Wprowadzenie
Każda aplikacja lub strona internetowa, która odnotowuje znaczący wzrost, w końcu będzie musiała się skalować, aby sprostać zwiększonemu ruchowi. W przypadku aplikacji i witryn opartych na danych, bardzo ważne jest, aby skalowanie odbywało się w sposób zapewniający bezpieczeństwo i integralność danych. Trudno jest przewidzieć, jak popularna stanie się dana witryna lub aplikacja i jak długo utrzyma swoją popularność, dlatego niektóre organizacje wybierają architekturę bazy danych, która pozwala im na dynamiczne skalowanie baz danych.
W tym artykule omówimy jedną z takich architektur baz danych: sharded databases. W ostatnich latach wiele uwagi poświęca się shardingowi, ale wiele osób nie rozumie czym on jest i jakie scenariusze mogą mieć sens. Omówimy czym jest sharding, niektóre z jego głównych zalet i wad, a także kilka popularnych metod shardingu.
Czym jest sharding?
Sharding jest wzorcem architektury bazy danych związanym z partycjonowaniem poziomym – praktyką rozdzielania wierszy jednej tabeli na wiele różnych tabel, zwanych partycjami. Każda partycja ma ten sam schemat i kolumny, ale także zupełnie inne wiersze. Podobnie, dane przechowywane w każdej z nich są unikalne i niezależne od danych przechowywanych w innych partycjach.
Pomocne może być myślenie o partycjonowaniu poziomym w kategoriach tego, jak odnosi się ono do partycjonowania pionowego. W tabeli podzielonej pionowo, całe kolumny są oddzielane i umieszczane w nowych, odrębnych tabelach. Dane przechowywane w jednej partycji pionowej są niezależne od danych we wszystkich pozostałych, a każda z nich posiada zarówno odrębne wiersze, jak i kolumny. Poniższy diagram ilustruje, w jaki sposób tabela może być podzielona zarówno poziomo, jak i pionowo:
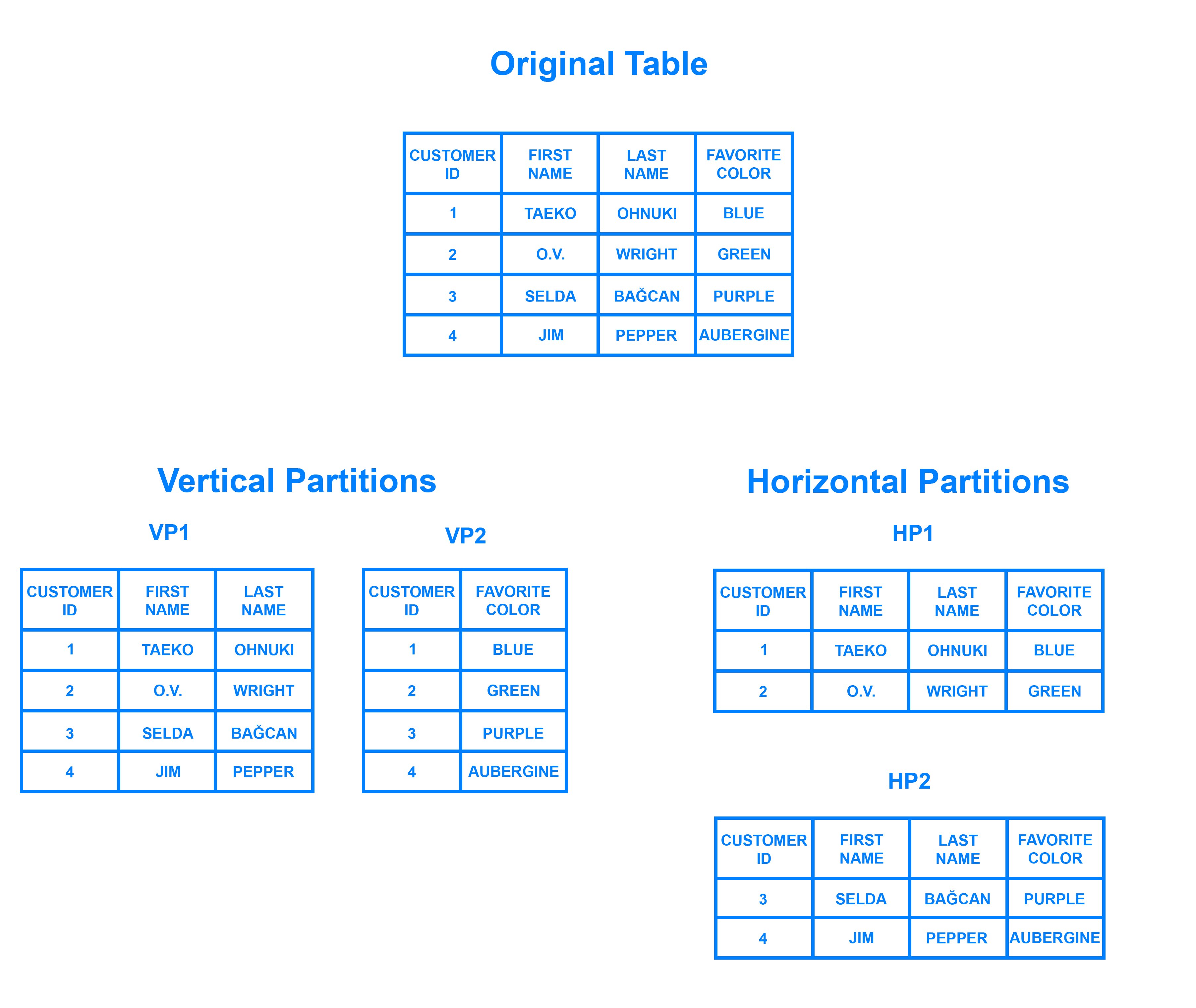
Sharding polega na rozbiciu danych na dwa lub więcej mniejszych kawałków, zwanych logicznymi fragmentami. Te logiczne fragmenty są następnie dystrybuowane pomiędzy oddzielnymi węzłami bazy danych, zwanymi fizycznymi fragmentami, które mogą zawierać wiele logicznych fragmentów. Pomimo tego, dane przechowywane we wszystkich shardach reprezentują wspólnie cały logiczny zbiór danych.
Database shards są przykładem architektury typu shared-nothing. Oznacza to, że shardy są autonomiczne, nie współdzielą żadnych danych ani zasobów obliczeniowych. W niektórych przypadkach jednak, może mieć sens replikowanie pewnych tabel do każdego sharda, aby służyły jako tabele referencyjne. Na przykład, załóżmy, że istnieje baza danych dla aplikacji, która zależy od stałych przeliczników dla pomiarów wagi. Poprzez replikację tabeli zawierającej niezbędne dane przeliczników do każdego shardu, pomogłoby to zapewnić, że wszystkie dane wymagane do zapytań są przechowywane w każdym shardzie.
Często sharding jest implementowany na poziomie aplikacji, co oznacza, że aplikacja zawiera kod, który definiuje, do którego shardu przekazywać odczyty i zapisy. Jednak niektóre systemy zarządzania bazą danych mają wbudowane możliwości shardingu, pozwalające na implementację shardingu bezpośrednio na poziomie bazy danych.
Pomny tego ogólnego przeglądu shardingu, przejdźmy do niektórych pozytywów i negatywów związanych z tą architekturą bazy danych.
Korzyści z shardingu
Głównym atutem shardingu jest to, że może on ułatwić skalowanie poziome, znane również jako skalowanie zewnętrzne. Skalowanie poziome to praktyka dodawania kolejnych maszyn do istniejącego stosu w celu rozłożenia obciążenia i umożliwienia większego ruchu i szybszego przetwarzania. Jest to często przeciwstawiane skalowaniu pionowemu, znanemu jako skalowanie w górę, które polega na ulepszaniu sprzętu istniejącego serwera, zazwyczaj poprzez dodanie większej ilości pamięci RAM lub procesora.
Jest to stosunkowo proste, aby mieć relacyjną bazę danych działającą na pojedynczej maszynie i skalować ją w razie potrzeby poprzez ulepszanie jej zasobów obliczeniowych. Ostatecznie jednak, każda nierozproszona baza danych będzie ograniczona pod względem pamięci masowej i mocy obliczeniowej, więc posiadanie swobody skalowania poziomego czyni konfigurację znacznie bardziej elastyczną.
