Abbiamo alcuni file personalizzati che riceviamo da diversi fornitori e per queste situazioni non siamo in grado di utilizzare programmi ETL standard senza alcuna personalizzazione. Dato che stiamo espandendo la nostra capacità di leggere questi file personalizzati con .NET, stiamo cercando modi efficienti per leggere i file con PowerShell che possiamo usare in SQL Server Job Agents, Windows Task Schedulers, o con il nostro programma personalizzato, che può eseguire script PowerShell. Abbiamo molti strumenti per il parsing dei dati e volevamo conoscere modi efficienti di leggere i dati per il parsing, insieme a ottenere linee specifiche di dati dai file per numero, o per la prima o l’ultima riga del file. Per leggere i file in modo efficiente, quali sono alcune funzioni o librerie che possiamo usare?
Panoramica
Per leggere i dati dai file, generalmente vogliamo concentrarci su tre funzioni principali per completare questi compiti insieme ad alcuni esempi elencati accanto ad esse di queste nella pratica:
- Come leggere un intero file, parte di un file o saltare in un file. Potremmo trovarci di fronte a una situazione in cui vogliamo leggere ogni riga tranne la prima e l’ultima.
- Come leggere un file usando poche risorse di sistema. Potremmo avere un file di 100GB che vogliamo leggere solo 108KB di dati.
- Come leggere un file in un modo che ci permetta facilmente di analizzare i dati di cui abbiamo bisogno o ci permetta di usare funzioni o strumenti che usiamo con altri dati. Poiché molti sviluppatori hanno strumenti di parsing delle stringhe, spostare i dati in un formato di stringa – se possibile – ci permette di riutilizzare molti strumenti di parsing delle stringhe.
Quanto sopra si applica alla maggior parte delle situazioni coinvolte con l’analisi dei dati dai file. Inizieremo guardando una funzione integrata in PowerShell per la lettura dei dati, poi vedremo un modo personalizzato di leggere i dati dai file usando PowerShell.
Funzione Get-Content di PowerShell
L’ultima versione di PowerShell (versione 5) e molte versioni precedenti di PowerShell hanno la funzione Get-Content e questa funzione ci permette di leggere rapidamente i dati di un file. Nello script seguente, mostriamo i dati di un intero file sullo schermo di PowerShell ISE – uno schermo che useremo a scopo dimostrativo in questo articolo:
|
1
|
Get-Contenuto “C:\logging\logging.txt”
|
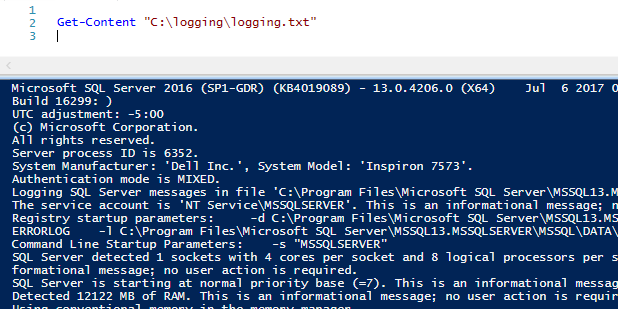
Possiamo salvare questa intera quantità di dati in una stringa, chiamata ourfilesdata:
|
1
2
|
$ourfilesdata = Get-Contenuto “C:\logging\logging.txt”
$ourfilesdata
|
Otteniamo lo stesso risultato del precedente, l’unica differenza è che abbiamo salvato l’intero file in una variabile. Ci troviamo di fronte a un inconveniente, però, se salviamo un intero file in una variabile o se emettiamo un intero file: se la dimensione del file è grande, dovremo leggere l’intero file in una variabile o emettere l’intero file sullo schermo. Questo comincia a costarci in termini di prestazioni, dato che abbiamo a che fare con file di grandi dimensioni.
