El volumen de datos conservados, gestionados y accedidos hoy en día no tiene precedentes. Las empresas esperan que el departamento de TI mantenga los datos en línea y accesibles indefinidamente, lo que ejerce una intensa presión sobre las bases de datos necesarias para almacenarlos y gestionarlos. Para satisfacer las necesidades actuales, es necesario sustituir los procesos heredados, obsoletos e ineficaces, por técnicas nuevas y más ágiles. La replicación de SQL Server es una de las técnicas para dar cabida a tales demandas.
-
Nota: Para obtener más información sobre la replicación de bases de datos, lea Diferentes partes interesadas, diferentes puntos de vista: Why Database Management Requires a Systematic Approach.
- La replicación de SQL Server, en general
- Los componentes de la replicación transaccional de SQL Server, en particular
- Cómo obtener las propiedades del distribuidor
- Cómo encontrar el editor que utiliza el mismo distribuidor
- Cuáles son las bases de datos utilizadas para la replicación de SQL Server
- La topología general de un entorno de replicación
- Cuáles son los artículos que se asignan al tipo de modelo de replicación de SQL Server
- Cómo obtener la publicación detalles
- Cómo obtener detalles de suscripción
- Agentes de replicación de SQL Server
- Y más…
- Editor
- Base de datos de publicación
- Publicación
- Artículos
- Distribuidor
- Base de datos de distribución
- Suscriptor
- Base de datos de suscripción.
- Suscripción
- Agentes de replicación
-
¿Un servidor es un distribuidor o no?
1SELECT @@ServerName Servername, case when is_distributor=1 then ‘Yes’ else ‘No’ end status FROM sys.servers WHERE name=’repl_distributor’ AND data_source=@@nombre_servidor;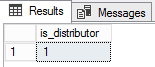
-
Un editor está utilizando este distribuidor o no?
1EXEC sp_get_distributor
¿O sólo para interrogar varias propiedades de la base de datos de Distribuidores y Distribuciones?
123EXEC sp_helpdistributor;EXEC sp_helpdistributiondb;EXEC sp_helpdistpublisher;Suscriptor
Una instancia de base de datos que consume datos de replicación de SQL Server desde una publicación se denomina Suscriptor. El suscriptor puede recibir datos de uno o más editores y publicaciones. El suscriptor también puede pasar los cambios de datos de vuelta al publicador o republicar los datos a otros suscriptores dependiendo del tipo de diseño y modelo de replicación.
1EXEC sp_helpsubscriberinfo;Suscripciones
Una suscripción es una solicitud de entrega de una copia de una publicación a un Suscriptor. La suscripción define qué datos de la publicación se recibirán, dónde y cuándo.
Hay dos tipos de suscripciones: suscripciones push y suscripciones pull
- Suscripción push: El Distribuidor actualiza directamente los datos en la base de datos del Suscriptor
- Suscripción pull: el Suscriptor está programado para comprobar en el Distribuidor regularmente si hay nuevos cambios, y entonces actualiza los datos en la propia base de datos de la suscripción.
1EXEC sp_helpsubscription;Bases de datos de suscripción
Una base de datos de destino de un modelo de replicación se llama base de datos de suscripción.
Agentes de replicación
La replicación de SQL Server utiliza un conjunto predefinido de programas independientes y eventos se conocen como agentes, para llevar a cabo las tareas asociadas a los datos. Por defecto, los agentes de replicación de SQL Server se ejecutan como trabajos programados bajo SQL Server Agent. Los agentes de replicación también pueden ejecutarse desde la línea de comandos y mediante aplicaciones que utilizan Objetos de Gestión de Replicación (RMO). Los agentes de replicación de SQL Server se pueden supervisar y administrar mediante Replication Monitor y SQL Server Management Studio.
Agente de instantáneas de replicación
El Agente de instantáneas de replicación se utiliza con todos los tipos de tecnología de replicación de SQL Server, ya que proporciona el conjunto de datos necesario para realizar la sincronización de datos inicial de la base de datos de publicación con la base de datos de suscripción. Prepara el esquema y los datos iniciales de los artículos publicados, los archivos de instantáneas y registra la información sobre el tipo de sincronización en la base de datos de distribución.
Agente Lector de Registros
El Agente Lector de Registros se utiliza sólo con la replicación transaccional. Mueve las transacciones de replicación desde el registro de transacciones en línea de la base de datos de publicación a la base de datos de distribución.
Agente de distribución
El Agente de distribución se utiliza únicamente con la instantánea de replicación y la replicación transaccional de SQL Server. Este agente aplica la instantánea de replicación inicial a la base de datos de suscripción y, posteriormente, los cambios de datos se rastrean y registran en la base de datos de distribución y se aplican a la base de datos de suscripción.
Agente de Fusión
El Agente de Fusión se utiliza con el modelo de replicación de fusión. De forma predeterminada, el agente de fusión carga los cambios del suscriptor al editor y luego descarga los cambios del editor al suscriptor. Cada suscripción tiene su propio Agente de Fusión que se conecta tanto al Editor como al Suscriptor y actualiza ambos. El Agente de Fusión se ejecuta en el Distribuidor para las suscripciones push o en el Suscriptor para las suscripciones pull. En este caso, la sincronización es bidireccional. Los conflictos de datos son manejados por un conjunto de triggers que soporta todo el proceso
Resumen
Hasta ahora, hemos visto un paseo por algunos de los conceptos importantes de la replicación de SQL Server. Además, se muestran scripts T-SQL para consultar las tablas del sistema y los procedimientos almacenados de replicación para responder a la mayoría de las preguntas más frecuentes sobre la replicación de SQL Server.
Discutiré más sobre la replicación de SQL Server en próximos artículos. Si crees, que algo se puede mejorar en este artículo, no dudes en dejar tu comentario abajo…
Tabla de contenidos
Replicación de SQL Server: Visión general de los componentes y topografía
Replicación de SQL: Instalación y configuración básica
Cómo añadir/soltar artículos de publicaciones existentes en SQL Server
Cómo hacer una rápida comparación estimada de datos en dos grandes bases de datos de SQL Server para ver si son iguales
Replicación transaccional de SQL Server: Cómo reiniciar una suscripción utilizando una copia de seguridad de la base de datos de SQL Server
Cómo configurar un modelo de replicación transaccional personalizado de SQL Server con un suscriptor central y múltiples bases de datos de editores
Cómo configurar la replicación transaccional personalizada de SQL Server con un editor central y múltiples bases de datos de suscriptores
Cómo configurar una solución de replicación transaccional de bases de datos DDL y DML de SQL Server
Cómo configurar la replicación transaccional cruzada deplataforma de replicación transaccional de SQL Server para la generación de informes de bases de datos en Linux
Cómo migrar bases de datos de SQL Server sin pérdida de datos y sin tiempo de inactividad
Utilizar la replicación transaccional de datos para reproducir y probar las cargas de producción en un servidor de ensayo
Cómo configurar la replicación de bases de datos de SQL Server para un servidor de informes
Replicación transaccional de SQL Server: Cómo reiniciar una suscripción usando un «soporte de replicación solamente» -TBA
Supervisión de la replicación de SQL Server y configuración de alertas usando PowerShell -TBA
- Autor
- Postes recientes
 Soy un tecnólogo de Bases de Datos con 11+ años de rica, experiencia práctica en tecnologías de bases de datos. Soy un profesional certificado por Microsoft y respaldado por un título de máster en aplicaciones informáticas.
Soy un tecnólogo de Bases de Datos con 11+ años de rica, experiencia práctica en tecnologías de bases de datos. Soy un profesional certificado por Microsoft y respaldado por un título de máster en aplicaciones informáticas.
Mi especialidad es el diseño de & soluciones de alta disponibilidad y migración de bases de datos multiplataforma. Las tecnologías en las que actualmente trabajo son SQL Server, PowerShell, Oracle y MongoDB.
Ver todos los posts de Prashanth JayaramÚltimos posts de Prashanth Jayaram (ver todos)- Una rápida visión de la auditoría de bases de datos en SQL – 28 de enero, 2021
- Cómo configurar Azure Data Sync entre las bases de datos de Azure SQL y SQL Server local – 20 de enero
- Cómo realizar operaciones de importación/exportación de bases de datos de Azure SQL mediante PowerShell – 14 de enero de 2021
.
En este artículo, vamos a dar forma a su comprensión de la topografía completa de la replicación de SQL Server, incluyendo los componentes, los elementos internos y el SQL para unirlo todo. Después de completar la lectura de este artículo, usted entenderá:
Replicación
La replicación de SQL Server es una tecnología para copiar y distribuir datos y objetos de base de datos de una base de datos a otra y luego sincronizar entre bases de datos para mantener la consistencia e integridad de los datos. En la mayoría de los casos, la replicación es un proceso de reproducción de los datos en los objetivos deseados. La replicación de SQL Server se utiliza para copiar y sincronizar datos de forma continua o también se puede programar para que se ejecute a intervalos predeterminados. Hay varias técnicas de replicación diferentes que admiten una variedad de enfoques de sincronización de datos; unidireccional; de uno a muchos; de muchos a uno; y bidireccional, y mantienen varios conjuntos de datos sincronizados entre sí.
Componentes de la replicación transaccional de SQL Server
El siguiente diagrama representa los componentes de la replicación transaccional de SQL Server.
Incluyendo la replicación de SQL Server …
Diagrama de replicación de SQL Server
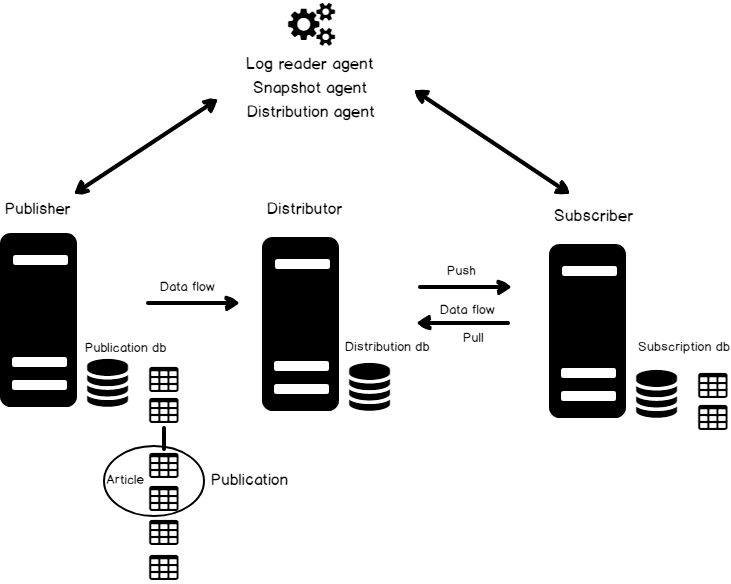
Artículo
Un artículo es la unidad básica de la replicación de SQL Server. Un artículo puede consistir en tablas, procedimientos almacenados y vistas. Es posible escalar el artículo, horizontal y verticalmente utilizando una opción de filtro. También podemos crear múltiples artículos sobre el mismo objeto con algunas restricciones y limitaciones.
Utilizando el asistente de Nueva Publicación, se puede navegar por el Artículo. Nos permite ver las propiedades de un artículo y proporcionar opciones para establecer propiedades para los artículos. En algunos casos, las propiedades se pueden establecer durante el momento de la creación de la publicación y es una propiedad de sólo lectura.
Después de la creación de una publicación de replicación de SQL Server, por ejemplo, si alguna propiedad requiere un cambio, requerirá, a su vez, que se genere una nueva instantánea de replicación. Si la publicación tiene una o más suscripciones, entonces el cambio requiere que se reinicien todas las suscripciones. Para obtener más información, consulte el artículo Cómo añadir/eliminar artículos a/de una publicación existente en SQL Server.
Para listar todos los artículos que se publican, ejecute la siguiente T-SQL
|
1
2
3
4
. 5
6
7
8
9
10
12
|
Para obtener los detalles de los artículos en la replicación transaccional o de fusión de SQL Server en una base de datos publicada, ejecute el siguiente T-SQL.
