Se ainda não está familiarizado com Modelos Baseados em Árvores no Aprendizado Mecânico, deve dar uma vista de olhos ao nosso curso de R sobre o assunto.
O Algoritmo de Florestas Aleatórias
Vamos compreender o algoritmo em termos de leigos. Suponha que quer fazer uma viagem e gostaria de viajar para um lugar de que vai gostar.
Então o que fazer para encontrar um lugar de que vai gostar? Pode pesquisar online, ler críticas em blogs e portais de viagens, ou pode também perguntar aos seus amigos.
P>Ponhamos que decidiu perguntar aos seus amigos, e falar com eles sobre a sua experiência de viagem passada a vários lugares. Receberá algumas recomendações de todos os seus amigos. Agora tem de fazer uma lista desses lugares recomendados. Depois, pede-lhes para votar (ou seleccionar um dos melhores lugares para a viagem) a partir da lista de lugares recomendados que fez. O lugar com o maior número de votos será a sua escolha final para a viagem.
No processo de decisão acima referido, existem duas partes. Primeiro, perguntar aos seus amigos sobre a sua experiência de viagem individual e obter uma recomendação a partir de vários lugares que visitaram. Esta parte é como utilizar o algoritmo da árvore de decisão. Aqui, cada amigo faz uma selecção dos lugares que visitou até agora.
A segunda parte, depois de recolher todas as recomendações, é o procedimento de votação para seleccionar o melhor lugar na lista de recomendações. Todo este processo de obter recomendações de amigos e votar neles para encontrar o melhor lugar é conhecido como o algoritmo das florestas aleatórias.
É tecnicamente um método de conjunto (baseado na abordagem dividir e conquistar) de árvores de decisão geradas num conjunto de dados divididos aleatoriamente. Esta colecção de classificadores de árvores de decisão é também conhecida como a floresta. As árvores de decisão individuais são geradas utilizando um indicador de selecção de atributos, tal como ganho de informação, rácio de ganho, e índice de Gini para cada atributo. Cada árvore depende de uma amostra aleatória independente. Num problema de classificação, cada árvore vota e a classe mais popular é escolhida como o resultado final. Em caso de regressão, a média de todos os resultados das árvores é considerada como o resultado final. É mais simples e mais potente em comparação com outros algoritmos de classificação não-lineares.
Como funciona o algoritmo?
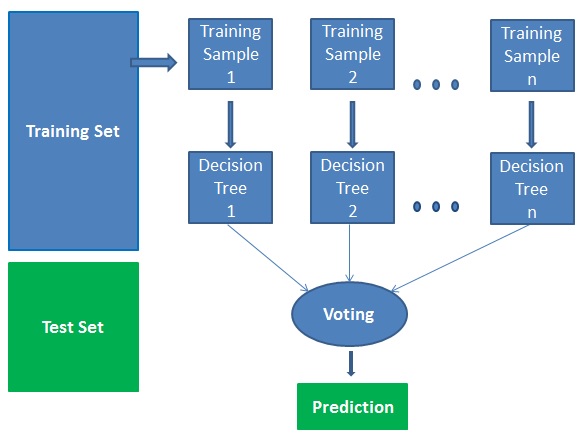
Funciona em quatro passos:
- Seleccionar amostras aleatórias de um dado conjunto de dados.
- Construir uma árvore de decisão para cada amostra e obter um resultado de previsão de cada árvore de decisão.
- Executar um voto para cada resultado previsto.
- Seleccionar o resultado da previsão com o maior número de votos como a previsão final.
Vantagens:
- Florestas aleatórias é considerado como um método altamente preciso e robusto devido ao número de árvores de decisão que participam no processo.
- Não sofre do problema de sobreajustamento. A principal razão é que toma a média de todas as previsões, o que anula os vieses.
- O algoritmo pode ser utilizado tanto em problemas de classificação como de regressão.
- As florestas aleatórias também podem lidar com valores em falta. Há duas maneiras de lidar com estes: utilizando valores medianos para substituir variáveis contínuas, e calculando a média próxima ponderada dos valores em falta.
- Pode obter a importância relativa das características, o que ajuda na selecção das características que mais contribuem para o classificador.
Desvantagens:
- Florestas aleatórias é lento na geração de previsões porque tem múltiplas árvores de decisão. Sempre que faz uma previsão, todas as árvores da floresta têm de fazer uma previsão para o mesmo input dado e depois realizar uma votação sobre o mesmo. Todo este processo consome muito tempo.
- O modelo é difícil de interpretar em comparação com uma árvore de decisão, onde se pode facilmente tomar uma decisão seguindo o caminho na árvore.
Encontrar características importantes
Florestas aleatórias também oferece um bom indicador de selecção de características. Scikit-learn fornece uma variável extra com o modelo, que mostra a importância relativa ou contribuição de cada característica na previsão. Calcula automaticamente a pontuação de relevância de cada característica na fase de formação. Em seguida, escala a relevância para baixo para que a soma de todas as pontuações seja 1,
Esta pontuação irá ajudá-lo a escolher as características mais importantes e a largar as menos importantes para a construção do modelo.
Florestas aleatórias utilizam a importância do gini ou a diminuição média da impureza (MDI) para calcular a importância de cada característica. A importância do gini é também conhecida como a diminuição total da impureza do nó. Isto é o quanto o modelo se ajusta ou a precisão diminui quando se deixa cair uma variável. Quanto maior for o decréscimo, mais significativa é a variável. Aqui, o decréscimo médio é um parâmetro significativo para a selecção da variável. O índice de Gini pode descrever o poder explicativo global das variáveis.
