Introdução
Qualquer aplicação ou website que veja um crescimento significativo terá eventualmente de ser dimensionado de modo a acomodar o aumento de tráfego. Para aplicações e websites orientados por dados, é fundamental que a escala seja feita de forma a garantir a segurança e integridade dos seus dados. Pode ser difícil prever quão popular um website ou aplicação se tornará ou por quanto tempo manterá essa popularidade, razão pela qual algumas organizações escolhem uma arquitectura de base de dados que lhes permita escalar as suas bases de dados de forma dinâmica.
Neste artigo conceptual, discutiremos uma dessas arquitecturas de base de dados: bases de dados fragmentadas. A fragmentação tem recebido muita atenção nos últimos anos, mas muitas não têm uma compreensão clara do que é ou dos cenários em que pode fazer sentido fragmentar uma base de dados. Passaremos em revista o que é fragmentar, alguns dos seus principais benefícios e desvantagens, e também alguns métodos comuns de fragmentação.
O que é fragmentar?
Sharding é um padrão de arquitectura de base de dados relacionado com a partição horizontal – a prática de separar as linhas de uma tabela em múltiplas tabelas diferentes, conhecidas como partições. Cada partição tem o mesmo esquema e colunas, mas também filas completamente diferentes. Da mesma forma, os dados mantidos em cada uma são únicos e independentes dos dados mantidos noutras partições.
Pode ser útil pensar na partição horizontal em termos de como se relaciona com a partição vertical. Numa tabela particionada verticalmente, colunas inteiras são separadas e colocadas em tabelas novas e distintas. Os dados contidos numa partição vertical são independentes dos dados de todas as outras, e cada uma contém linhas e colunas distintas. O diagrama seguinte ilustra como uma tabela poderia ser dividida tanto horizontal como verticalmente:
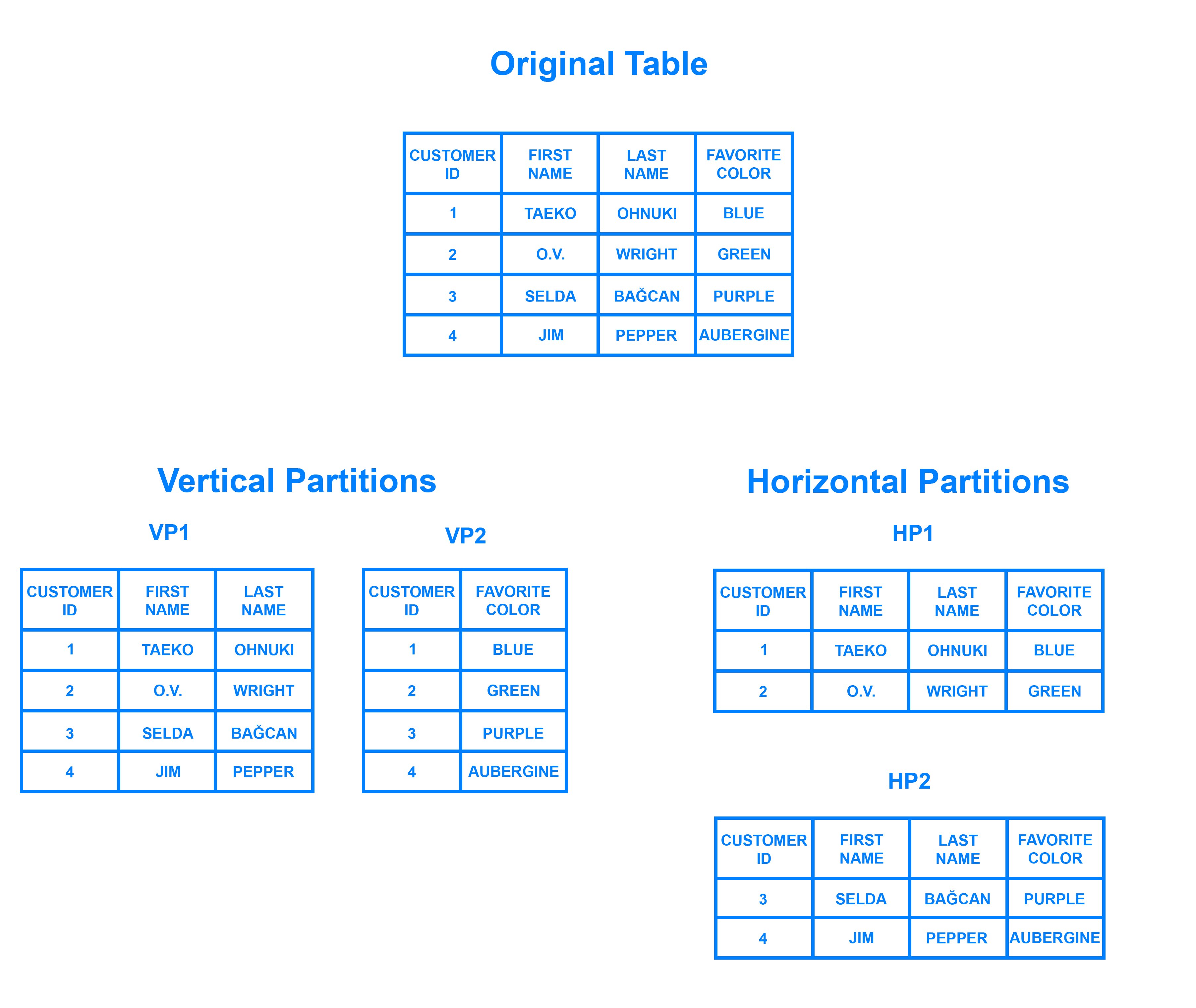
Partição envolve a divisão dos dados em dois ou mais pedaços menores, chamados estilhaços lógicos. Os fragmentos lógicos são então distribuídos por nós separados de bases de dados, referidos como fragmentos físicos, que podem conter múltiplos fragmentos lógicos. Apesar disto, os dados contidos em todos os fragmentos representam colectivamente todo um conjunto de dados lógicos.
Tocos de bases de dados exemplificam uma arquitectura de nada partilhado. Isto significa que os cacos são autónomos; não partilham nenhum dos mesmos dados ou recursos informáticos. Em alguns casos, contudo, pode fazer sentido replicar certas tabelas em cada fragmento para servir como tabelas de referência. Por exemplo, digamos que existe uma base de dados para uma aplicação que depende de taxas de conversão fixas para medições de peso. Ao replicar uma tabela contendo os dados necessários da taxa de conversão em cada estilhaço, ajudaria a garantir que todos os dados necessários para consultas são mantidos em cada estilhaço.
