Twoja tabela może zawierać zduplikowane wartości w kolumnie i w pewnych scenariuszach możesz wymagać pobrania tylko unikalnych rekordów z tabeli.
Aby usunąć zduplikowane rekordy z danych pobranych za pomocą instrukcji SELECT, możesz użyć klauzuli DISTINCT, jak pokazano w poniższych przykładach.
Demonstracja prostego SELECT – DISTINCT
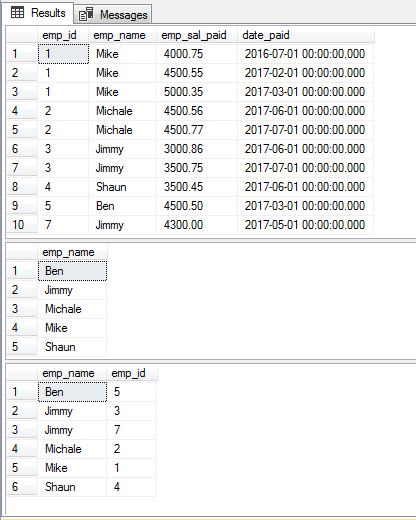
W pierwszym przykładzie, użyłem klauzuli DISTINCT z instrukcją SELECT, aby pobrać tylko unikalne nazwiska z naszej tabeli demo, sto_emp_salary_paid. Tabela ta przechowuje pensje pracowników wraz z ich nazwiskami. W związku z tym, w tabeli występują duplikaty nazwisk pracowników.
Przez użycie klauzuli DISTINCT, otrzymamy tylko unikalne nazwiska pracowników:
Zapytanie:
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid;
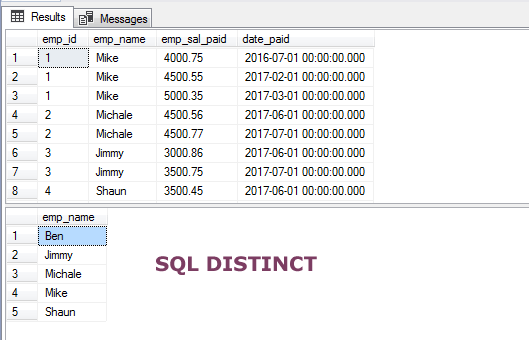
(Dotyczy baz danych SQL Server i MySQL)
Użycie klauzuli WHERE z DISTINCT
W tym przykładzie, Użyłem klauzuli WHERE z instrukcją SELECT/DISTINCT, aby pobrać tylko tych unikalnych pracowników, których wynagrodzenie jest większe lub równe 4500. Zobacz zapytanie i zbiór wyników:
Zapytanie:
|
1
2
3
|
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
WHERE emp_sal_paid >= 4500;
|

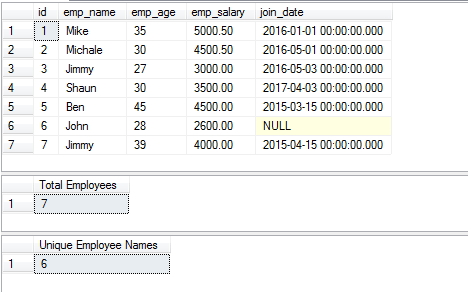
Przykład funkcji COUNT z DISTINCT
Do uzyskania liczby rekordów można również użyć funkcji COUNT SQL jak przy użyciu klauzuli DISTINCT. Funkcja zwraca tylko liczbę wierszy zwróconych po klauzuli DISTINCT.
Do dema wykorzystuję tabelę employee, która przechowuje informacje o pracownikach. Trzy zapytania są użyte w demie w następujący sposób:
- Pierwsze zapytanie zwraca kompletny rekord z tabeli
- Drugie zapytanie pobiera liczbę pracowników za pomocą ID (COUNT i DISTINCT)
- Trzecie zapytanie zwraca unikalne nazwiska pracowników za pomocą kolumny emp_name.
Trzy zapytania to:
|
1
2
1
3
3
4.