Florestas aleatórias vs Árvores de decisão
- Florestas aleatórias é um conjunto de árvores de decisão múltipla.
- As árvores de decisão aleatória podem sofrer de sobreajustamento, mas as florestas aleatórias previnem o sobreajustamento criando árvores em subconjuntos aleatórios.
- As árvores de decisão são computacionalmente mais rápidas.
- As florestas aleatórias são difíceis de interpretar, enquanto que uma árvore de decisão é facilmente interpretável e pode ser convertida em regras.
Construir um Classificador usando Scikit-learn
Vais construir um modelo no conjunto de dados de flores da íris, que é um conjunto de classificação muito famoso. Compreende o comprimento da sépala, largura da sépala, comprimento das pétalas, largura das pétalas, e tipo de flores. Existem três espécies ou classes: setosa, versicolor, e virgínia. Constrói-se um modelo para classificar o tipo de flor. O conjunto de dados está disponível na biblioteca scikit-learn, ou pode descarregá-lo do Repositório de Aprendizagem da Máquina UCI.
p>Iniciar importando a biblioteca de conjuntos de dados de scikit-learn, e carregar o conjunto de dados da íris comload_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Pode imprimir o alvo e os nomes das características, para se certificar de que tem o conjunto de dados correcto, como tal:
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)É uma boa ideia explorar sempre um pouco os seus dados, para que saiba com o que está a trabalhar. Aqui, pode ver as primeiras cinco linhas do conjunto de dados impressas, assim como a variável alvo para todo o conjunto de dados.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Aqui, pode criar uma DataFrame do conjunto de dados da íris da seguinte forma.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| sepal comprimento | sepal largura | espécie | |||
|---|---|---|---|---|---|
| 0 | 1.4 | 0.2 | 5.1 | 3.5 | 0 |
| 1 | 1.4 | 0.2 | 4.9 | 3.0 | 0 |
| 2 | 1.3 | 0.2 | 4.7 | 3.2 | 0 |
| 3 | 1.5 | 0.2 | 4.6 | 3.1 | 0 |
| 4 | 1.4 | 0.2 | 5.0 | 3.6 | 0 |
First, separa-se as colunas em variáveis dependentes e independentes (ou características e rótulos). Em seguida, divide essas variáveis num conjunto de treino e teste.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testApós a divisão, irá treinar o modelo no conjunto de treino e realizar previsões no conjunto de teste.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Após o treino, verificar a precisão utilizando valores reais e previstos.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)Também se pode fazer uma previsão para um único item, por exemplo:
- comprimento do pé = 3
- largura do pé = 5
- comprimento do pé = 4
- largura do pé = 2
Agora é possível prever que tipo de flor é.
clf.predict(])array()Aqui, 2 indica o tipo de flor Virginica.
Finding Important Features in Scikit-learn
Aqui, está a encontrar características importantes ou a seleccionar características no conjunto de dados IRIS. Em scikit-learn, pode realizar esta tarefa nos seguintes passos:
- Primeiro, precisa de criar um modelo de florestas aleatórias.
- Segundo, use a variável de importância de características para ver as pontuações de importância de características.
- Terceiro, visualize estas pontuações usando a biblioteca do mar.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64P>Pode também visualizar a importância da característica. As visualizações são fáceis de compreender e interpretáveis.
Para a visualização, pode usar uma combinação de matplotlib e seaborn. Uma vez que o seaborn é construído em cima da matplotlib, oferece uma série de temas personalizados e fornece tipos de parcelas adicionais. O matplotlib é um super conjunto de seabornos e ambos são igualmente importantes para boas visualizações.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()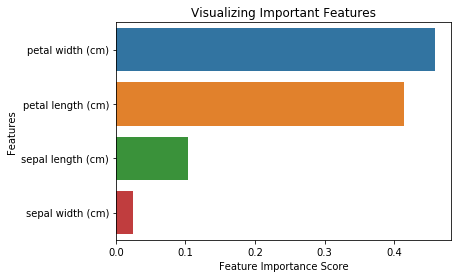
Gerar o modelo em características seleccionadas
Aqui, pode remover a característica “largura sépala” porque tem uma importância muito baixa, e seleccionar as 3 características restantes.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testApós a divisão, será gerado um modelo sobre as características seleccionadas do conjunto de treino, serão feitas previsões sobre as características seleccionadas do conjunto de teste, e comparar-se-ão os valores reais e previstos.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Vê-se que depois de remover as características menos importantes (comprimento sépala), a precisão aumentou. Isto deve-se ao facto de ter removido dados e ruído enganadores, resultando numa maior exactidão. Uma menor quantidade de características também reduz o tempo de treino.
Conclusão
Congratulações, chegou ao fim deste tutorial!
Neste tutorial, aprendeu o que são florestas aleatórias, como funciona, encontrando características importantes, a comparação entre florestas aleatórias e árvores de decisão, vantagens e desvantagens. Aprendeu também a construir modelos, a avaliar e a encontrar características importantes em scikit-learn. B
Se quiser aprender mais sobre a aprendizagem de máquinas, recomendo que dê uma vista de olhos à nossa aprendizagem supervisionada em R: Curso de classificação.