Operalmente, o estilhaço é implementado ao nível da aplicação, o que significa que a aplicação inclui código que define qual o estilhaço a transmitir lê e escreve. No entanto, alguns sistemas de gestão de bases de dados têm capacidades de fragmentação incorporadas, permitindo implementar a fragmentação directamente ao nível da base de dados.
Dada esta visão geral da fragmentação, passemos em revista alguns dos aspectos positivos e negativos associados a esta arquitectura de base de dados.
Benefícios da fragmentação
O principal apelo da fragmentação de uma base de dados é que ela pode ajudar a facilitar a escalada horizontal, também conhecida como scaling out. A escalada horizontal é a prática de adicionar mais máquinas a uma pilha existente, a fim de espalhar a carga e permitir mais tráfego e processamento mais rápido. Isto é frequentemente contrastado com a escalada vertical, também conhecida como escalada, que envolve a actualização do hardware de um servidor existente, normalmente adicionando mais RAM ou CPU.
É relativamente simples ter uma base de dados relacional a funcionar numa única máquina e escalá-la conforme necessário, actualizando os seus recursos informáticos. No entanto, em última análise, qualquer base de dados não distribuída será limitada em termos de armazenamento e potência computacional, pelo que ter a liberdade de escalar horizontalmente torna a sua configuração muito mais flexível.
Outra razão pela qual alguns poderão escolher uma arquitectura de base de dados fragmentada é para acelerar os tempos de resposta das consultas. Quando submete uma consulta numa base de dados que não tenha sido dividida, pode ter de procurar em cada linha da tabela que está a consultar antes de poder encontrar o conjunto de resultados que procura. Para um pedido com uma base de dados grande e monolítica, as consultas podem tornar-se proibitivamente lentas. No entanto, ao dividir uma tabela em múltiplas, as consultas têm de passar por menos filas e os seus conjuntos de resultados são devolvidos muito mais rapidamente.
Sharding também pode ajudar a tornar uma aplicação mais fiável, atenuando o impacto das interrupções. Se a sua aplicação ou sítio web depende de uma base de dados não guardada, uma paragem tem o potencial de tornar a aplicação inteira indisponível. No entanto, com uma base de dados fragmentada, é provável que uma paragem afecte apenas um fragmento. Mesmo que isto possa tornar algumas partes da aplicação ou website indisponíveis a alguns utilizadores, o impacto global seria ainda menor do que se toda a base de dados falhasse.
Drawbacks of Sharding
Embora o sharding de uma base de dados possa facilitar a escalada e melhorar o desempenho, também pode impor certas limitações. Aqui, discutiremos algumas delas e porque podem ser razões para evitar completamente o retalhamento.
A primeira dificuldade que as pessoas encontram com o retalhamento é a pura complexidade de implementar correctamente uma arquitectura de base de dados retalhada. Se for feita incorrectamente, há um risco significativo de que o processo de fragmentação possa levar à perda de dados ou à corrupção de tabelas. Mesmo quando feito correctamente, porém, é provável que o retalhamento tenha um grande impacto nos fluxos de trabalho da sua equipa. Em vez de aceder e gerir os dados a partir de um único ponto de entrada, os utilizadores devem gerir os dados em múltiplos locais de fragmentação, o que pode ser potencialmente perturbador para algumas equipas.
Um problema que os utilizadores por vezes encontram depois de terem fragmentado uma base de dados é que os fragmentos acabam por se tornar desequilibrados. A título de exemplo, digamos que tem uma base de dados com dois fragmentos separados, um para clientes cujos apelidos começam com as letras A a M e outro para aqueles cujos nomes começam com as letras N a Z. No entanto, a sua aplicação serve uma quantidade desmesurada de pessoas cujos apelidos começam com a letra G. Assim, o fragmento A-M acumula gradualmente mais dados do que o N-Z, fazendo com que a aplicação abrande e empata para uma parte significativa dos seus utilizadores. O fragmento de A-M tornou-se no que é conhecido como hotspot de base de dados. Neste caso, quaisquer benefícios da fragmentação da base de dados são cancelados pela lentidão e falhas. A base de dados teria provavelmente de ser reparada e reparada para permitir uma distribuição de dados mais uniforme.
Outra grande desvantagem é que uma vez que uma base de dados tenha sido repartida, pode ser muito difícil devolvê-la à sua arquitectura não reparada. Quaisquer cópias de segurança da base de dados feitas antes de ter sido destruída não incluirão dados escritos desde a partição. Consequentemente, a reconstrução da arquitectura original não guardada exigiria a fusão dos novos dados particionados com as antigas cópias de segurança ou, em alternativa, a transformação do BD particionado de volta num único BD, o que seria dispendioso e demorado.
Uma desvantagem final a considerar é que o fragmento não é suportado nativamente por todos os motores de bases de dados. Por exemplo, o PostgreSQL não inclui a partição automática como uma característica, embora seja possível particionar manualmente uma base de dados PostgreSQL. Há uma série de garfos Postgres que incluem o descasque automático, mas estes muitas vezes ficam por trás da última versão do PostgreSQL e carecem de certas outras características. Algumas tecnologias especializadas de base de dados – como o MySQL Cluster ou certos produtos de base de dados como serviço, como o Atlas MongoDB – incluem a partilha automática como uma característica, mas versões baunilha destes sistemas de gestão de base de dados não incluem. Devido a isto, a partilha requer frequentemente uma abordagem de “enrolar a sua própria”. Isto significa que a documentação para o retalhamento ou dicas para a resolução de problemas são muitas vezes difíceis de encontrar.
Estes são, naturalmente, apenas alguns problemas gerais a considerar antes do retalhamento. Pode haver muitos mais inconvenientes potenciais para o retalhamento de uma base de dados, dependendo do seu caso de utilização.
Agora que já cobrimos alguns dos inconvenientes e benefícios do retalhamento, iremos analisar algumas arquitecturas diferentes para bases de dados retalhadas.
Sharding Architectures
Após ter decidido fragmentar a sua base de dados, a próxima coisa a descobrir é como o fará. Ao executar consultas ou distribuir dados recebidos para tabelas ou bases de dados fragmentadas, é crucial que vá para o fragmento correcto. Caso contrário, poderá resultar na perda de dados ou em consultas dolorosamente lentas. Nesta secção, vamos rever algumas arquitecturas de fragmentação comuns, cada uma das quais usa um processo ligeiramente diferente para distribuir dados entre fragmentos.
fragmentação baseada em chaves
fragmentação baseada em chaves, também conhecida como fragmentação baseada em hash, envolve a utilização de um valor retirado de dados recentemente escritos – tal como o número de identificação de um cliente, o endereço IP de uma aplicação cliente, um código postal, etc. – e ligá-lo a uma função de hash para determinar a que fragmento os dados devem ir. Uma função hash é uma função que toma como entrada um pedaço de dados (por exemplo, um e-mail do cliente) e produz um valor discreto, conhecido como um valor hash. No caso de fragmentação, o valor de hash é uma identificação do fragmento utilizado para determinar em que fragmento os dados recebidos serão armazenados. No total, o processo assemelha-se a isto:

Para assegurar que as entradas são colocadas nos fragmentos correctos e de forma consistente, os valores introduzidos na função hash devem provir todos da mesma coluna. Esta coluna é conhecida como uma chave de estilhaço. Em termos simples, as chaves shard são semelhantes às chaves primárias na medida em que ambas são colunas que são utilizadas para estabelecer um identificador único para linhas individuais. Em termos gerais, uma chave de fragmento deve ser estática, o que significa que não deve conter valores que possam mudar com o tempo. Caso contrário, aumentaria a quantidade de trabalho que entra em operações de actualização, e poderia abrandar o desempenho.
Embora a fragmentação baseada em chaves seja uma arquitectura de fragmentação bastante comum, pode tornar as coisas complicadas ao tentar adicionar ou remover dinamicamente servidores adicionais a uma base de dados. Ao adicionar servidores, cada um precisará de um valor de hash correspondente e muitas das suas entradas existentes, se não todas, terão de ser remapeadas para o seu novo e correcto valor de hash e depois migradas para o servidor apropriado. Quando começar a reequilibrar os dados, nem as funções de hash novas nem as antigas serão válidas. Consequentemente, o seu servidor não será capaz de escrever quaisquer novos dados durante a migração e a sua aplicação poderá estar sujeita a paragens.
O principal apelo desta estratégia é que ela pode ser utilizada para distribuir os dados uniformemente de modo a evitar hotspots. Além disso, porque distribui algoritmos de dados, não há necessidade de manter um mapa de onde todos os dados estão localizados, como é necessário com outras estratégias como o sharding baseado em intervalos ou directórios.
Range Based Sharding
Range Based Sharding envolve o sharding de dados com base em intervalos de um dado valor. Para ilustrar, digamos que dispõe de uma base de dados que armazena informações sobre todos os produtos no catálogo de um retalhista. Poderia criar alguns fragmentos diferentes e dividir a informação de cada produto com base na gama de preços em que se enquadram, assim:

O principal benefício da fragmentação com base na gama é que é relativamente simples de implementar. Cada fragmento contém um conjunto diferente de dados, mas todos eles têm um esquema idêntico uns aos outros, bem como a base de dados original. O código da aplicação apenas lê em que gama os dados caem e escreve-os no fragmento correspondente.
Por outro lado, o fragmento baseado no intervalo não protege os dados de serem distribuídos desigualmente, levando aos pontos quentes da base de dados acima mencionados. Olhando para o diagrama de exemplo, mesmo que cada fragmento contenha uma quantidade igual de dados, as probabilidades são de que produtos específicos recebam mais atenção do que outros. Os seus respectivos fragmentos receberão, por sua vez, um número desproporcionado de leituras.
Sharding Baseado em Directório
Para implementar o shard based sharding, deve-se criar e manter uma tabela de pesquisa que utilize uma chave de caco para manter o registo de qual caco contém quais os dados. Em poucas palavras, uma tabela de pesquisa é uma tabela que contém um conjunto estático de informação sobre onde se podem encontrar dados específicos. O diagrama seguinte mostra um exemplo simplista de fragmentação baseada em directório:
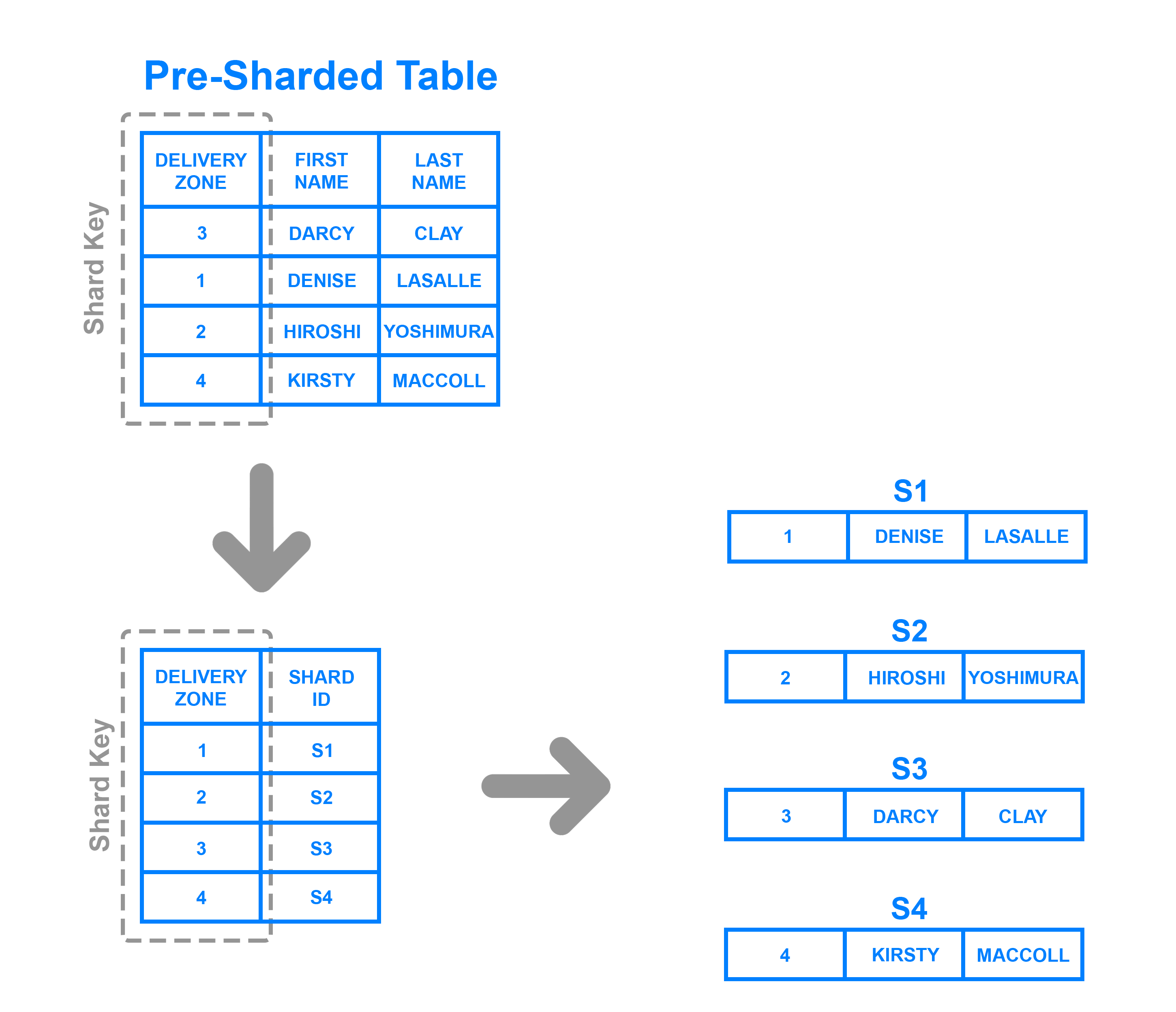
Aqui, a coluna Zona de Entrega é definida como uma chave de fragmento. Os dados da chave de estilhaço são escritos na tabela de pesquisa juntamente com qualquer estilhaço em que cada linha respectiva deve ser escrita. Isto é semelhante ao fragmento baseado no alcance, mas em vez de determinar em que alcance os dados da chave de fragmento caem, cada chave é ligada ao seu fragmento específico. A utilização de um fragmento baseado em directório é uma boa escolha em detrimento do fragmento baseado em gama, nos casos em que a chave do fragmento tem uma baixa cardinalidade e não faz sentido que um fragmento armazene uma gama de chaves. Note-se que também se distingue do estilhaçamento baseado em chaves na medida em que não processa a chave do estilhaço através de uma função hash; apenas verifica a chave contra uma tabela de pesquisa para ver onde os dados precisam de ser escritos.
A principal atracção do estilhaçamento baseado em directórios é a sua flexibilidade. As arquitecturas de fragmentação baseadas em gama limitam a especificação de gamas de valores, enquanto as baseadas em chave limitam a utilização de uma função de hash fixa que, como mencionado anteriormente, pode ser extremamente difícil de alterar mais tarde. O sharding baseado em directório, por outro lado, permite-lhe utilizar qualquer sistema ou algoritmo que pretenda atribuir entradas de dados ao shard, e é relativamente fácil adicionar dinamicamente shards usando esta abordagem.
