Jeśli nie jesteś jeszcze zaznajomiony z modelami drzewiastymi w uczeniu maszynowym, powinieneś zapoznać się z naszym kursem R na ten temat.
Algorytm Lasów Losowych
Zrozummy algorytm w prostych słowach. Załóżmy, że chcesz wyjechać na wycieczkę i chciałbyś pojechać w miejsce, które Ci się spodoba.
Co więc robisz, aby znaleźć miejsce, które Ci się spodoba? Możesz szukać online, czytać recenzje na blogach i portalach podróżniczych, możesz też zapytać swoich przyjaciół.
Załóżmy, że zdecydowałeś się zapytać swoich przyjaciół i rozmawiałeś z nimi o ich doświadczeniach z podróży do różnych miejsc. Otrzymasz kilka rekomendacji od każdego przyjaciela. Teraz musisz zrobić listę tych polecanych miejsc. Następnie poprosić ich o głosowanie (lub wybrać jedno najlepsze miejsce na wycieczkę) z listy rekomendowanych miejsc, które zrobiłeś. Miejsce z największą liczbą głosów będzie Twoim ostatecznym wyborem na wycieczkę.
W powyższym procesie decyzyjnym są dwie części. Po pierwsze, pytasz znajomych o ich indywidualne doświadczenia z podróży i otrzymujesz jedną rekomendację spośród wielu miejsc, które odwiedzili. Ta część jest jak użycie algorytmu drzewa decyzyjnego. Tutaj każdy znajomy dokonuje wyboru miejsc, które odwiedził do tej pory.
Druga część, po zebraniu wszystkich rekomendacji, to procedura głosowania w celu wybrania najlepszego miejsca z listy rekomendacji. Cały ten proces uzyskiwania rekomendacji od znajomych i głosowania na nie w celu znalezienia najlepszego miejsca jest znany jako algorytm lasów losowych.
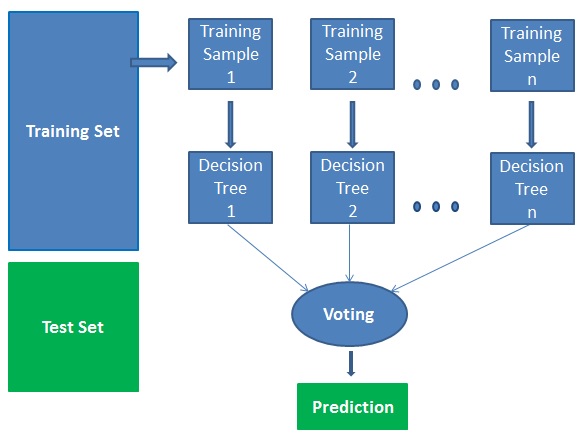
Technicznie jest to metoda zespołu (oparta na podejściu „dziel i zwyciężaj”) drzew decyzyjnych wygenerowanych na losowo podzielonym zbiorze danych. Ten zbiór klasyfikatorów drzew decyzyjnych jest również znany jako las. Poszczególne drzewa decyzyjne są generowane przy użyciu wskaźnika wyboru atrybutu, takiego jak zysk informacyjny, współczynnik zysku i wskaźnik Giniego dla każdego atrybutu. Każde drzewo zależy od niezależnej próbki losowej. W przypadku problemu klasyfikacji, każde drzewo głosuje, a najbardziej popularna klasa jest wybierana jako wynik końcowy. W przypadku regresji, średnia wszystkich wyników drzewa jest uważana za wynik końcowy. Jest prostszy i bardziej wydajny w porównaniu z innymi nieliniowymi algorytmami klasyfikacji.
Jak działa algorytm?
Działa w czterech krokach:
- Wybierz losowe próbki z danego zbioru danych.
- Zbuduj drzewo decyzyjne dla każdej próbki i uzyskaj wynik predykcji z każdego drzewa decyzyjnego.
- Wykonaj głosowanie dla każdego przewidywanego wyniku.
- Wybierz wynik predykcji z największą liczbą głosów jako ostateczną predykcję.
Zalety:
- Lasy losowe są uważane za bardzo dokładną i solidną metodę ze względu na liczbę drzew decyzyjnych biorących udział w procesie.
- Nie cierpi ona na problem przepełnienia. Głównym powodem jest to, że bierze średnią ze wszystkich przewidywań, co niweluje błędy.
- Algorytm ten może być stosowany zarówno w problemach klasyfikacji, jak i regresji.
- Lasy losowe mogą również obsługiwać brakujące wartości. Istnieją dwa sposoby radzenia sobie z nimi: użycie wartości mediany w celu zastąpienia zmiennych ciągłych oraz obliczenie średniej ważonej bliskością brakujących wartości.
