Se non hai ancora familiarità con i modelli ad albero nell’apprendimento automatico, dovresti dare un’occhiata al nostro corso R sull’argomento.
L’algoritmo Random Forests
Comprendiamo l’algoritmo in termini semplici. Supponiamo che tu voglia fare un viaggio e che tu voglia viaggiare in un posto che ti piacerà.
Quindi cosa fai per trovare un posto che ti piacerà? Puoi cercare online, leggere le recensioni sui blog e portali di viaggio, o puoi anche chiedere ai tuoi amici.
Supponiamo che tu abbia deciso di chiedere ai tuoi amici, e parlare con loro delle loro esperienze di viaggio passate in vari posti. Otterrete alcune raccomandazioni da ogni amico. Ora devi fare una lista di questi posti raccomandati. Poi, chiedete loro di votare (o selezionare un posto migliore per il viaggio) dalla lista dei posti raccomandati che avete fatto. Il posto con il maggior numero di voti sarà la vostra scelta finale per il viaggio.
Nel processo decisionale di cui sopra, ci sono due parti. In primo luogo, chiedere ai tuoi amici circa la loro esperienza di viaggio individuale e ottenere una raccomandazione su più posti che hanno visitato. Questa parte è come usare l’algoritmo dell’albero decisionale. Qui, ogni amico fa una selezione dei posti che lui o lei ha visitato finora.
La seconda parte, dopo aver raccolto tutte le raccomandazioni, è la procedura di voto per selezionare il posto migliore nella lista delle raccomandazioni. L’intero processo di ottenere raccomandazioni dagli amici e di votarle per trovare il posto migliore è noto come algoritmo delle foreste casuali.
Tecnicamente è un metodo di insieme (basato sull’approccio divide et impera) di alberi di decisione generati su un set di dati suddivisi in modo casuale. Questo insieme di classificatori di alberi decisionali è noto anche come foresta. I singoli alberi decisionali sono generati utilizzando un indicatore di selezione degli attributi come il guadagno di informazioni, il rapporto di guadagno e l’indice di Gini per ogni attributo. Ogni albero dipende da un campione casuale indipendente. In un problema di classificazione, ogni albero vota e la classe più popolare viene scelta come risultato finale. Nel caso della regressione, la media di tutti gli output degli alberi è considerata come il risultato finale. E’ più semplice e più potente rispetto agli altri algoritmi di classificazione non lineare.
Come funziona l’algoritmo?
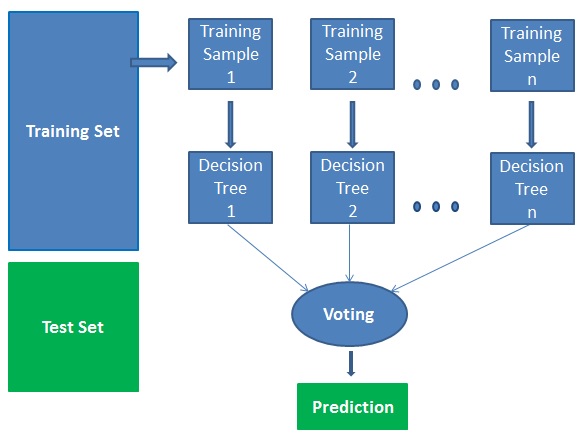
Funziona in quattro passi:
- Seleziona campioni casuali da un dato set di dati.
- Costruisce un albero decisionale per ogni campione e ottiene un risultato di predizione da ogni albero decisionale.
- Effettua una votazione per ogni risultato previsto.
- Selezionare il risultato di predizione con il maggior numero di voti come predizione finale.
Avantaggi:
- Le foreste casuali sono considerate un metodo altamente accurato e robusto a causa del numero di alberi decisionali che partecipano al processo.
- Non soffre del problema dell’overfitting. La ragione principale è che prende la media di tutte le predizioni, che annulla le distorsioni.
- L’algoritmo può essere usato sia in problemi di classificazione che di regressione.
- Le foreste casuali possono anche gestire i valori mancanti. Ci sono due modi per gestirli: usando i valori mediani per sostituire le variabili continue, e calcolando la media ponderata per prossimità dei valori mancanti.
- È possibile ottenere l’importanza relativa delle caratteristiche, che aiuta a selezionare le caratteristiche che contribuiscono maggiormente al classificatore.
Svantaggi:
- Le foreste casuali sono lente nel generare previsioni perché hanno più alberi decisionali. Ogni volta che fa una predizione, tutti gli alberi della foresta devono fare una predizione per lo stesso input dato e poi eseguire il voto su di esso. L’intero processo richiede molto tempo.
- Il modello è difficile da interpretare rispetto ad un albero decisionale, dove si può facilmente prendere una decisione seguendo il percorso nell’albero.
Trovare le caratteristiche importanti
Le foreste casuali offrono anche un buon indicatore di selezione delle caratteristiche. Scikit-learn fornisce una variabile extra con il modello, che mostra l’importanza relativa o il contributo di ogni caratteristica nella predizione. Calcola automaticamente il punteggio di rilevanza di ogni caratteristica nella fase di formazione. Poi scala la rilevanza verso il basso in modo che la somma di tutti i punteggi sia 1.
Questo punteggio vi aiuterà a scegliere le caratteristiche più importanti e ad abbandonare quelle meno importanti per la costruzione del modello.
La foresta casuale usa l’importanza di Gini o la diminuzione media dell’impurità (MDI) per calcolare l’importanza di ogni caratteristica. L’importanza di Gini è anche conosciuta come la diminuzione totale dell’impurità dei nodi. Questo è quanto l’adattamento del modello o l’accuratezza diminuisce quando si elimina una variabile. Più grande è la diminuzione, più significativa è la variabile. Qui, la diminuzione media è un parametro significativo per la selezione delle variabili. L’indice Gini può descrivere il potere esplicativo complessivo delle variabili.