3
4
5
6
7
|
SELECT * FROM sto_employees;
SELECT COUNT(DISTINCT id) AS „Total Employees” FROM sto_employees
SELECT COUNT(DISTINCT emp_name) AS „Unique Employee Names” FROM sto_employees
|
Klauzula DISTINCT z GROUP BY przykład
Poniższe zapytanie pobiera rekordy z tej samej tabeli, która została użyta w powyższych przykładach i grupuje pracowników, którym wypłacono wynagrodzenia. W tym celu użyto klauzul GROUP BY oraz DISTINCT w następujący sposób:
Zapytanie:
|
1
2
3
|
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As „Total Paid” FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id;
|
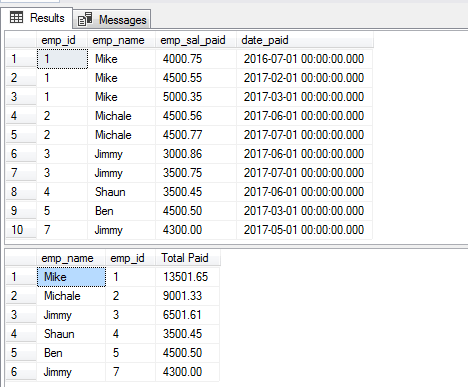
Rekord dla „Jaśka” pojawia się dwukrotnie, ponieważ ma dwa różne identyfikatory.
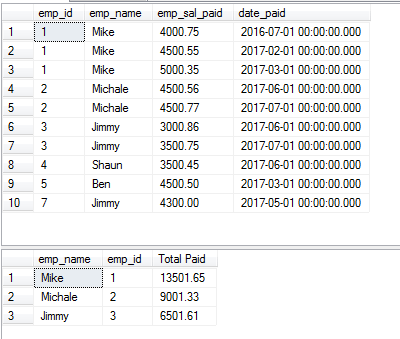
Użycie klauzuli HAVING z DISTINCT
Tak jak w przypadku użycia klauzuli GROUP BY z DISTINCT, możesz również dodać klauzulę HAVING do pobierania rekordów. W poniższym zapytaniu, klauzula HAVING jest dodana w powyższym przykładzie i będziemy pobierać rekordy, których SUM jest większe niż 5000.
Zapytanie:
|
1
2
3
4
5
|
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As „Total Paid” FROM sto_emp_salary_paid
GROUP BY emp_name,emp_id
HAVING SUM(emp_sal_paid) > 5000;
|
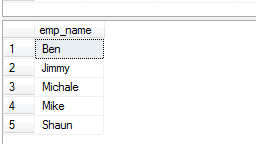
Klauzula DISTINCT z. ORDER BY przykład
Klauzula SQL ORDER BY może być używana z klauzulą DISTINCT do sortowania wyników po usunięciu zduplikowanych wartości. Zobacz zapytanie i dane wyjściowe poniżej:
|
1
2
3
|
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid
ORDER BY emp_name;
|
Wynik:
Użycie wielu kolumn w klauzuli DISTINCT
Możesz również określić dwie lub więcej kolumn jako używając klauzuli SELECT – DISTINCT. Nasza przykładowa tabela zawiera zduplikowane wartości dla pracowników i ich ID, więc będzie to dobra nauka, aby zobaczyć jak klauzula DISTINCT zwraca rekordy używając obu tych kolumn w pojedynczym zapytaniu.
Aby zobaczyć różnicę, najpierw napisałem zapytanie z klauzulą DISTINCT (emp_name), po której następuje użycie obu kolumn:
Zapytanie:
|
1
2
3
4
5
6
7
8
9
|
SELECT DISTINCT emp_name FROM sto_emp_salary_paid
ORDER BY emp_name;
SELECT DISTINCT emp_name,emp_id FROM sto_emp_salary_paid
ORDER BY emp_name;
|
Wyniki dla pełnych tabel, zapytań DISTINCT emp_name oraz DISTINCT emp_name,emp_id: