Introduzione
Ogni applicazione o sito web che vede una crescita significativa alla fine avrà bisogno di scalare per ospitare l’aumento del traffico. Per le applicazioni e i siti web basati sui dati, è fondamentale che la scalabilità sia fatta in modo da garantire la sicurezza e l’integrità dei dati. Può essere difficile prevedere quanto popolare diventerà un sito web o un’applicazione o per quanto tempo manterrà tale popolarità, ed è per questo che alcune organizzazioni scelgono un’architettura di database che permette loro di scalare i loro database dinamicamente.
In questo articolo concettuale, discuteremo una tale architettura di database: i database sharded. Lo sharding ha ricevuto molta attenzione negli ultimi anni, ma molti non hanno una chiara comprensione di cosa sia o degli scenari in cui potrebbe avere senso shardare un database. Esamineremo cos’è lo sharding, alcuni dei suoi principali benefici e svantaggi, e anche alcuni metodi comuni di sharding.
Che cos’è lo sharding?
Sharding è un modello di architettura di database legato al partizionamento orizzontale – la pratica di separare le righe di una tabella in più tabelle diverse, note come partizioni. Ogni partizione ha lo stesso schema e le stesse colonne, ma anche righe completamente diverse. Allo stesso modo, i dati contenuti in ciascuna sono unici e indipendenti dai dati contenuti nelle altre partizioni.
Può essere utile pensare al partizionamento orizzontale in termini di come è collegato al partizionamento verticale. In una tabella partizionata verticalmente, intere colonne sono separate e messe in nuove tabelle distinte. I dati contenuti in una partizione verticale sono indipendenti dai dati in tutte le altre, e ciascuna contiene sia righe che colonne distinte. Il seguente diagramma illustra come una tabella possa essere partizionata sia orizzontalmente che verticalmente:
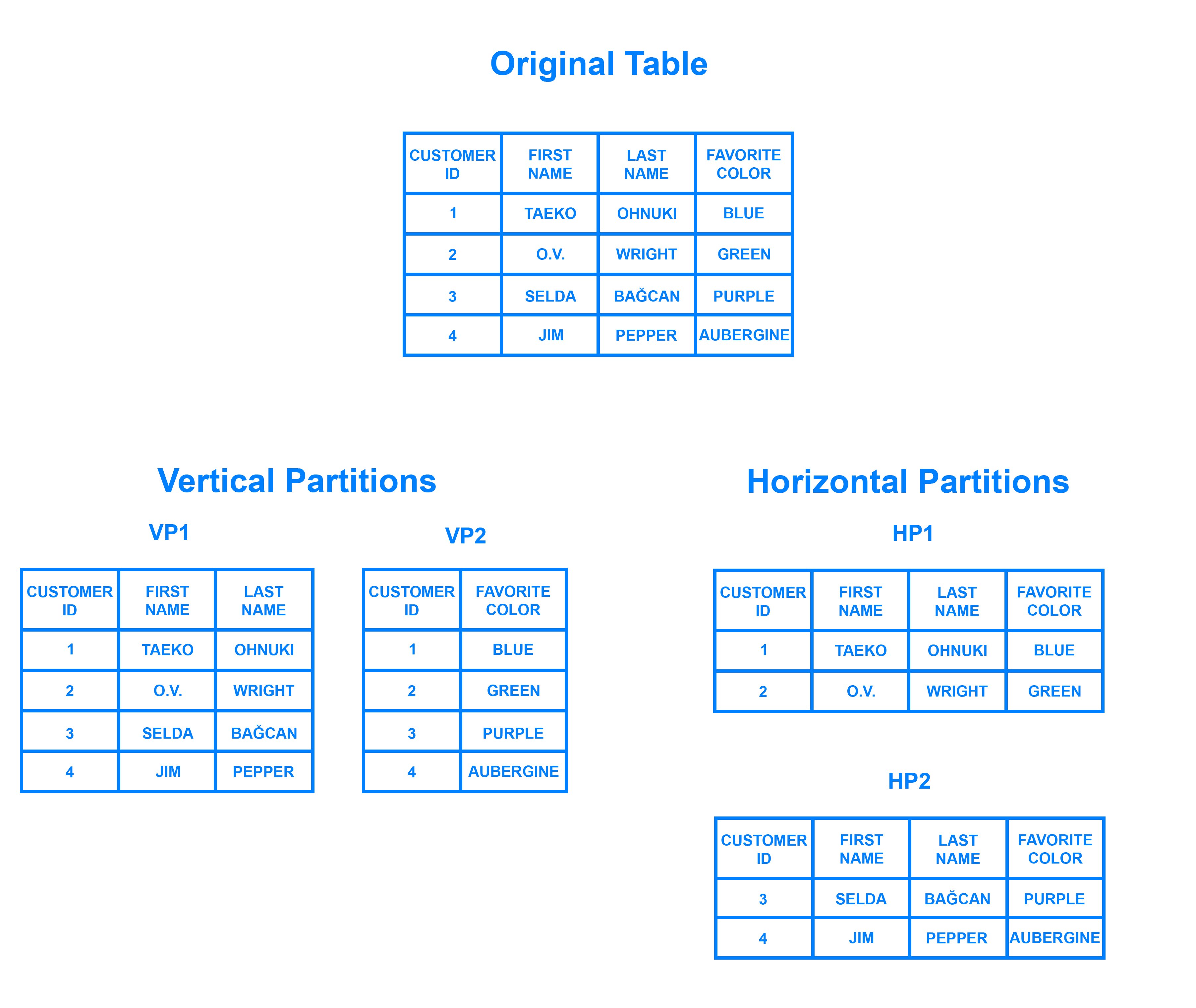
Sharding implica la suddivisione dei dati in due o più partizioni più piccole, chiamate frammenti logici. I frammenti logici sono poi distribuiti su nodi di database separati, chiamati frammenti fisici, che possono contenere più frammenti logici. Nonostante questo, i dati contenuti in tutti i frammenti rappresentano collettivamente un intero set di dati logici.
I frammenti di database esemplificano un’architettura shared-nothing. Questo significa che i frammenti sono autonomi; non condividono nessuno degli stessi dati o risorse di calcolo. In alcuni casi, tuttavia, può avere senso replicare alcune tabelle in ogni shard per servire come tabelle di riferimento. Per esempio, diciamo che c’è un database per un’applicazione che dipende da tassi di conversione fissi per le misure di peso. Replicando una tabella contenente i dati necessari per i tassi di conversione in ogni shard, aiuterebbe a garantire che tutti i dati richiesti per le query siano tenuti in ogni shard.
Spesso, lo sharding è implementato a livello di applicazione, il che significa che l’applicazione include il codice che definisce a quale shard trasmettere letture e scritture. Tuttavia, alcuni sistemi di gestione di database hanno capacità di sharding incorporate, permettendo di implementare lo sharding direttamente a livello di database.
Data questa panoramica generale dello sharding, esaminiamo alcuni degli aspetti positivi e negativi associati a questa architettura di database.
Benefici dello sharding
Il fascino principale dello sharding di un database è che può aiutare a facilitare lo scaling orizzontale, noto anche come scaling out. Lo scaling orizzontale è la pratica di aggiungere più macchine ad uno stack esistente per distribuire il carico e permettere più traffico e un’elaborazione più veloce. Questo è spesso in contrasto con lo scaling verticale, altrimenti noto come scaling up, che comporta l’aggiornamento dell’hardware di un server esistente, di solito aggiungendo più RAM o CPU.
È relativamente semplice avere un database relazionale in esecuzione su una singola macchina e scalarlo come necessario aggiornando le sue risorse di calcolo. In definitiva, però, qualsiasi database non distribuito sarà limitato in termini di memoria e potenza di calcolo, quindi avere la libertà di scalare orizzontalmente rende la vostra configurazione molto più flessibile.
Un’altra ragione per cui alcuni potrebbero scegliere un’architettura di database sharded è per accelerare i tempi di risposta delle query. Quando si invia una query su un database che non è stato shardato, potrebbe dover cercare ogni riga nella tabella che si sta interrogando prima di trovare il set di risultati che si sta cercando. Per un’applicazione con un grande database monolitico, le query possono diventare proibitivamente lente. Con lo sharding di una tabella in più, però, le query devono passare su meno righe e i loro set di risultati vengono restituiti molto più rapidamente.
Sharding può anche aiutare a rendere un’applicazione più affidabile, mitigando l’impatto delle interruzioni. Se la vostra applicazione o sito web si basa su un database non shardato, un’interruzione ha il potenziale di rendere l’intera applicazione non disponibile. Con un database sharded, invece, è probabile che un’interruzione colpisca solo un singolo shard. Anche se questo potrebbe rendere alcune parti dell’applicazione o del sito web non disponibili per alcuni utenti, l’impatto complessivo sarebbe comunque inferiore a quello di un crash dell’intero database.
Gli svantaggi dello sharding
Mentre lo sharding di un database può facilitare lo scaling e migliorare le prestazioni, può anche imporre alcune limitazioni. Qui discuteremo alcune di queste e perché potrebbero essere ragioni per evitare del tutto lo sharding.
La prima difficoltà che le persone incontrano con lo sharding è la pura complessità di implementare correttamente un’architettura di database sharded. Se fatto in modo non corretto, c’è un rischio significativo che il processo di sharding possa portare alla perdita di dati o a tabelle corrotte. Anche quando è fatto correttamente, però, lo sharding ha probabilmente un impatto importante sui flussi di lavoro del tuo team. Invece di accedere e gestire i propri dati da un unico punto di ingresso, gli utenti devono gestire i dati attraverso più posizioni di shard, il che potrebbe essere potenzialmente dirompente per alcuni team.
Un problema che gli utenti a volte incontrano dopo aver shardato un database è che gli shard alla fine diventano sbilanciati. Per esempio, diciamo che avete un database con due shard separati, uno per i clienti i cui cognomi iniziano con le lettere da A a M e un altro per quelli i cui nomi iniziano con le lettere da N a Z. Tuttavia, la vostra applicazione serve una quantità spropositata di persone i cui cognomi iniziano con la lettera G. Di conseguenza, lo shard A-M accumula gradualmente più dati di quello N-Z, causando il rallentamento e lo stallo dell’applicazione per una parte significativa dei vostri utenti. Lo shard A-M è diventato quello che è conosciuto come un hotspot di database. In questo caso, qualsiasi beneficio dello sharding del database è annullato dai rallentamenti e dai crash. Il database avrebbe probabilmente bisogno di essere riparato e rehardato per permettere una distribuzione dei dati più uniforme.
Un altro grande svantaggio è che una volta che un database è stato shardato, può essere molto difficile riportarlo alla sua architettura non shardata. Qualsiasi backup del database fatto prima che fosse shardato non includerà i dati scritti dopo il partizionamento. Di conseguenza, ricostruire l’architettura originale non suddivisa richiederebbe la fusione dei nuovi dati partizionati con i vecchi backup o, in alternativa, la trasformazione del DB suddiviso in un singolo DB, entrambi i quali sarebbero sforzi costosi e lunghi.
Un ultimo svantaggio da considerare è che lo sharding non è supportato nativamente da ogni motore di database. Per esempio, PostgreSQL non include lo sharding automatico come caratteristica, sebbene sia possibile shardare manualmente un database PostgreSQL. Ci sono un certo numero di fork di Postgres che includono lo sharding automatico, ma questi spesso rimangono indietro rispetto all’ultima versione di PostgreSQL e mancano di alcune altre caratteristiche. Alcune tecnologie di database specializzate – come MySQL Cluster o certi prodotti database-as-a-service come MongoDB Atlas – includono lo sharding automatico come caratteristica, ma le versioni vanilla di questi sistemi di gestione di database non lo fanno. A causa di questo, lo sharding spesso richiede un approccio “roll your own”. Questo significa che la documentazione per lo sharding o i suggerimenti per la risoluzione dei problemi sono spesso difficili da trovare.
Queste sono, naturalmente, solo alcune questioni generali da considerare prima dello sharding. Ci possono essere molti altri potenziali svantaggi nello sharding di un database, a seconda del suo caso d’uso.
Ora che abbiamo coperto alcuni degli svantaggi e dei benefici dello sharding, esamineremo alcune diverse architetture per i database shardati.
Architetture di sharding
Una volta che avete deciso di shardare il vostro database, la prossima cosa che dovete capire è come lo farete. Quando si eseguono query o si distribuiscono dati in entrata alle tabelle o ai database shardati, è fondamentale che vadano allo shard corretto. Altrimenti, potrebbe risultare in dati persi o in query dolorosamente lente. In questa sezione, esamineremo alcune architetture di sharding comuni, ognuna delle quali utilizza un processo leggermente diverso per distribuire i dati tra gli shard.
