCT emp_name,emp_id consultas: