Su tabla puede contener valores duplicados en una columna y en ciertos escenarios puede requerir obtener sólo registros únicos de la tabla.
Para eliminar los registros duplicados de los datos obtenidos con la sentencia SELECT, puede utilizar la cláusula DISTINCT como se muestra en los ejemplos siguientes.
Una demostración de SELECT simple – DISTINCT
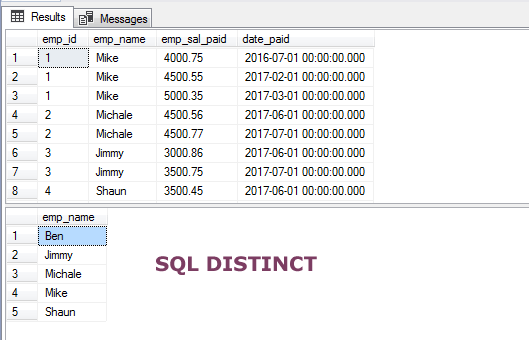
En el primer ejemplo, he utilizado la cláusula DISTINCT con la sentencia SELECT para recuperar sólo nombres únicos de nuestra tabla de demostración, sto_emp_salary_paid. Esta tabla almacena los salarios de los empleados junto con sus nombres. Por lo tanto, la ocurrencia duplicada de los nombres de los empleados se produce en la tabla.
Utilizando la cláusula DISTINCT, obtenemos sólo los nombres únicos de los empleados:
Consulta:
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid;
(Se aplica a bases de datos SQL Server y MySQL)
Usando la cláusula WHERE con DISTINCT
En este ejemplo, utilicé la cláusula WHERE con la sentencia SELECT/DISTINCT para recuperar sólo aquellos empleados únicos a los que el salario pagado es mayor o igual a 4500. Vea la consulta y el conjunto de resultados:
Consulta:
|
1
2
3
|
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
WHERE emp_sal_paid >= 4500;
|

El ejemplo de la función COUNT con DISTINCT
También se puede utilizar la función COUNT SQL para obtener el número de registros como utilizando la cláusula DISTINCT. La función devuelve sólo el recuento de las filas devueltas después de la cláusula DISTINCT.
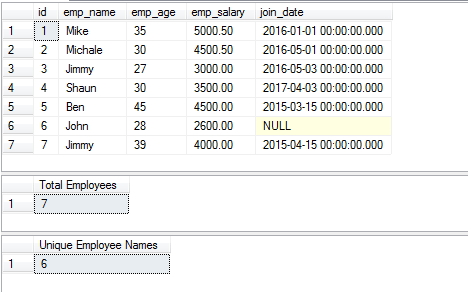
Para la demostración, estoy utilizando la tabla de empleados que almacena la información sobre los empleados. En la demo se utilizan tres consultas como se indica a continuación:
- La primera consulta devuelve el registro completo de la tabla
- La segunda consulta obtiene el número de empleados utilizando el ID (COUNT y DISTINCT)
- Mientras que la tercera devuelve los nombres únicos de los empleados utilizando la columna emp_name.
Las tres consultas son:
|
1
2
. 3
4
5
6
7
|
SELECT * FROM sto_employees;
SELECT COUNT(DISTINCT id) AS «Total de empleados» FROM sto_employees
SELECT COUNT(DISTINCT emp_name) AS «Nombres de empleados únicos» FROM sto_employees
|
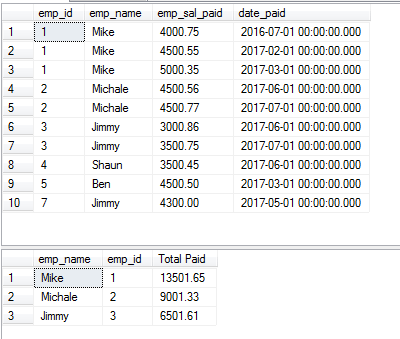
La cláusula DISTINCT con el ejemplo GROUP BY
La siguiente consulta obtiene los registros de la misma tabla que se utilizó en los ejemplos anteriores y agrupa los sueldos de los empleados. Para ello se utilizan las cláusulas GROUP BY y DISTINCT de la siguiente manera:
La Consulta:
|
1
2
3
|
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As «Total Paid» FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id;
|
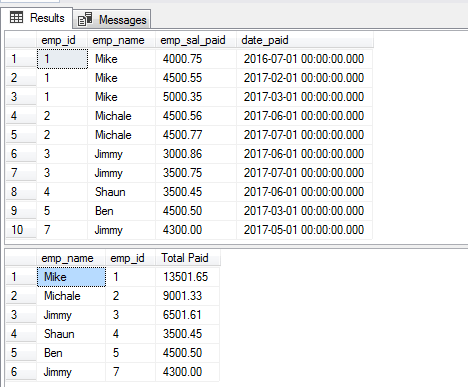
El registro de «Jimmy» aparece dos veces ya que tiene dos IDs diferentes.
Usando la cláusula HAVING con DISTINCT
Así como se usa la cláusula GROUP BY con DISTINCT, también se puede añadir la cláusula HAVING para obtener registros. En la siguiente consulta, se añade la cláusula HAVING en el ejemplo anterior y obtendremos los registros cuya SUMA sea superior a 5000.
La consulta:
|
1
2
3
4
|
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As «Total Paid» FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id
HAVING SUM(emp_sal_paid) > 5000;
|
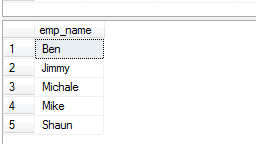
La cláusula DISTINCT con ORDER BY ejemplo
La cláusula ORDER BY de SQL se puede utilizar con la cláusula DISTINCT para ordenar los resultados después de eliminar los valores duplicados. Vea la consulta y la salida a continuación:
|
1
2
. 3
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
ORDER BY emp_name;
|
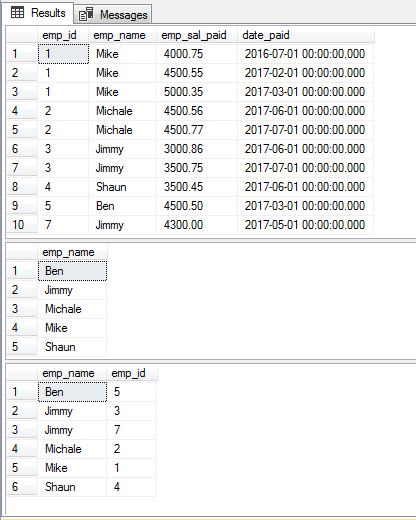
Utilizando múltiples columnas en la cláusula DISTINCT
También puede especificar dos o más columnas como utilizando la cláusula SELECT – DISTINCT. Como tal, nuestra tabla de ejemplo contiene valores duplicados para los empleados y sus ID, por lo que será un buen aprendizaje ver cómo la cláusula DISTINCT devuelve los registros como utilizando estas dos columnas en la consulta única.
Para ver la diferencia, primero escribí una consulta con DISTINCT (emp_name) que es seguida por el uso de ambas columnas:
La Consulta:
|
1
2
3
4
5
. 6
7
8
|
Los resultados de la tabla completa, las consultas DISTINCT emp_name y DISTINCT emp_name,emp_id: