Tenemos algunos archivos personalizados que recibimos de diferentes proveedores y para estas situaciones no podemos utilizar programas ETL estándar sin ninguna personalización. Dado que estamos ampliando nuestra capacidad de leer estos archivos personalizados con .NET, estamos buscando formas eficientes de leer archivos con PowerShell que podamos utilizar en agentes de trabajo de SQL Server, programadores de tareas de Windows o con nuestro programa personalizado, que puede ejecutar scripts de PowerShell. Tenemos muchas herramientas para analizar datos y queríamos conocer formas eficientes de leer los datos para analizarlos, junto con obtener líneas específicas de datos de los archivos por número, o por la primera o última línea del archivo. Para leer archivos de manera eficiente, ¿cuáles son algunas funciones o bibliotecas que podemos utilizar?
Resumen
Para la lectura de datos de archivos, generalmente queremos centrarnos en tres funciones principales para completar estas tareas junto con algunos ejemplos enumerados al lado de estos en la práctica:
- Cómo leer un archivo completo, parte de un archivo o saltar en un archivo. Podemos enfrentarnos a una situación en la que queramos leer todas las líneas excepto la primera y la última.
- Cómo leer un archivo utilizando pocos recursos del sistema. Podemos tener un archivo de 100GB del que sólo queremos leer 108KB de datos.
- Cómo leer un archivo de forma que nos permita fácilmente analizar los datos que necesitamos o nos permita utilizar funciones o herramientas que usamos con otros datos. Dado que muchos desarrolladores tienen herramientas de análisis de cadenas, pasar los datos a un formato de cadena -si es posible- nos permite reutilizar muchas herramientas de análisis de cadenas.
- Lo anterior se aplica a la mayoría de las situaciones relacionadas con el análisis de datos de archivos. Empezaremos por ver una función incorporada en PowerShell para leer datos, y luego veremos una forma personalizada de leer datos de archivos usando PowerShell.
Función Get-Content de PowerShell
La última versión de PowerShell (versión 5) y muchas versiones anteriores de PowerShell vienen con la función Get-Content y esta función nos permite leer rápidamente los datos de un archivo. En el siguiente script, damos salida a los datos de un archivo completo en la pantalla de PowerShell ISE, una pantalla que utilizaremos con fines de demostración a lo largo de este artículo:
1Get-Content «C:\N-logging\N-logging.txt»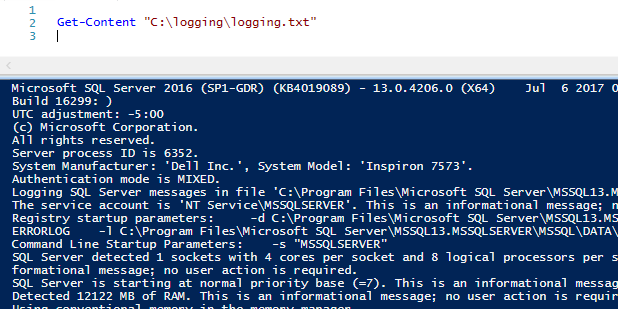
Get-Content da salida a todo el archivo de registro.txt a la pantalla de PowerShell ISE (nótese que la imagen anterior es sólo una parte del archivo completo). Podemos guardar toda esta cantidad de datos en una cadena, llamada ourfilesdata:
12..
$ourfilesdata = Get-Content «C:\N-logging\N-logging.txt»$ourfilesdataObtenemos el mismo resultado que el anterior, la única diferencia es que aquí hemos guardado todo el archivo en una variable. Sin embargo, nos encontramos con un inconveniente si guardamos un archivo entero en una variable o si damos salida a un archivo entero: si el tamaño del archivo es grande, tendremos que leer todo el archivo en la variable o dar salida a todo el archivo en la pantalla. Esto empieza a costar rendimiento, ya que tratamos con tamaños de archivo más grandes.
Podemos seleccionar una parte del archivo tratando nuestra variable (siendo el objeto otro nombre) como una consulta SQL donde seleccionamos algunos de los archivos en lugar de todo. En el código siguiente, seleccionamos las cinco primeras líneas del archivo, en lugar de todo el archivo:
12$ourfilesdata = Get-Content «C:\N-logging\N-logging.txt»$ourfilesdata | Select-Object -First 5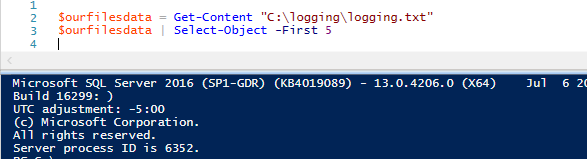
La ventana de salida de PowerShell ISE sólo devuelve las cinco primeras líneas del archivo. También podemos usar la misma función para obtener las últimas cinco líneas del archivo, usando una sintaxis similar:
12$ourfilesdata = Get-Content «C:\N-logging\N-logging.txt»$ourfilesdata | Select-Object -Last 5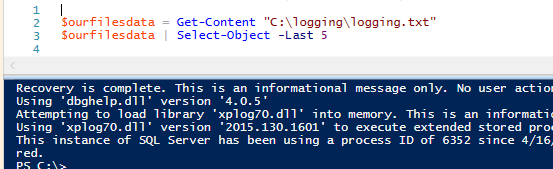
La ventana de salida de PowerShell ISE sólo devuelve las últimas cinco líneas del archivo. La función Get-Content incorporada en PowerShell puede ser útil, pero si queremos almacenar muy pocos datos en cada lectura por razones de análisis, o si queremos leer línea por línea para analizar un archivo, es posible que queramos utilizar la clase StreamReader de .NET, que nos permitirá personalizar nuestro uso para aumentar la eficiencia. Esto hace que Get-Content sea un gran lector básico de datos de archivos.
La librería StreamReader
En una nueva ventana de PowerShell ISE, crearemos un objeto StreamReader y dispondremos de este mismo objeto ejecutando el siguiente código PowerShell:
123$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt»)###Leyendo cosas del archivo aquí$newstreamreader.Dispose()En general, cada vez que creamos un nuevo objeto, es una buena práctica eliminar ese objeto, ya que libera recursos de computación en ese objeto. Si bien es cierto que .NET lo hará automáticamente, sigo recomendando hacerlo manualmente, ya que es posible que en el futuro trabajes con lenguajes que no lo hagan automáticamente y sea una buena práctica.
No pasa nada cuando ejecutamos el código anterior porque no hemos llamado a ningún método: sólo hemos creado un objeto y lo hemos eliminado. El primer método que veremos es el método ReadToEnd():
123$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt»)$newstreamreader.ReadToEnd()$newstreamreader.Dispose()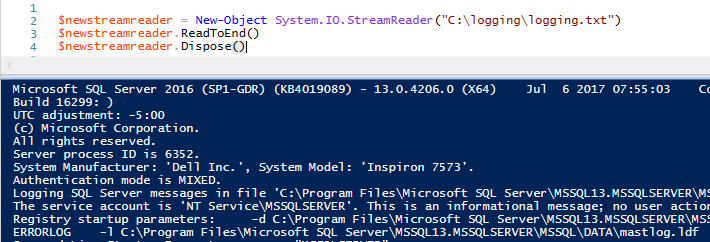
El método ReadToEnd() de StreamReader parece idéntico al de Get-Content en la ventana de ISE en el sentido de que da salida a todos los datos del archivo. Como vemos en la salida, podemos leer todos los datos del archivo como con Get-Content usando el método ReadToEnd(); ¿cómo leemos cada línea de datos? En la clase StreamReader se incluye el método ReadLine() y si lo llamáramos en lugar de ReadToEnd(), obtendríamos la primera línea de datos de nuestros archivos:
123$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt»)$newstreamreader.ReadLine()$newstreamreader.Dispose()
El método ReadLine() lee la línea actual del archivo, que en este caso es la primera línea. Como le dijimos al StreamReader que leyera la línea, leyó la primera línea del archivo y se detuvo. La razón de esto es que el método ReadLine() sólo lee la línea actual (en este caso, la línea uno). Debemos seguir leyendo el archivo hasta llegar al final del mismo. ¿Cómo sabemos cuando un archivo termina? La línea final es nula. En otras palabras, queremos que el StreamReader siga leyendo el archivo (bucle while) mientras cada nueva línea no sea nula (es decir, tenga datos). Para demostrarlo, vamos a añadir un contador de líneas a cada línea sobre la que iteremos para poder ver la lógica con números y texto:
1235.
