Si aún no está familiarizado con los modelos basados en árboles en el aprendizaje automático, debería echar un vistazo a nuestro curso de R sobre el tema.
El algoritmo de bosques aleatorios
Entendamos el algoritmo en términos sencillos. Supongamos que quieres ir de viaje y te gustaría viajar a un lugar que te guste.
¿Entonces qué haces para encontrar un lugar que te guste? Puedes buscar en Internet, leer reseñas en blogs y portales de viajes, o también puedes preguntar a tus amigos.
Supongamos que has decidido preguntar a tus amigos, y has hablado con ellos sobre su experiencia de viaje pasada a varios lugares. Usted obtendrá algunas recomendaciones de cada amigo. Ahora tienes que hacer una lista de esos lugares recomendados. A continuación, pídeles que voten (o seleccionen el mejor lugar para el viaje) de la lista de lugares recomendados que has hecho. El lugar con el mayor número de votos será tu elección final para el viaje.
En el proceso de decisión anterior, hay dos partes. En primer lugar, preguntar a tus amigos sobre su experiencia individual de viaje y obtener una recomendación de entre los múltiples lugares que han visitado. Esta parte es como el uso del algoritmo del árbol de decisión. Aquí, cada amigo hace una selección de los lugares que ha visitado hasta el momento.
La segunda parte, después de recoger todas las recomendaciones, es el procedimiento de votación para seleccionar el mejor lugar de la lista de recomendaciones. Todo este proceso de obtener las recomendaciones de los amigos y votarlas para encontrar el mejor lugar se conoce como el algoritmo de los bosques aleatorios.
Técnicamente es un método de conjunto (basado en el enfoque de dividir y conquistar) de árboles de decisión generados en un conjunto de datos divididos al azar. Esta colección de clasificadores de árboles de decisión también se conoce como bosque. Los árboles de decisión individuales se generan utilizando un indicador de selección de atributos, como la ganancia de información, el ratio de ganancia y el índice de Gini para cada atributo. Cada árbol depende de una muestra aleatoria independiente. En un problema de clasificación, cada árbol vota y se elige la clase más popular como resultado final. En el caso de la regresión, la media de todas las salidas de los árboles se considera el resultado final. Es más sencillo y potente en comparación con otros algoritmos de clasificación no lineales.
¿Cómo funciona el algoritmo?
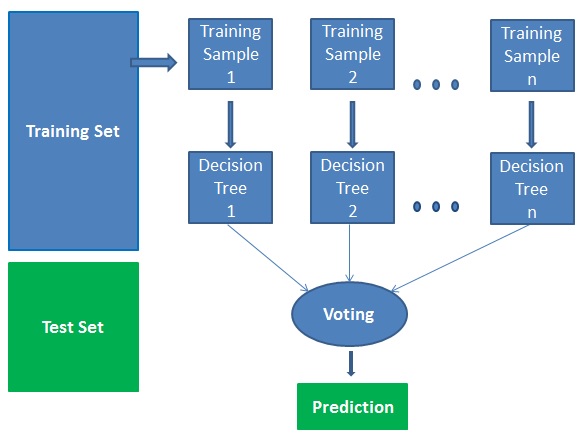
Funciona en cuatro pasos:
- Seleccionar muestras aleatorias de un conjunto de datos dado.
- Construir un árbol de decisión para cada muestra y obtener un resultado de predicción de cada árbol de decisión.
- Realizar una votación para cada resultado predicho.
- Seleccionar el resultado de la predicción con más votos como la predicción final.
Ventajas:
- Los bosques aleatorios se consideran un método muy preciso y robusto debido al número de árboles de decisión que participan en el proceso.
- No sufre el problema del sobreajuste. La razón principal es que toma la media de todas las predicciones, lo que anula los sesgos.
- El algoritmo puede utilizarse tanto en problemas de clasificación como de regresión.
- Los bosques aleatorios también pueden manejar valores perdidos. Hay dos maneras de manejarlos: utilizando valores medianos para reemplazar las variables continuas, y calculando la media ponderada por proximidad de los valores perdidos.
- Se puede obtener la importancia relativa de las características, lo que ayuda a seleccionar las características que más contribuyen al clasificador.
- Los bosques aleatorios son lentos en la generación de predicciones porque tiene múltiples árboles de decisión. Cada vez que hace una predicción, todos los árboles del bosque tienen que hacer una predicción para la misma entrada dada y luego realizar una votación sobre ella. Todo este proceso lleva mucho tiempo.
- El modelo es difícil de interpretar en comparación con un árbol de decisión, donde se puede tomar fácilmente una decisión siguiendo el camino en el árbol.
- Los bosques aleatorios son un conjunto de múltiples árboles de decisión.
- Los árboles de decisión profundos pueden sufrir de sobreajuste, pero los bosques aleatorios evitan el sobreajuste creando árboles en subconjuntos aleatorios.
- Los árboles de decisión son computacionalmente más rápidos.
- Los bosques aleatorios son difíciles de interpretar, mientras que un árbol de decisión es fácilmente interpretable y se puede convertir en reglas.
Desventajas:
Encontrar características importantes
Los bosques aleatorios también ofrecen un buen indicador de selección de características. Scikit-learn proporciona una variable extra con el modelo, que muestra la importancia relativa o la contribución de cada característica en la predicción. Calcula automáticamente la puntuación de relevancia de cada característica en la fase de entrenamiento. A continuación, escala la relevancia para que la suma de todas las puntuaciones sea 1.