Embora o sharding baseado em directório seja o mais flexível dos métodos de sharding aqui discutidos, a necessidade de ligação à tabela de pesquisa antes de cada consulta ou escrita pode ter um impacto prejudicial no desempenho de uma aplicação. Além disso, a tabela de pesquisa pode tornar-se um único ponto de falha: se se corromper ou falhar, pode ter impacto na capacidade de escrever novos dados ou aceder aos seus dados já existentes.
Should I Shard?
Se se deve ou não implementar uma arquitectura de base de dados fragmentada é quase sempre uma questão de debate. Alguns vêem o fragmento como um resultado inevitável para bases de dados que atingem um determinado tamanho, enquanto outros vêem-no como uma dor de cabeça que deve ser evitada a menos que seja absolutamente necessária, devido à complexidade operacional que o fragmento acrescenta.
Por causa desta complexidade acrescida, o retalhamento só é normalmente realizado quando se lida com quantidades muito grandes de dados. Aqui estão alguns cenários comuns onde pode ser benéfico fragmentar uma base de dados:
- A quantidade de dados da aplicação cresce para exceder a capacidade de armazenamento de um único nó de base de dados.
- O volume de escritos ou leituras para a base de dados ultrapassa o que um único nó ou as suas réplicas lidas podem tratar, resultando em tempos de resposta lentos ou timeouts.
- A largura de banda de rede requerida pela aplicação ultrapassa a largura de banda disponível para um único nó de base de dados e quaisquer réplicas lidas, resultando em tempos de resposta ou timeouts lentos.
p> Antes de se desfazer, deve esgotar todas as outras opções para optimizar a sua base de dados. Algumas optimizações que poderá querer considerar incluem:
- Configurar uma base de dados remota. Se estiver a trabalhar com uma aplicação monolítica em que todos os seus componentes residem no mesmo servidor, pode melhorar o desempenho da sua base de dados, movendo-a para a sua própria máquina. Isto não acrescenta tanta complexidade como a fragmentação, uma vez que as tabelas da base de dados permanecem intactas. Contudo, permite-lhe ainda escalar verticalmente a sua base de dados à parte do resto da sua infra-estrutura.
- Implementar o cache. Se o desempenho de leitura da sua aplicação é o que lhe está a causar problemas, o caching é uma estratégia que pode ajudar a melhorá-la. O cache envolve o armazenamento temporário de dados que já foram solicitados na memória, permitindo-lhe aceder muito mais rapidamente mais tarde.
- Criar uma ou mais réplicas lidas. Outra estratégia que pode ajudar a melhorar o desempenho de leitura, envolve copiar os dados de um servidor de base de dados (o servidor primário) para um ou mais servidores secundários. Depois disto, cada nova escrita vai para o primário antes de ser copiada para os secundários, enquanto as leituras são feitas exclusivamente para os servidores secundários. A distribuição de leituras e escritas desta forma evita que qualquer máquina assuma demasiada carga, ajudando a evitar lentidão e falhas. Note-se que a criação de réplicas lidas envolve mais recursos informáticos e, portanto, custa mais dinheiro, o que poderia ser um constrangimento significativo para alguns.
- Actualizar para um servidor maior. Na maioria dos casos, a ampliação do servidor de base de dados para uma máquina com mais recursos requer menos esforço do que a fragmentação. Tal como na criação de réplicas lidas, um servidor actualizado com mais recursos irá provavelmente custar mais dinheiro. Consequentemente, só deverá avançar com o redimensionamento se este acabar por ser verdadeiramente a sua melhor opção.
P>Tenham em mente que se a sua aplicação ou website crescer para além de um certo ponto, nenhuma destas estratégias será suficiente para melhorar o desempenho por si só. Em tais casos, a partilha pode de facto ser a melhor opção para si.
Conclusão
A partilha pode ser uma grande solução para aqueles que procuram escalar a sua base de dados horizontalmente. Contudo, também acrescenta uma grande complexidade e cria mais pontos de falha potenciais para a sua aplicação. A partilha pode ser necessária para alguns, mas o tempo e os recursos necessários para criar e manter uma arquitectura fragmentada pode superar os benefícios para outros.
Ao ler este artigo conceptual, deverá ter uma compreensão mais clara dos prós e contras da fragmentação. Seguindo em frente, pode usar esta percepção para tomar uma decisão mais informada sobre se uma arquitectura de base de dados fragmentada é ou não adequada para a sua aplicação.