Innym powodem, dla którego niektórzy mogą wybrać architekturę sharded database, jest chęć przyspieszenia czasu odpowiedzi na zapytania. Kiedy składasz zapytanie do bazy danych, która nie została sharded, może ona być zmuszona do przeszukania każdego wiersza w tabeli, do której kierujesz zapytanie, zanim znajdzie zestaw wyników, którego szukasz. Dla aplikacji z dużą, monolityczną bazą danych, zapytania mogą stać się zbyt wolne. Poprzez sharding jednej tabeli na wiele, zapytania muszą przejść przez mniejszą liczbę wierszy, a ich zestawy wyników są zwracane znacznie szybciej.
Sharding może również pomóc uczynić aplikację bardziej niezawodną poprzez złagodzenie wpływu przestojów. Jeśli Twoja aplikacja lub strona internetowa opiera się na niesharded database, awaria może spowodować, że cała aplikacja będzie niedostępna. W przypadku sharded bazy danych, awaria prawdopodobnie dotknie tylko pojedynczy shard. Nawet jeśli spowoduje to, że niektóre części aplikacji lub witryny staną się niedostępne dla niektórych użytkowników, ogólny wpływ będzie mniejszy niż w przypadku awarii całej bazy danych.
Wady shardingu
Pomimo, że sharding bazy danych może ułatwić skalowanie i poprawić wydajność, może również nałożyć pewne ograniczenia. Omówimy tutaj niektóre z nich oraz powody, dla których warto unikać shardingu.
Pierwszą trudnością, jaką napotyka się przy shardingu, jest sama złożoność poprawnego wdrożenia architektury shardowanej bazy danych. Jeśli zostanie to zrobione niepoprawnie, istnieje znaczne ryzyko, że proces shardingu może doprowadzić do utraty danych lub uszkodzenia tabel. Nawet jeśli zostanie to zrobione poprawnie, sharding będzie miał duży wpływ na przepływ pracy w Twoim zespole. Zamiast dostępu do danych i zarządzania nimi z jednego punktu wejścia, użytkownicy muszą zarządzać danymi w wielu lokalizacjach shardów, co może być potencjalnie uciążliwe dla niektórych zespołów.
Jednym z problemów, które użytkownicy napotykają po utworzeniu shardów w bazie danych jest to, że shardy w końcu stają się niezrównoważone. Na przykład, powiedzmy, że masz bazę danych z dwoma oddzielnymi shardami, jeden dla klientów, których nazwiska zaczynają się na litery od A do M, a drugi dla tych, których nazwiska zaczynają się na litery od N do Z. Jednakże, Twoja aplikacja obsługuje nadmierną ilość osób, których nazwiska zaczynają się na literę G. W związku z tym, shard A-M stopniowo gromadzi więcej danych niż N-Z, powodując spowolnienie aplikacji i zatrzymanie się dla znacznej części użytkowników. Shard A-M stał się tak zwanym hotspotem bazy danych. W tym przypadku, wszelkie korzyści wynikające z podziału bazy danych na shardy są niwelowane przez spowolnienia i awarie. Baza danych prawdopodobnie będzie musiała zostać naprawiona i ponownie podzielona na shardy, aby umożliwić bardziej równomierną dystrybucję danych.
Inną poważną wadą jest to, że po podzieleniu bazy danych na shardy, może być bardzo trudno przywrócić ją do nie podzielonej architektury. Wszelkie kopie zapasowe bazy danych wykonane przed shardedem nie będą zawierały danych zapisanych od momentu partycjonowania. W związku z tym odbudowanie oryginalnej, nie podzielonej na partycje architektury wymagałoby połączenia nowych, podzielonych na partycje danych ze starymi kopiami zapasowymi lub, alternatywnie, przekształcenia podzielonego DB z powrotem w pojedynczy DB, co w obu przypadkach byłoby kosztownym i czasochłonnym przedsięwzięciem.
Ostatnią wadą, którą należy rozważyć, jest fakt, że sharding nie jest natywnie obsługiwany przez każdy silnik bazy danych. Na przykład PostgreSQL nie posiada funkcji automatycznego dzielenia na mniejsze części, ale możliwe jest ręczne dzielenie na mniejsze części bazy danych PostgreSQL. Istnieje wiele wersji Postgres, które obsługują automatyczny podział na sektory, ale często są one opóźnione w stosunku do najnowszej wersji PostgreSQL i nie posiadają niektórych innych funkcji. Niektóre specjalistyczne technologie bazodanowe – takie jak MySQL Cluster lub niektóre produkty typu database-as-a-service, takie jak MongoDB Atlas – zawierają funkcję automatycznego dzielenia na mniejsze części, ale wersje waniliowe tych systemów zarządzania bazami danych nie posiadają takich funkcji. Z tego powodu, sharding często wymaga podejścia „roll your own”. Oznacza to, że dokumentacja dotycząca shardingu lub wskazówki dotyczące rozwiązywania problemów są często trudne do znalezienia.
To są oczywiście tylko niektóre ogólne kwestie, które należy rozważyć przed rozpoczęciem shardingu. Potencjalnych wad shardingu może być znacznie więcej, w zależności od przypadku użycia bazy danych.
Jak już omówiliśmy kilka wad i zalet shardingu, zajmiemy się kilkoma różnymi architekturami dla shardowanych baz danych.
Architektury shardingu
Jeśli zdecydowałeś się na sharding swojej bazy danych, następną rzeczą jaką musisz ustalić jest sposób w jaki to zrobisz. Podczas wykonywania zapytań lub dystrybucji przychodzących danych do shardowanych tabel lub baz danych, ważne jest, aby trafiały one do właściwego sharda. W przeciwnym razie, może to spowodować utratę danych lub boleśnie powolne wykonywanie zapytań. W tej sekcji omówimy kilka popularnych architektur shardingu, z których każda używa nieco innego procesu do dystrybucji danych na shardach.
Key Based Sharding
Key based sharding, znany również jako hash based sharding, polega na użyciu wartości pobranej z nowo zapisanych danych – takich jak numer ID klienta, adres IP aplikacji klienta, kod ZIP, itp. Funkcja hashująca to funkcja, która bierze na wejście kawałek danych (na przykład e-mail klienta) i wyprowadza dyskretną wartość, znaną jako wartość hash. W przypadku shardingu, wartość hash jest identyfikatorem shardu używanym do określenia, na którym shardzie będą przechowywane przychodzące dane. W sumie, proces wygląda następująco:

Aby zapewnić, że wpisy są umieszczane we właściwych shardach i w spójny sposób, wartości wprowadzone do funkcji hash powinny pochodzić z tej samej kolumny. Ta kolumna jest znana jako klucz sharda. W prostych słowach, klucze shard są podobne do kluczy głównych w tym, że obie są kolumnami, które są używane do ustanowienia unikalnego identyfikatora dla poszczególnych wierszy. Ogólnie rzecz biorąc, klucz shard powinien być statyczny, co oznacza, że nie powinien zawierać wartości, które mogą się zmieniać w czasie. W przeciwnym razie, zwiększy to ilość pracy wykonywanej przy operacjach aktualizacji i może spowolnić wydajność.
Pomimo, że sharding oparty na kluczach jest dość powszechną architekturą shardingu, może on sprawić, że sytuacja stanie się trudna, gdy będziesz próbował dynamicznie dodawać lub usuwać dodatkowe serwery do bazy danych. W miarę dodawania serwerów, każdy z nich będzie potrzebował odpowiedniej wartości hash i wiele z istniejących wpisów, jeśli nie wszystkie, będą musiały zostać przemapowane do ich nowej, poprawnej wartości hash, a następnie zmigrowane do odpowiedniego serwera. Gdy zaczniesz rebalansować dane, ani nowe, ani stare funkcje haszujące nie będą ważne. W konsekwencji, Twój serwer nie będzie w stanie zapisać żadnych nowych danych podczas migracji i Twoja aplikacja może być narażona na przestoje.