Possiamo selezionare una parte del file trattando la nostra variabile (l’oggetto è un altro nome) come una query SQL dove selezioniamo alcuni dei file invece di tutti. Nel codice qui sotto, selezioniamo le prime cinque righe del file, piuttosto che l’intero file:
|
1
2
|
$ourfilesdata = Get-Contenuto “C:\logging\logging.txt”
$ourfilesdata | Select-Object -First 5
|
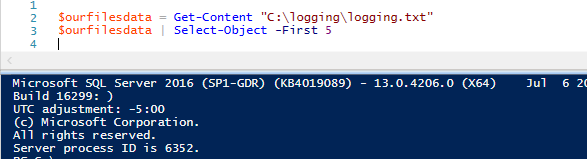
Possiamo anche usare la stessa funzione per ottenere le ultime cinque righe del file, usando una sintassi simile:
|
1
2
|
$ourfilesdata = Get-Content “C:\logging\logging.txt”
$ourfilesdata | Select-Object -Ultimi 5
|
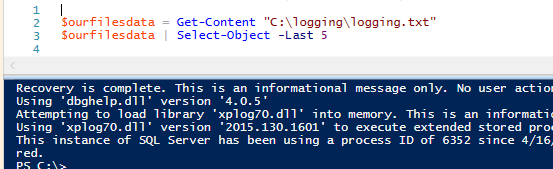
La funzione integrata Get-Content di PowerShell può essere utile, ma se vogliamo memorizzare pochi dati ad ogni lettura per motivi di parsing, o se vogliamo leggere riga per riga per il parsing di un file, potremmo voler utilizzare la classe StreamReader di .NET, che ci permetterà di personalizzare il nostro utilizzo per una maggiore efficienza. Questo rende Get-Content un ottimo lettore di base per i dati dei file.
La libreria StreamReader
In una nuova finestra PowerShell ISE, creeremo un oggetto StreamReader e smaltiremo questo stesso oggetto eseguendo il seguente codice PowerShell:
|
1
2
3
|
$newstreamreader = New-Oggetto System.IO.StreamReader(“C:\logging\logging.txt”)
#### Lettura di file qui
$newstreamreader.Dispose()
|
In generale, ogni volta che creiamo un nuovo oggetto, è una buona pratica rimuovere quell’oggetto, in quanto rilascia risorse di calcolo su quell’oggetto. Anche se è vero che .NET lo fa automaticamente, raccomando comunque di farlo manualmente, perché potreste lavorare con linguaggi che non lo fanno automaticamente in futuro ed è una buona pratica.
Non succede niente quando eseguiamo il codice sopra perché non abbiamo chiamato nessun metodo – abbiamo solo creato un oggetto e lo abbiamo rimosso. Il primo metodo che vedremo è il metodo ReadToEnd():
|
1
2
3
|
$newstreamreader = New-Oggetto System.IO.StreamReader(“C:\logging\logging.txt”)
$newstreamreader.ReadToEnd()
$newstreamreader.Dispose()
|
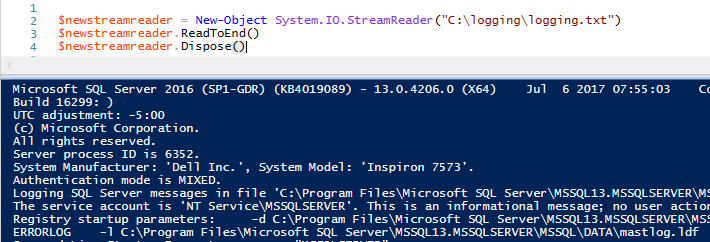
Come vediamo nell’output, possiamo leggere tutti i dati dal file come con Get-Content usando il metodo ReadToEnd(); come facciamo a leggere ogni riga di dati? Incluso nella classe StreamReader c’è il metodo ReadLine() e se lo chiamiamo al posto di ReadToEnd(), otterremo la prima riga dei dati del nostro file:
|
1
2
3
|
$newstreamreader = New-Oggetto System.IO.StreamReader(“C:\logging\logging.txt”)
$newstreamreader.ReadLine()
$newstreamreader.Dispose()
|