Esta puntuación le ayudará a elegir las características más importantes y a descartar las menos importantes para la construcción del modelo.
El bosque aleatorio utiliza la importancia de gini o la disminución media de la impureza (MDI) para calcular la importancia de cada característica. La importancia de Gini también se conoce como la disminución total de la impureza del nodo. Se trata de cuánto disminuye el ajuste o la precisión del modelo cuando se elimina una variable. Cuanto mayor sea la disminución, más significativa es la variable. En este caso, la disminución media es un parámetro importante para la selección de variables. El índice de Gini puede describir el poder explicativo global de las variables.
Bosques aleatorios vs. Árboles de decisión
Construir un clasificador usando Scikit-learn
Construirás un modelo en el conjunto de datos de flores del iris, que es un conjunto de clasificación muy famoso. Comprende la longitud de los sépalos, la anchura de los sépalos, la longitud de los pétalos, la anchura de los pétalos y el tipo de flores. Hay tres especies o clases: setosa, versicolor y virginia. Construirás un modelo para clasificar el tipo de flor. El conjunto de datos está disponible en la biblioteca de scikit-learn o puedes descargarlo del Repositorio de Aprendizaje Automático de la UCI.
Comienza importando la biblioteca de conjuntos de datos de scikit-learn, y carga el conjunto de datos de iris con load_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Puedes imprimir los nombres del objetivo y de las características, para asegurarte de que tienes el conjunto de datos correcto, como tal:
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)Es una buena idea explorar siempre un poco tus datos, para saber con qué estás trabajando. Aquí, puedes ver que se imprimen las cinco primeras filas del conjunto de datos, así como la variable de destino para todo el conjunto de datos.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Aquí, puedes crear un DataFrame del conjunto de datos del iris de la siguiente manera.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| longitud del pétalo | anchura del pétalo | longitud del pétalo | anchura del pétalo | ||
|---|---|---|---|---|---|
| 0 | 1.4 | 0,2 | 5,1 | 3,5 | 0 | 1 | 1,4 | 0,2 | 4,9 | 3.0 | 0 |
| 2 | 1,3 | 0,2 | 4,7 | 3,2 | 0 |
| 1,5 | 0,2 | 4.6 | 3,1 | 0 | |
| 4 | 1,4 | 0,2 | 5,0 | 3.6 | 0 |
Primero, separas las columnas en variables dependientes e independientes (o características y etiquetas). A continuación, divides esas variables en un conjunto de entrenamiento y otro de prueba.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testDespués de la división, entrenarás el modelo en el conjunto de entrenamiento y realizarás predicciones en el conjunto de prueba.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Después del entrenamiento, comprueba la precisión utilizando los valores reales y los predichos.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)También puedes hacer una predicción para un solo elemento, por ejemplo:
- Longitud del pétalo = 3
- Ancho del pétalo = 5
- Longitud del pétalo = 4
- Ancho del pétalo = 2
Ahora puedes predecir qué tipo de flor es.
clf.predict(])array()Aquí, el 2 indica el tipo de flor Virginica.
Encontrar características importantes en Scikit-learn
Aquí, estás encontrando características importantes o seleccionando características en el conjunto de datos IRIS. En scikit-learn, puede realizar esta tarea en los siguientes pasos:
- Primero, necesita crear un modelo de bosques aleatorios.
- Segundo, utilice la variable de importancia de características para ver las puntuaciones de importancia de características.
- Terceramente, visualiza estas puntuaciones utilizando la librería seaborn.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64También puedes visualizar la importancia de las características. Las visualizaciones son fáciles de entender e interpretar.
Para la visualización, puede utilizar una combinación de matplotlib y seaborn. Debido a que seaborn está construido sobre matplotlib, ofrece una serie de temas personalizados y proporciona tipos de gráficos adicionales. Matplotlib es un superconjunto de seaborn y ambos son igual de importantes para realizar buenas visualizaciones.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()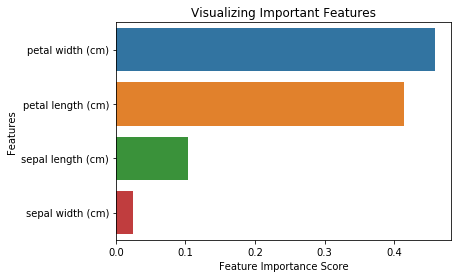
Generar el modelo en las características seleccionadas
Aquí, puedes eliminar la característica «ancho del sépalo» porque tiene muy poca importancia, y seleccionar las 3 características restantes.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testDespués de la división, generará un modelo sobre las características del conjunto de entrenamiento seleccionado, realizará predicciones sobre las características del conjunto de prueba seleccionado y comparará los valores reales y los predichos.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Puede ver que después de eliminar las características menos importantes (longitud del sépalo), la precisión aumentó. Esto se debe a que se han eliminado los datos erróneos y el ruido, lo que ha provocado un aumento de la precisión. Una menor cantidad de características también reduce el tiempo de entrenamiento.
Conclusión
¡Felicidades, ha llegado al final de este tutorial!
En este tutorial, ha aprendido qué son los bosques aleatorios, cómo funcionan, cómo encontrar características importantes, la comparación entre los bosques aleatorios y los árboles de decisión, las ventajas y desventajas. También ha aprendido la construcción de modelos, la evaluación y la búsqueda de características importantes en scikit-learn. B
Si quieres aprender más sobre el aprendizaje automático, te recomiendo que eches un vistazo a nuestro Aprendizaje Supervisado en R: Curso de clasificación.