Key Based Sharding
Lo sharding basato sulla chiave, noto anche come sharding basato sull’hash, comporta l’utilizzo di un valore preso dai dati appena scritti – come il numero ID di un cliente, l’indirizzo IP di un’applicazione client, un codice postale, ecc – e lo inserisce in una funzione hash per determinare a quale shard i dati dovrebbero andare. Una funzione hash è una funzione che prende come input un pezzo di dati (per esempio, un’e-mail di un cliente) e produce un valore discreto, noto come valore hash. Nel caso dello sharding, il valore di hash è uno shard ID usato per determinare su quale shard i dati in arrivo saranno memorizzati. Complessivamente, il processo assomiglia a questo:

Per assicurare che le voci siano collocate negli shard corretti e in modo coerente, i valori inseriti nella funzione hash dovrebbero provenire tutti dalla stessa colonna. Questa colonna è nota come chiave di shard. In termini semplici, le chiavi di shard sono simili alle chiavi primarie in quanto entrambe sono colonne che vengono utilizzate per stabilire un identificatore unico per le singole righe. In generale, una chiave shard dovrebbe essere statica, cioè non dovrebbe contenere valori che potrebbero cambiare nel tempo. Altrimenti, aumenterebbe la quantità di lavoro che va nelle operazioni di aggiornamento, e potrebbe rallentare le prestazioni.
Mentre lo sharding basato sulle chiavi è un’architettura di sharding abbastanza comune, può rendere le cose complicate quando si cerca di aggiungere o rimuovere dinamicamente server aggiuntivi ad un database. Man mano che si aggiungono server, ognuno avrà bisogno di un valore di hash corrispondente e molte delle voci esistenti, se non tutte, dovranno essere rimappate al loro nuovo e corretto valore di hash e poi migrate al server appropriato. Mentre iniziate a riequilibrare i dati, né le nuove né le vecchie funzioni di hashing saranno valide. Di conseguenza, il vostro server non sarà in grado di scrivere nuovi dati durante la migrazione e la vostra applicazione potrebbe essere soggetta a downtime.
L’attrattiva principale di questa strategia è che può essere usata per distribuire uniformemente i dati in modo da prevenire gli hotspot. Inoltre, poiché distribuisce i dati in modo algoritmico, non c’è bisogno di mantenere una mappa di dove si trovano tutti i dati, come è necessario con altre strategie come range o directory based sharding.
Range Based Sharding
Range based sharding coinvolge lo sharding dei dati basato su range di un dato valore. Per illustrare, diciamo che avete un database che memorizza informazioni su tutti i prodotti all’interno del catalogo di un rivenditore. Si potrebbero creare diversi shard e dividere le informazioni di ogni prodotto in base all’intervallo di prezzo in cui rientrano, in questo modo:

Il principale vantaggio dello sharding basato sull’intervallo è che è relativamente semplice da implementare. Ogni shard contiene un diverso insieme di dati, ma tutti hanno uno schema identico all’altro, così come il database originale. Il codice dell’applicazione legge semplicemente in quale intervallo rientrano i dati e li scrive nello shard corrispondente.
D’altra parte, lo sharding basato sui range non protegge i dati dall’essere distribuiti in modo non uniforme, portando ai suddetti hotspot del database. Guardando il diagramma di esempio, anche se ogni shard contiene una quantità uguale di dati, è probabile che alcuni prodotti riceveranno più attenzione di altri. I loro rispettivi shard, a loro volta, riceveranno un numero sproporzionato di letture.
Directory Based Sharding
Per implementare lo sharding basato su directory, si deve creare e mantenere una tabella di ricerca che usa una chiave shard per tenere traccia di quale shard contiene quali dati. In poche parole, una tabella di lookup è una tabella che contiene un insieme statico di informazioni su dove possono essere trovati dati specifici. Il seguente diagramma mostra un esempio semplicistico di sharding basato su directory:
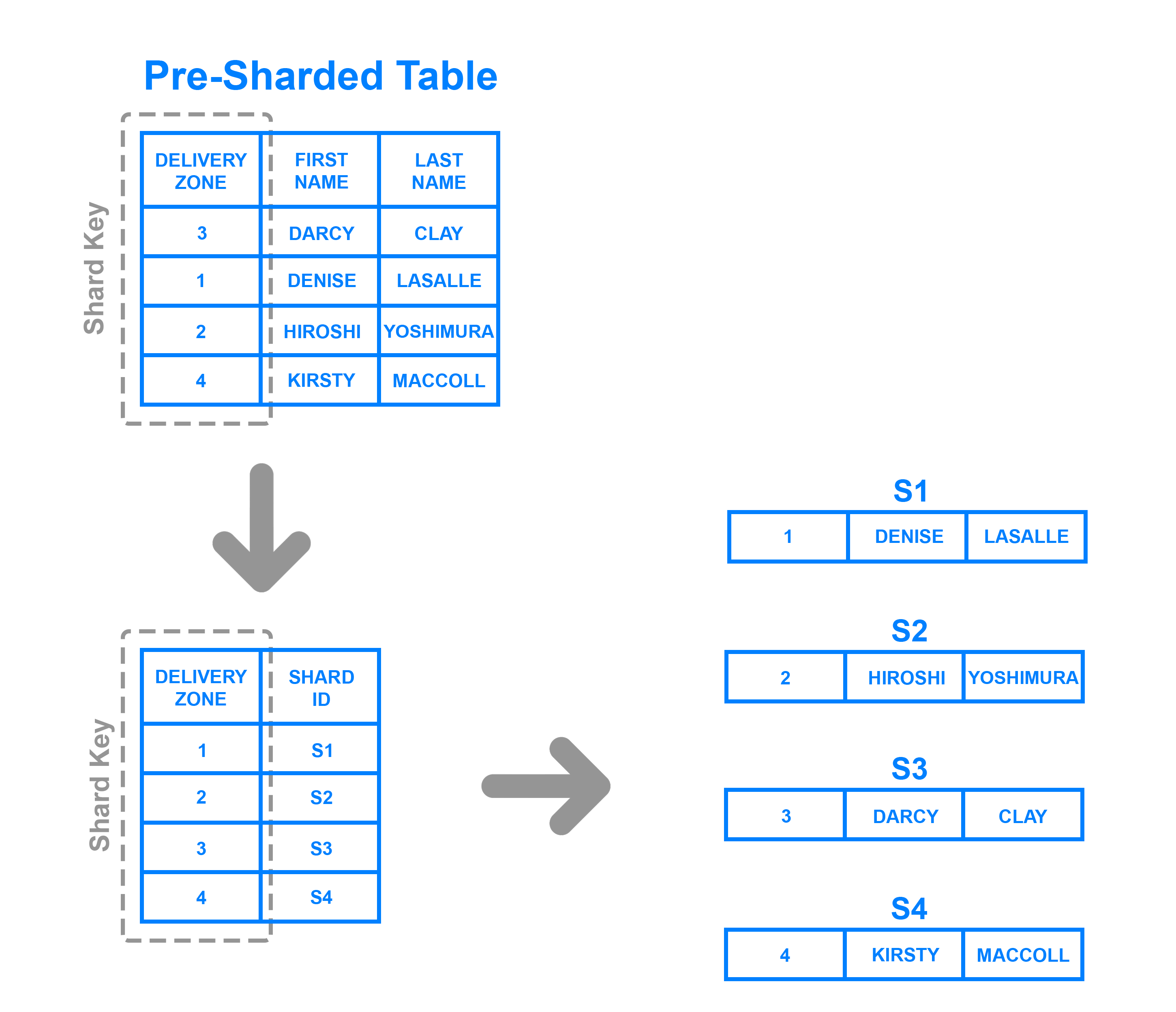
Qui, la colonna Delivery Zone è definita come una chiave shard. I dati della chiave shard vengono scritti nella tabella di lookup insieme a qualsiasi shard in cui ogni rispettiva riga dovrebbe essere scritta. Questo è simile allo sharding basato sull’intervallo, ma invece di determinare in quale intervallo rientrano i dati della chiave shard, ogni chiave è legata al suo specifico shard. Lo sharding basato sulla directory è una buona scelta rispetto allo sharding basato sull’intervallo nei casi in cui la chiave dello shard ha una bassa cardinalità e non ha senso che uno shard memorizzi un intervallo di chiavi. Si noti che è anche distinto dallo sharding basato sulle chiavi in quanto non elabora la chiave dello shard attraverso una funzione di hash; controlla solo la chiave rispetto ad una tabella di ricerca per vedere dove i dati devono essere scritti.
La principale attrattiva dello sharding basato sulle directory è la sua flessibilità. Le architetture di sharding basate su intervalli limitano l’utente a specificare intervalli di valori, mentre quelle basate su chiavi limitano l’uso di una funzione hash fissa che, come detto in precedenza, può essere estremamente difficile da cambiare in seguito. Lo sharding basato sulle directory, d’altra parte, permette di usare qualsiasi sistema o algoritmo si voglia per assegnare i dati agli shard, ed è relativamente facile aggiungere dinamicamente shard usando questo approccio.
