In questo articolo, discuteremo il processo di importazione di un file .csv in una tabella PostgreSQL.
Per fare ciò avremo bisogno di una tabella che può essere ottenuta utilizzando il seguente comando:
CREATE TABLE persons( id serial NOT NULL, first_name character varying(50), last_name character varying(50), dob date, email character varying(255), CONSTRAINT persons_pkey PRIMARY KEY (id));
Ora creiamo un file .csv nel nostro gestore di fogli (es: MS Excel o notepad) come mostrato di seguito:
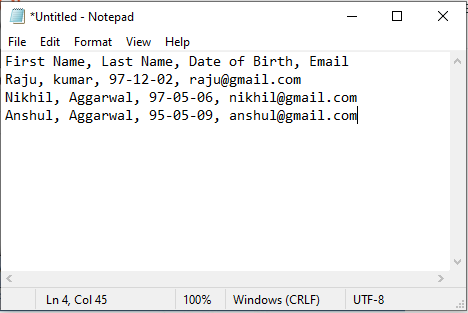
Il nostro file si trova come persons.csv a C:\Users\Raju
Esempio:
Per importare questo file CSV nella tabella delle persone, si usa la dichiarazione COPY come segue:
COPY persons(first_name, last_name, dob, email) FROM 'C:\Users\Raju' DELIMITER ', ' CSV HEADER;
Ora, controlliamo la tabella delle persone come segue:
SELECT * FROM persons;
Ci porterà al seguente output:
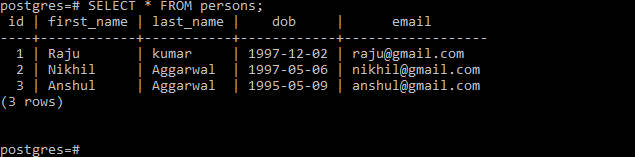
È importante mettere il percorso del file CSV dopo la parola chiave FROM. Poiché viene usato il formato CSV, è necessario menzionare le parole chiave DELIMITER e ‘CSV’. La parola chiave HEADER indica che il file CSV comprende una riga di intestazione con i nomi delle colonne. Quando si importano i dati, PostgreSQL trascura la prima riga in quanto è la riga di intestazione del file.
Il file deve essere letto direttamente dal server PostgreSQL e non dall’applicazione client. Pertanto, deve essere accessibile alla macchina server PostgreSQL. Inoltre, è possibile eseguire l’istruzione COPY con successo se si ha accesso ai superutenti.