- Można uzyskać względne znaczenie cech, co pomaga w wyborze najbardziej istotnych cech dla klasyfikatora.
Wady:
- Lasy losowe są powolne w generowaniu przewidywań, ponieważ mają wiele drzew decyzyjnych. Za każdym razem, gdy dokonuje się przewidywania, wszystkie drzewa w lesie muszą dokonać przewidywania dla tego samego podanego wejścia, a następnie przeprowadzić głosowanie na nim. Cały ten proces jest czasochłonny.
- Model jest trudny do zinterpretowania w porównaniu do drzewa decyzyjnego, gdzie można łatwo podjąć decyzję, podążając ścieżką w drzewie.
Znajdowanie ważnych cech
Lasy losowe oferują również dobry wskaźnik wyboru cech. Scikit-learn dostarcza dodatkową zmienną z modelem, która pokazuje względną ważność lub wkład każdej cechy w predykcję. Automatycznie oblicza on wynik istotności każdej cechy w fazie szkolenia. Następnie skaluje istotność w dół tak, aby suma wszystkich wyników wynosiła 1.
Ten wynik pomoże Ci wybrać najważniejsze cechy i porzucić te najmniej ważne do budowy modelu.
Las losowy wykorzystuje ważność giniego lub średni spadek nieczystości (MDI) do obliczenia ważności każdej cechy. Znaczenie giniego jest również znane jako całkowity spadek nieczystości węzła. Jest to stopień, w jakim spada dopasowanie modelu lub jego dokładność, gdy usuwamy zmienną. Im większy spadek, tym bardziej znacząca jest zmienna. W tym przypadku, średni spadek jest istotnym parametrem przy wyborze zmiennych. Indeks Giniego może opisywać ogólną siłę objaśniającą zmiennych.
Lasy losowe vs Drzewa decyzyjne
- Lasy losowe są zbiorem wielu drzew decyzyjnych.
- Głębokie drzewa decyzyjne mogą cierpieć z powodu przepełnienia, ale lasy losowe zapobiegają przepełnieniu poprzez tworzenie drzew na losowych podzbiorach.
- Drzewa decyzyjne są obliczeniowo szybsze.
- Lasy losowe są trudne do interpretacji, podczas gdy drzewa decyzyjne są łatwe do interpretacji i mogą być przekształcone w reguły.
Budując klasyfikator przy użyciu Scikit-learn
Będziesz budował model na zbiorze danych kwiatów irysa, który jest bardzo znanym zbiorem klasyfikacyjnym. Składa się on z długości działek, szerokości działek, długości płatków, szerokości płatków oraz rodzaju kwiatów. Istnieją trzy gatunki lub klasy: setosa, versicolor i virginia. Zbudujesz model klasyfikujący typ kwiatu. Zestaw danych jest dostępny w bibliotece scikit-learn lub można go pobrać z UCI Machine Learning Repository.
Zacznij od zaimportowania biblioteki datasets z scikit-learn, i załaduj zestaw danych irysów za pomocą load_iris().
#Import scikit-learn dataset libraryfrom sklearn import datasets#Load datasetiris = datasets.load_iris()Możesz wydrukować nazwy celów i cech, aby upewnić się, że masz właściwy zbiór danych, w taki sposób:
# print the label species(setosa, versicolor,virginica)print(iris.target_names)# print the names of the four featuresprint(iris.feature_names)Dobrym pomysłem jest zawsze zbadać trochę swoje dane, więc wiesz, z czym pracujesz. Tutaj możesz zobaczyć, że pierwsze pięć wierszy zbioru danych jest drukowanych, a także zmienną docelową dla całego zbioru danych.
# print the iris data (top 5 records)print(iris.data)# print the iris labels (0:setosa, 1:versicolor, 2:virginica)print(iris.target) ]Tutaj możesz utworzyć DataFrame zbioru danych tęczówki w następujący sposób.
# Creating a DataFrame of given iris dataset.import pandas as pddata=pd.DataFrame({ 'sepal length':iris.data, 'sepal width':iris.data, 'petal length':iris.data, 'petal width':iris.data, 'species':iris.target})data.head()| długość płatka | petal width | sepal length | sepal width | species | |
|---|---|---|---|---|---|
| 0 | 1.4 | 0.2 | 5.1 | 3.5 | 0 |
| 1 | 1.4 | 0.2 | 4.9 | 3.0 | 0 |
| 2 | 1.3 | 0.2 | 4.7 | 3.2 | 0 |
| 3 | 1.5 | 0.2 | 4.6 | 3.1 | 0 |
| 4 | 1.4 | 0.2 | 5.0 | 3.6 | 0 |
Najpierw rozdzielasz kolumny na zmienne zależne i niezależne (lub cechy i etykiety). Następnie dzielisz te zmienne na zbiór treningowy i testowy.