Mentre lo sharding basato sulle directory è il più flessibile dei metodi di sharding discussi qui, la necessità di connettersi alla tabella di ricerca prima di ogni query o scrittura può avere un impatto negativo sulle prestazioni di un’applicazione. Inoltre, la tabella di lookup può diventare un singolo punto di fallimento: se si corrompe o fallisce in altro modo, può avere un impatto sulla capacità di scrivere nuovi dati o accedere ai dati esistenti.
Devo shardare?
Se si debba o meno implementare un’architettura di database shardata è quasi sempre una questione di dibattito. Alcuni vedono lo sharding come un risultato inevitabile per i database che raggiungono una certa dimensione, mentre altri lo vedono come un mal di testa che dovrebbe essere evitato a meno che non sia assolutamente necessario, a causa della complessità operativa che lo sharding aggiunge.
A causa di questa complessità aggiunta, lo sharding viene solitamente eseguito solo quando si ha a che fare con quantità molto grandi di dati. Ecco alcuni scenari comuni in cui può essere vantaggioso shardare un database:
- La quantità di dati dell’applicazione cresce fino a superare la capacità di memorizzazione di un singolo nodo del database.
- Il volume di scrittura o lettura del database supera quello che un singolo nodo o le sue repliche di lettura possono gestire, con conseguente rallentamento dei tempi di risposta o timeout.
- La larghezza di banda di rete richiesta dall’applicazione supera la larghezza di banda disponibile per un singolo nodo del database e per qualsiasi replica di lettura, con conseguente rallentamento dei tempi di risposta o timeout.
Prima di shardare, dovresti esaurire tutte le altre opzioni per ottimizzare il tuo database. Alcune ottimizzazioni che potreste voler considerare includono:
- Impostare un database remoto. Se state lavorando con un’applicazione monolitica in cui tutti i suoi componenti risiedono sullo stesso server, potete migliorare le prestazioni del vostro database spostandolo sulla propria macchina. Questo non aggiunge tanta complessità quanto lo sharding, poiché le tabelle del database rimangono intatte. Tuttavia, ti permette ancora di scalare verticalmente il tuo database separandolo dal resto della tua infrastruttura.
- Implementare il caching. Se le prestazioni di lettura della vostra applicazione vi causano problemi, il caching è una strategia che può aiutarvi a migliorarle. Il caching consiste nel memorizzare temporaneamente i dati che sono già stati richiesti in memoria, permettendovi di accedervi molto più rapidamente in seguito.
- Creare una o più repliche di lettura. Un’altra strategia che può aiutare a migliorare le prestazioni di lettura, questa consiste nel copiare i dati da un server di database (il server primario) su uno o più server secondari. In seguito, ogni nuova scrittura va sul primario prima di essere copiata sui secondari, mentre le letture vengono effettuate esclusivamente sui server secondari. Distribuendo le letture e le scritture in questo modo si evita che una sola macchina prenda troppo carico, aiutando a prevenire rallentamenti e crash. Si noti che la creazione di repliche di lettura coinvolge più risorse di calcolo e quindi costa di più, il che potrebbe essere un vincolo significativo per alcuni.
- Aggiornamento a un server più grande. Nella maggior parte dei casi, scalare il proprio server di database ad una macchina con più risorse richiede meno sforzo dello sharding. Come per la creazione di repliche di lettura, un server aggiornato con più risorse probabilmente costerà di più. Di conseguenza, dovreste andare avanti con il ridimensionamento solo se finisce per essere la vostra migliore opzione.
Tenete a mente che se la vostra applicazione o sito web cresce oltre un certo punto, nessuna di queste strategie sarà sufficiente a migliorare le prestazioni da sola. In questi casi, lo sharding può davvero essere l’opzione migliore per voi.
Conclusione
Sharding può essere una grande soluzione per coloro che cercano di scalare il loro database orizzontalmente. Tuttavia, aggiunge anche una grande quantità di complessità e crea più punti di potenziale fallimento per la vostra applicazione. Lo sharding può essere necessario per alcuni, ma il tempo e le risorse necessarie per creare e mantenere un’architettura sharded potrebbero superare i benefici per altri.
Leggendo questo articolo concettuale, dovreste avere una comprensione più chiara dei pro e dei contro dello sharding. Andando avanti, potete usare queste informazioni per prendere una decisione più informata sul fatto che un’architettura di database sharded sia giusta o meno per la vostra applicazione.