Foreste casuali vs alberi decisionali
- Le foreste casuali sono un insieme di alberi decisionali multipli.
- Gli alberi decisionali profondi possono soffrire di overfitting, ma le foreste casuali impediscono l’overfitting creando alberi su sottoinsiemi casuali.
- Gli alberi decisionali sono computazionalmente più veloci.
- Le foreste casuali sono difficili da interpretare, mentre un albero decisionale è facilmente interpretabile e può essere convertito in regole.
Costruire un classificatore usando Scikit-learn
Si costruirà un modello sul dataset dei fiori di iris, che è un set di classificazione molto famoso. Esso comprende la lunghezza del sepalo, la larghezza del sepalo, la lunghezza dei petali, la larghezza dei petali e il tipo di fiori. Ci sono tre specie o classi: setosa, versicolor e virginia. Costruirete un modello per classificare il tipo di fiore. Il dataset è disponibile nella libreria scikit-learn o puoi scaricarlo dall’UCI Machine Learning Repository.
Inizia importando la libreria datasets da scikit-learn, e carica il dataset iris con load_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Puoi stampare i nomi dei target e delle feature, per assicurarti di avere il dataset giusto, come segue:
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)È una buona idea esplorare sempre un po’ i tuoi dati, così sai con cosa stai lavorando. Qui, potete vedere che le prime cinque righe del dataset sono stampate, così come la variabile target per l’intero dataset.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Qui, potete creare un DataFrame del dataset iris nel modo seguente.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| lunghezza del tappeto | Larghezza del petalo | Lunghezza del sepalo | Larghezza del sepalo | specie | |
|---|---|---|---|---|---|
| 0 | 1.4 | 0.2 | 5.1 | 3.5 | 0 |
| 1 | 1.4 | 0.2 | 4.9 | 3.0 | 0 |
| 2 | 1.3 | 0.2 | 4.7 | 3.2 | 0 |
| 3 | 1.5 | 0.2 | 4.6 | 3.1 | 0 |
| 4 | 1.4 | 0.2 | 5.0 | 3.6 | 0 |
Prima si separano le colonne in variabili dipendenti e indipendenti (o caratteristiche ed etichette). Poi si dividono queste variabili in un set di allenamento e uno di test.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testDopo la divisione, si addestra il modello sul set di allenamento e si eseguono le previsioni sul set di test.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Dopo l’allenamento, si controlla la precisione usando i valori reali e quelli previsti.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)Puoi anche fare una previsione per un singolo elemento, per esempio:
- lunghezza del sepalo = 3
- larghezza del sepalo = 5
- lunghezza del petalo = 4
- larghezza del petalo = 2
Ora puoi predire che tipo di fiore è.
clf.predict(])array()Qui, 2 indica il tipo di fiore Virginica.
Finding Important Features in Scikit-learn
Qui, stai trovando caratteristiche importanti o selezionando caratteristiche nel dataset IRIS. In Scikit-Learn, è possibile eseguire questo compito nei seguenti passi:
- Primo, è necessario creare un modello di foreste casuali.
- Secondo, usare la variabile feature importance per vedere i punteggi di importanza delle feature.
- In terzo luogo, visualizzate questi punteggi usando la libreria seaborn.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64È anche possibile visualizzare l’importanza delle caratteristiche. Le visualizzazioni sono facili da capire e interpretare.
Per la visualizzazione, è possibile utilizzare una combinazione di matplotlib e seaborn. Poiché seaborn è costruito sopra matplotlib, offre una serie di temi personalizzati e fornisce ulteriori tipi di trama. Matplotlib è un superset di seaborn ed entrambi sono ugualmente importanti per una buona visualizzazione.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()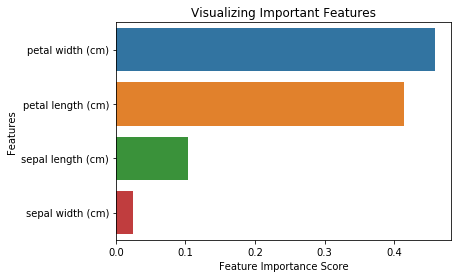
Generare il modello sulle caratteristiche selezionate
Qui, potete rimuovere la caratteristica “larghezza del sepalo” perché ha un’importanza molto bassa, e selezionare le 3 caratteristiche rimanenti.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testDopo la suddivisione, si genererà un modello sulle caratteristiche selezionate del training set, si eseguiranno previsioni sulle caratteristiche selezionate del test set, e si confronteranno i valori reali e quelli previsti.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Si può notare che dopo aver rimosso le caratteristiche meno importanti (lunghezza del sepalo), la precisione è aumentata. Questo perché avete rimosso i dati fuorvianti e il rumore, con conseguente aumento della precisione. Un minor numero di caratteristiche riduce anche il tempo di addestramento.
Conclusione
Congratulazioni, sei arrivato alla fine di questo tutorial!
In questo tutorial, hai imparato cos’è la foresta casuale, come funziona, trovare le caratteristiche importanti, il confronto tra foreste casuali e alberi decisionali, vantaggi e svantaggi. Avete anche imparato la costruzione del modello, la valutazione e la ricerca di caratteristiche importanti in scikit-learn. B
Se vuoi imparare di più sull’apprendimento automatico, ti consiglio di dare un’occhiata al nostro corso Supervised Learning in R: Classificazione.