# Import train_test_split functionfrom sklearn.model_selection import train_test_splitX=data] # Featuresy=data # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testPo podzieleniu, będziesz trenować model na zbiorze treningowym i wykonywać predykcje na zbiorze testowym.
#Import Random Forest Modelfrom sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)Po treningu sprawdź dokładność, używając rzeczywistych i przewidywanych wartości.
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.93333333333333335)Możesz również dokonać predykcji dla pojedynczego elementu, na przykład:
- długość działek = 3
- szerokość działek = 5
- długość płatków = 4
- szerokość płatków = 2
Teraz możesz przewidzieć, jaki to jest rodzaj kwiatu.
clf.predict(])array()Tutaj 2 oznacza typ kwiatu Virginica.
Znajdywanie ważnych cech w Scikit-learn
Tutaj znajdujemy ważne cechy lub wybieramy cechy w zbiorze danych IRIS. W scikit-learn możesz wykonać to zadanie w następujących krokach:
- Po pierwsze, musisz utworzyć model lasów losowych.
- Po drugie, użyj zmiennej ważności cech, aby zobaczyć wyniki ważności cech.
- Po trzecie, zwizualizuj te wyniki za pomocą biblioteki seaborn.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)import pandas as pdfeature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)feature_imppetal width (cm) 0.458607petal length (cm) 0.413859sepal length (cm) 0.103600sepal width (cm) 0.023933dtype: float64Możesz również zwizualizować ważność cech. Wizualizacje są łatwe do zrozumienia i interpretacji.
Do wizualizacji możesz użyć kombinacji matplotlib i seaborn. Ponieważ seaborn jest zbudowany na matplotlib, oferuje wiele niestandardowych tematów i zapewnia dodatkowe typy działek. Matplotlib jest supersetem seaborn i oba są równie ważne dla dobrych wizualizacji.
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline# Creating a bar plotsns.barplot(x=feature_imp, y=feature_imp.index)# Add labels to your graphplt.xlabel('Feature Importance Score')plt.ylabel('Features')plt.title("Visualizing Important Features")plt.legend()plt.show()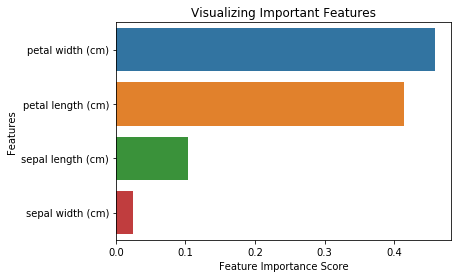
Generowanie modelu na wybranych cechach
W tym miejscu można usunąć cechę „szerokość działek”, ponieważ ma ona bardzo małe znaczenie, i wybrać 3 pozostałe cechy.
# Import train_test_split functionfrom sklearn.cross_validation import train_test_split# Split dataset into features and labelsX=data] # Removed feature "sepal length"y=data # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% testPo podziale, wygenerujesz model na wybranych cechach zbioru treningowego, wykonasz predykcje na wybranych cechach zbioru testowego i porównasz wartości rzeczywiste i przewidywane.
from sklearn.ensemble import RandomForestClassifier#Create a Gaussian Classifierclf=RandomForestClassifier(n_estimators=100)#Train the model using the training sets y_pred=clf.predict(X_test)clf.fit(X_train,y_train)# prediction on test sety_pred=clf.predict(X_test)#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))('Accuracy:', 0.95238095238095233)Widzisz, że po usunięciu najmniej ważnych cech (długość przegrody), dokładność wzrosła. Dzieje się tak, ponieważ usunąłeś wprowadzające w błąd dane i szum, co spowodowało wzrost dokładności. Mniejsza ilość cech redukuje również czas treningu.
Wniosek
Gratulacje, dotarłeś do końca tego tutoriala!
W tym tutorialu nauczyłeś się czym są lasy losowe, jak działają, jak znaleźć ważne cechy, porównanie lasów losowych i drzew decyzyjnych, zalety i wady. Nauczyłeś się również budować modele, oceniać je i znajdować ważne cechy w scikit-learn. B
Jeśli chciałbyś dowiedzieć się więcej o uczeniu maszynowym, polecam Ci zapoznać się z naszym kursem Supervised Learning in R: Classification course.