|
1
2
3
4
5
6
7
8
|
SELECT st.name , st.schema_id, st.is_published , st.is_merge_published, is_schema_published
FROM sys.tables st WHERE st.is_published = 1 or st.is_merge_published = 1 or st.is_schema_published = 1
UNION
SELECT sp.name, sp.schema_id, 0, 0, sp.is_schema_published
FROM sys.procedures sp WHERE sp.is_schema_published = 1
UNION
SELECT sv.name, sv.schema_id, 0, 0, sv.is_schema_published
FROM sys.views sv WHERE sv.is_schema_published = 1;
|
Para obtener información detallada sobre un artículo en el editor listado, ejecute el siguiente T-SQL
|
1
2
3
4
5
6
7
|
DECLARE @publication AS sysname;
SET @publicación = N’PROD_HIST_Pub’;
USE MES_PROD_AP
EXEC sp_helparticle
@publicación = @publicación;
GO
|
Para obtener los detalles a nivel de columna, ejecute el siguiente T-SQL
|
1
2
3
|
USE MES_PROD_AP
GO
sp_helparticlecolumns @publication = N’PROD_HIST_Pub’ , @article = ‘tb_Branch_Plant’
|
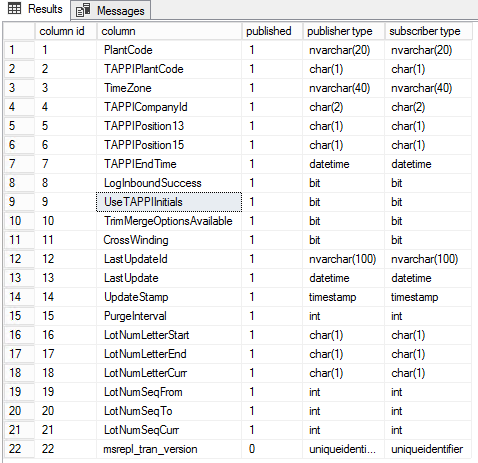
Para listar las columnas que se publican en la replicación transaccional en la base de datos de publicación, ejecute el siguiente T-SQL
|
1
|
SELECT nombre_objeto(object_id) , name FROM sys.columns scERE sc.is_replicated = 1;
|
Publicaciones
Una Publicación es una colección lógica de artículos de una base de datos. La entidad nos permite definir y configurar las propiedades de los artículos en el nivel superior para que las propiedades se hereden a todos los artículos de ese grupo.
|
1
|
EXEC sp_helppublication;
|
Base de datos del editor
El editor es una base de datos que contiene una lista de objetos que se designan como artículos de replicación de SQL Server se conocen como base de datos de publicación. El editor puede tener una o más publicaciones. Cada editor define un mecanismo de propagación de datos mediante la creación de varios procedimientos almacenados de replicación interna.
|
1
2
3
USE Distribution
GO
select * from MSpublications
|

Publicador
El Publicador es una instancia de base de datos que pone los datos a disposición de otras ubicaciones mediante la replicación de SQL Server. El Publisher puede tener una o más publicaciones, cada una de las cuales define un conjunto de objetos y datos relacionados lógicamente para replicar.
Distribuidor
El Distribuidor es una base de datos que actúa como almacén de los datos específicos de replicación asociados a uno o más Publishers. En muchos casos, el distribuidor es una única base de datos que actúa como Editor y como Distribuidor. En el contexto de la replicación de SQL Server, esto se conoce comúnmente como «distribuidor local». Por otro lado, si se configura en un servidor separado, entonces se conoce como «distribuidor remoto». Cada Publisher está asociado a una única base de datos conocida como «base de datos de distribución» alias el «Distribuidor».
La base de datos de distribución identifica y almacena los datos de estado de la replicación de SQL Server, los metadatos sobre la publicación y, en algunos casos, actúa como cola para los datos que se mueven desde el Editor a los Suscriptores.
Dependiendo del modelo de replicación, el Distribuidor también podría ser responsable de notificar a los Suscriptores que se han suscrito a una publicación que un artículo ha cambiado. Además, la base de datos de distribución mantiene la integridad de los datos.
Bases de datos de distribución
Cada Distribuidor debe tener al menos una base de datos de distribución. La base de datos de distribución consiste en el detalle de los artículos, los metadatos de replicación y los datos. Un Distribuidor puede tener más de una base de datos de distribución; sin embargo, todas las publicaciones definidas en un mismo Editor deben utilizar la misma base de datos de distribución.
Para saber si …
¿Una base de datos de distribución instalada o no?
|
1
|
SELECT name FROM sys.databases WHERE is_distributor = 1
|