Głównym atutem tej strategii jest to, że może być używana do równomiernego rozprowadzania danych, aby zapobiec hotspotom. Ponadto, ponieważ dane są dystrybuowane algorytmicznie, nie ma potrzeby utrzymywania mapy lokalizacji wszystkich danych, jak to jest konieczne w przypadku innych strategii, takich jak sharding oparty na zakresach lub katalogach.
Range Based Sharding
Range based sharding polega na shardingu danych opartym na zakresach danej wartości. Dla zilustrowania, załóżmy, że masz bazę danych, która przechowuje informacje o wszystkich produktach w katalogu detalisty. Mógłbyś stworzyć kilka różnych shardów i podzielić informacje o każdym z produktów na podstawie zakresu cenowego, w którym się znajdują, tak jak poniżej:

Główną zaletą shardingu opartego na zakresach cenowych jest to, że jest on stosunkowo prosty w implementacji. Każdy shard przechowuje inny zestaw danych, ale wszystkie one mają identyczny schemat jak siebie nawzajem, jak również oryginalną bazę danych. Kod aplikacji po prostu odczytuje, do którego zakresu należą dane i zapisuje je do odpowiedniego shardu.
Z drugiej strony, sharding oparty na zakresach nie chroni danych przed nierównomiernym rozłożeniem, co prowadzi do wspomnianych wcześniej hotspotów w bazie danych. Patrząc na przykładowy diagram, nawet jeśli każdy shard przechowuje równą ilość danych, istnieje prawdopodobieństwo, że konkretne produkty otrzymają więcej uwagi niż inne. Ich odpowiednie shardy będą z kolei otrzymywać nieproporcjonalnie dużą liczbę odczytów.
Directory Based Sharding
Aby zaimplementować sharding oparty na katalogach, należy stworzyć i utrzymywać tabelę lookup, która używa klucza shardu do śledzenia, który shard przechowuje jakie dane. W skrócie, tabela lookup jest tabelą, która przechowuje statyczny zestaw informacji o tym, gdzie można znaleźć określone dane. Poniższy diagram pokazuje uproszczony przykład shardingu opartego na katalogach:
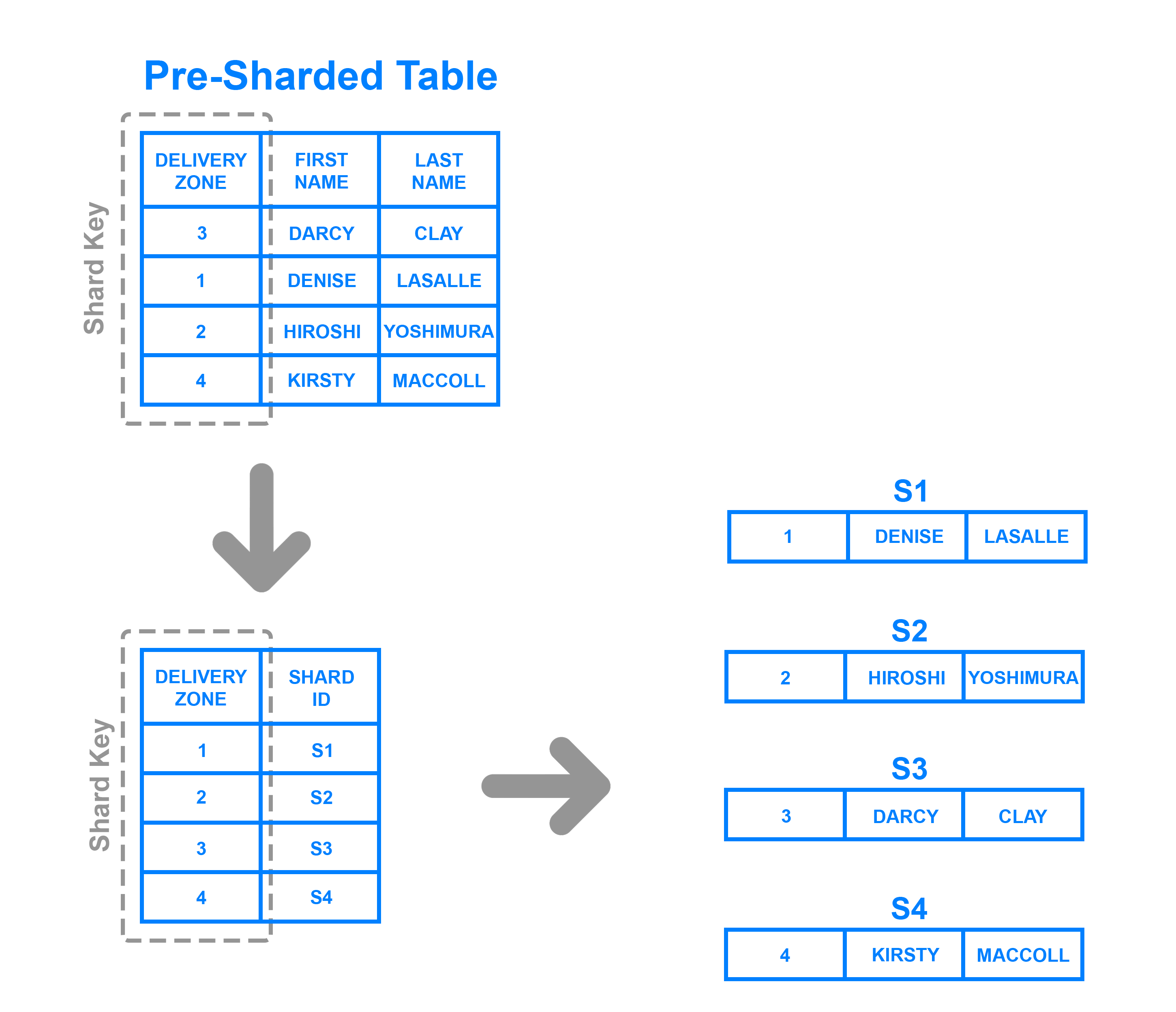
W tym przypadku kolumna Delivery Zone jest zdefiniowana jako klucz shard. Dane z klucza shardu są zapisywane do tabeli lookup wraz z tym, do jakiego shardu powinny być zapisane poszczególne wiersze. Jest to podobne do shardingu opartego o zakres, ale zamiast określać zakres, w którym znajdują się dane klucza shard, każdy klucz jest powiązany z własnym określonym shardem. Sharding oparty na katalogach jest dobrym wyborem w przypadkach, gdy klucz shardu ma niską kardynalność i nie ma sensu, aby shard przechowywał zakres kluczy. Zauważ, że różni się on od shardingu opartego na kluczach tym, że nie przetwarza klucza shardu przez funkcję haszującą; po prostu sprawdza klucz w tabeli wyszukiwania, aby zobaczyć, gdzie dane muszą być zapisane.
Głównym atutem shardingu opartego na katalogach jest jego elastyczność. Architektury shardingu oparte na zakresach ograniczają Cię do określania zakresów wartości, podczas gdy te oparte na kluczach ograniczają Cię do używania stałej funkcji hash, która, jak wspomniano wcześniej, może być niezwykle trudna do zmiany w późniejszym czasie. Z drugiej strony, sharding oparty na katalogach pozwala na użycie dowolnego systemu lub algorytmu do przypisania wpisów danych do shardów i jest stosunkowo łatwy do dynamicznego dodawania shardów przy użyciu tego podejścia.
Pomimo że sharding oparty na katalogach jest najbardziej elastyczną z omawianych tu metod shardingu, konieczność łączenia się z tabelą wyszukującą przed każdym zapytaniem lub zapisem może mieć szkodliwy wpływ na wydajność aplikacji. Co więcej, tabela wyszukująca może stać się pojedynczym punktem awarii: jeśli zostanie uszkodzona lub w inny sposób ulegnie awarii, może to wpłynąć na zdolność użytkownika do zapisywania nowych danych lub dostępu do istniejących danych.
Czy powinienem shardować?
Czy powinno się wdrożyć architekturę shardowanej bazy danych, czy też nie, jest prawie zawsze kwestią dyskusyjną. Niektórzy postrzegają sharding jako nieunikniony rezultat dla baz danych, które osiągają pewien rozmiar, podczas gdy inni widzą go jako ból głowy, którego należy unikać, chyba że jest to absolutnie konieczne, ze względu na złożoność operacyjną, którą sharding dodaje.