678$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt»)$eachlinenumber = 1while (($readeachline =$newstreamreader.ReadLine()) -ne $null){Write-Host «$eachlinenumber $readeachline»$eachlinenumber++}$newstreamreader.Dispose()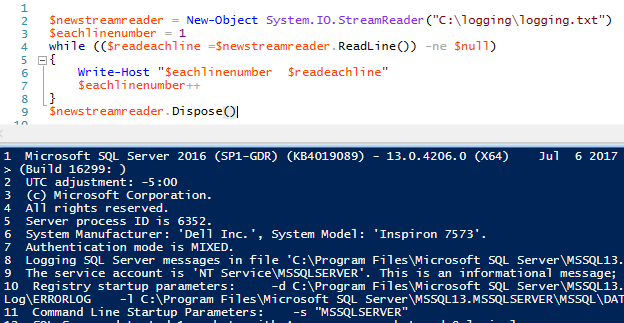
Nuestro contador ahora presenta cada línea junto con la línea del texto del archivo. Como StreamReader lee cada línea, almacena los datos de la línea en el objeto que hemos creado $readeachline. Podemos aplicar funciones de cadena a esta línea de datos en cada pasada, como por ejemplo obtener los diez primeros caracteres de la línea de datos:
1234567$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt»)$eachlinenumber = 1while (($readeachline = $newstreamreader.ReadLine()) -ne $null){$readeachline.Substring(0,10)}$newstreamreader.Dispose()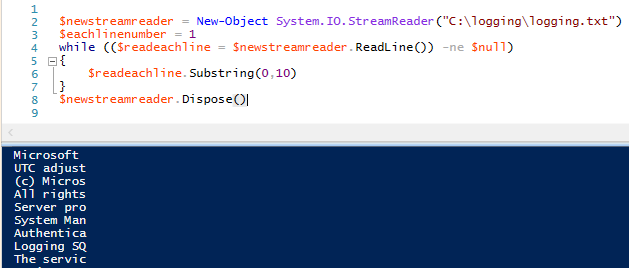
StreamReader devuelve los diez primeros caracteres de cada línea de datos mediante el método Substring string. Podemos extender este ejemplo y llamar a otros dos métodos de cadena – esta vez incluyendo los métodos de cadena IndexOf y Replace(). Sólo llamamos a estos métodos en las dos primeras líneas obteniendo únicamente las líneas menores a la línea tres:
12345678910111314$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt»)$eachlinenumber = 1while (($readeachline = $newstreamreader.ReadLine()) -ne $null){if ($eachlinenumber -lt 3){Write-Host «$eachlinenumber»$readeachline.Substring(0,12)$readeachline.IndexOf(» «)$readeachline.Replace(» «, «replace»)}$eachlinenumber++}$newstreamreader.Dispose()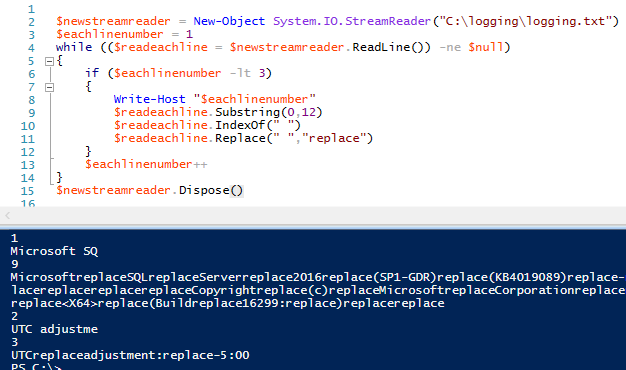
Las funciones Substring(), IndexOf() y Replace() métodos de cadena en las dos primeras líneas del archivo. Para analizar los datos, podemos utilizar nuestros métodos de cadena en cada línea del archivo – o en una línea específica del archivo – en cada iteración del bucle.
Por último, queremos ser capaces de obtener una línea específica del archivo – podemos obtener la primera y la última línea del archivo utilizando Get-Content. Vamos a utilizar StreamReader para apostar un número de línea específico que pasaremos a una función personalizada que crearemos. Vamos a crear una función reutilizable que devuelva un número de línea específico, a continuación queremos envolver nuestra función para reutilizarla mientras se requieren dos entradas: la ubicación del archivo y el número de línea específico que queremos devolver.
123456789101112131415161718192021222324Función Get-FileData {Param($nuestraubicacióndelarchivo, $specificline)Procesar$newstreamreader = New-Object System.IO.StreamReader($nuestraubicacióndelarchivo)$cadalíneanúmero = 1while (($readeachline = $newstreamreader.ReadLine()) -ne $null){if ($eachlinenumber -eq $specificline){$readeachlinebreak;}$reachlinenumber++}$newstreamreader.Dispose()}$savelinetovariable = Get-FileData -ourfilelocation «C:\logging\logging.txt» -specificline 17$savelinetovariable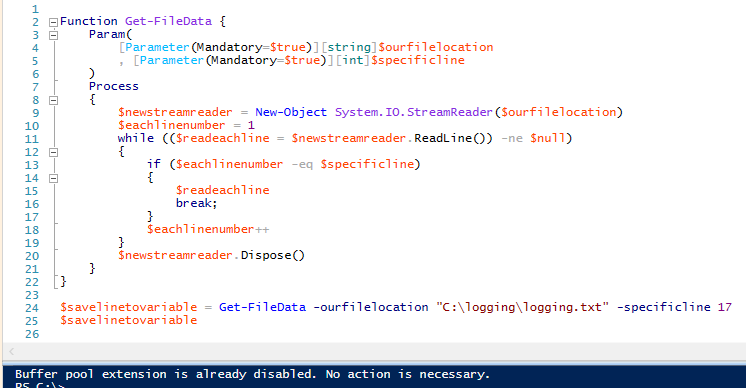
Si comprobamos, la línea 17 devuelve «La extensión del pool de búferes ya está desactivada. No es necesaria ninguna acción» correctamente. Además, rompemos la sentencia if – ya que no es necesario seguir leyendo el fichero una vez que obtenemos la línea de datos que queremos. Además, el método dispose sí termina el objeto, como podemos comprobar llamando al método desde la línea de comandos en PowerShell ISE y no devolverá nada (también podríamos comprobarlo dentro de la función y obtener el mismo resultado):
Pensamientos finales
Para un rendimiento personalizado, StreamReader ofrece más potencial, ya que podemos leer cada línea de datos y aplicar nuestras funciones adicionales según necesitemos. Pero no siempre necesitamos algo a medida y puede que sólo queramos leer unas pocas primeras y últimas líneas de datos, en cuyo caso la función Get-Content nos viene bien. Además, los archivos más pequeños funcionan bien con Get-Content, ya que nunca estamos recibiendo demasiados datos a la vez. Sólo hay que tener cuidado si los archivos tienden a crecer con el tiempo.
- Autor
- Postes recientes
 Tim administra cientos de instancias de SQL Server y MongoDB, y se centra principalmente en el diseño de la arquitectura adecuada para el modelo de negocio.
Tim administra cientos de instancias de SQL Server y MongoDB, y se centra principalmente en el diseño de la arquitectura adecuada para el modelo de negocio.
Ha pasado una década trabajando en FinTech, junto con algunos años en BioTech y Energy Tech.Es el anfitrión del Grupo de Usuarios de SQL Server del Oeste de Texas, además de impartir cursos y escribir artículos sobre SQL Server, ETL y PowerShell.
En su tiempo libre, es un colaborador de la industria financiera descentralizada.
Ver todas las entradas de Timothy SmithÚltimas entradas de Timothy Smith (ver todas)- Enmascaramiento de datos o alteración de información de comportamiento – 26 de junio, 2020
- Pruebas de seguridad con rangos de volumen de datos extremos – 19 de junio de 2020
- Ajuste del rendimiento de SQL Server – esperas RESOURCE_SEMAPHORE – 16 de junio de 2020