Z powodu tej dodatkowej złożoności, sharding jest zazwyczaj wykonywany tylko wtedy, gdy mamy do czynienia z bardzo dużymi ilościami danych. Oto kilka typowych scenariuszy, w których sharding bazy danych może być korzystny:
- Ilość danych aplikacji przekracza pojemność pamięci masowej pojedynczego węzła bazy danych.
- Ilość zapisów lub odczytów bazy danych przekracza możliwości pojedynczego węzła lub jego replik odczytu, co skutkuje spowolnieniem czasu odpowiedzi lub timeoutami.
- Pasmo sieciowe wymagane przez aplikację przekracza pasmo dostępne dla pojedynczego węzła bazy danych i jego replik odczytu, co skutkuje spowolnieniem czasu odpowiedzi lub timeoutami.
Przed shardingiem należy wyczerpać wszystkie inne opcje optymalizacji bazy danych. Niektóre optymalizacje, które możesz rozważyć to:
- Ustawienie zdalnej bazy danych. Jeśli pracujesz z monolityczną aplikacją, w której wszystkie jej komponenty znajdują się na tym samym serwerze, możesz poprawić wydajność bazy danych przenosząc ją na własny komputer. Nie dodaje to tak wiele złożoności jak sharding, ponieważ tabele bazy danych pozostają nienaruszone. Jednakże, nadal pozwala to na pionowe skalowanie bazy danych niezależnie od reszty infrastruktury.
- Wdrożenie buforowania. Jeśli wydajność odczytu Twojej aplikacji jest tym, co sprawia Ci problemy, buforowanie jest jedną ze strategii, która może pomóc w jej poprawie. Buforowanie polega na tymczasowym przechowywaniu w pamięci danych, które zostały już zażądane, co pozwala na szybszy dostęp do nich w późniejszym czasie.
- Tworzenie jednej lub więcej replik odczytu. Inną strategią, która może pomóc poprawić wydajność odczytu, jest kopiowanie danych z jednego serwera bazy danych (serwera głównego) na jeden lub więcej serwerów drugorzędnych. Następnie każdy nowy zapis trafia na serwer główny przed skopiowaniem go na serwery drugorzędne, podczas gdy odczyty wykonywane są wyłącznie na serwerach drugorzędnych. Rozkładanie odczytów i zapisów w ten sposób zapobiega przejmowaniu zbyt dużego obciążenia przez jedną maszynę, co pomaga zapobiegać spowolnieniom i awariom. Należy pamiętać, że tworzenie replik odczytu wymaga więcej zasobów obliczeniowych, a zatem kosztuje więcej pieniędzy, co może być istotnym ograniczeniem dla niektórych.
- Modernizacja do większego serwera. W większości przypadków, skalowanie serwera bazy danych do maszyny z większymi zasobami wymaga mniej wysiłku niż sharding. Podobnie jak w przypadku tworzenia replik odczytu, rozbudowany serwer z większymi zasobami będzie prawdopodobnie kosztował więcej pieniędzy. W związku z tym, powinieneś przejść przez zmianę rozmiaru tylko wtedy, gdy naprawdę okaże się to najlepszą opcją.
Pamiętaj, że jeśli Twoja aplikacja lub strona internetowa rozrośnie się do pewnego stopnia, żadna z tych strategii nie będzie wystarczająca, aby poprawić wydajność na własną rękę. W takich przypadkach, sharding może być rzeczywiście najlepszą opcją dla Ciebie.
Podsumowanie
Sharding może być świetnym rozwiązaniem dla tych, którzy chcą skalować swoją bazę danych w poziomie. Jednakże, dodaje on również wiele złożoności i tworzy więcej potencjalnych punktów awarii dla Twojej aplikacji. Sharding może być konieczny dla niektórych, ale czas i zasoby potrzebne do stworzenia i utrzymania architektury sharded mogą przeważyć korzyści dla innych.
Po przeczytaniu tego artykułu powinieneś lepiej zrozumieć wady i zalety shardingu. Dzięki temu będziesz mógł podjąć bardziej świadomą decyzję, czy architektura sharded jest odpowiednia dla Twojej aplikacji.