Dato che abbiamo detto allo StreamReader di leggere la linea, ha letto la prima linea del file e si è fermato. La ragione di questo è che il metodo ReadLine() legge solo la linea corrente (in questo caso, la linea uno). Dobbiamo continuare a leggere il file finché non raggiungiamo la fine del file. Come facciamo a sapere quando un file finisce? La linea finale è nulla. In altre parole, vogliamo che lo StreamReader continui a leggere il file (while loop) finché ogni nuova linea non è nulla (in altre parole, ha dei dati). Per dimostrarlo, aggiungiamo un contatore di linee ad ogni linea su cui iteriamo in modo da poter vedere la logica con numeri e testo:
|
1
2
3
4
5
6
7
8
|
$newstreamreader = New-Oggetto System.IO.StreamReader(“C:\logging\logging.txt”)
$eachlinenumber = 1
while (($readeachline =$newstreamreader.ReadLine()) -ne $null)
{
Write-Host “$eachlinenumber $readeachline”
$eachlinenumber++
}
$newstreamreader.Dispose()
|
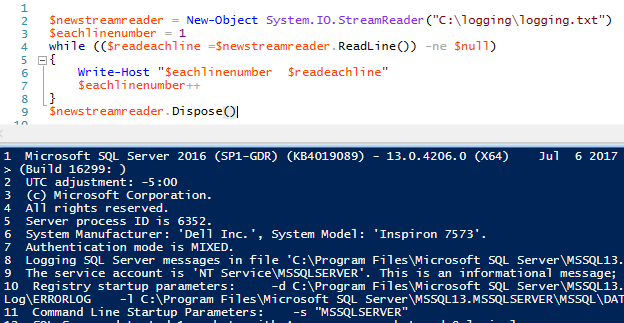
Mentre StreamReader legge ogni riga, memorizza i dati della riga nell’oggetto che abbiamo creato $readeachline. Possiamo applicare funzioni di stringa a questa linea di dati ad ogni passaggio, come ad esempio ottenere i primi dieci caratteri della linea di dati:
|
1
2
3
4
5
6
7
|
$newstreamreader = New-Oggetto System.IO.StreamReader(“C:\logging\logging.txt”)
$eachlinenumber = 1
while (($readeachline = $newstreamreader.ReadLine()) -ne $null)
{
$readeachline.Substring(0,10)
}
$newstreamreader.Dispose()
|
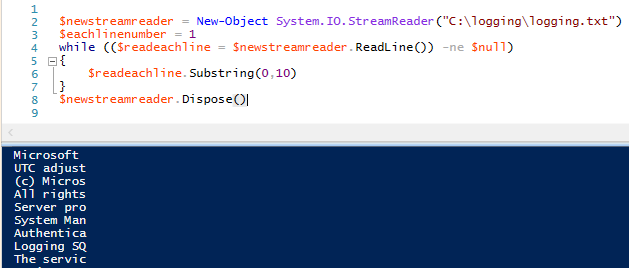
Possiamo estendere questo esempio e chiamare altri due metodi di stringa – questa volta includendo i metodi di stringa IndexOf e Replace(). Chiamiamo questi metodi solo sulle prime due righe ottenendo solo le righe inferiori alla terza:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$newstreamreader = New-Oggetto System.IO.StreamReader(“C:\logging\logging.txt”)
$eachlinenumber = 1
while (($readeachline = $newstreamreader.ReadLine()) -ne $null)
{
if ($eachlinenumber -lt 3)
{
Write-Host “$eachlinenumber”
$readeachline.Substring(0,12)
$readeachline.IndexOf(” “)
$readeachline.Replace(” “, “replace”)
}
$eachlinenumber++
}
$newstreamreader.Dispose()
|
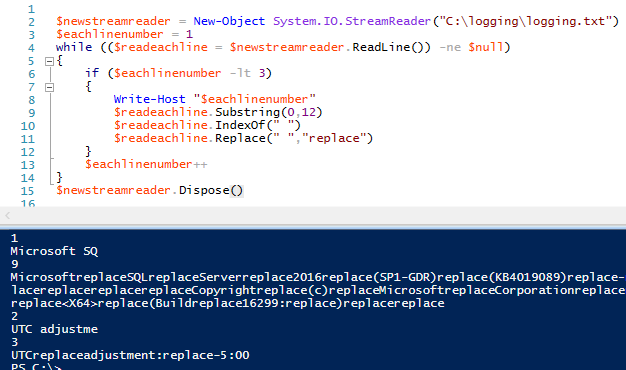
Per analizzare i dati, possiamo usare i nostri metodi di stringa su ogni linea del file – o su una linea specifica del file – ad ogni iterazione del ciclo.
Infine, vogliamo essere in grado di ottenere una linea specifica dal file – possiamo ottenere la prima e l’ultima linea del file usando Get-Content. Usiamo StreamReader per scommettere un numero di linea specifico che passiamo ad una funzione personalizzata che creiamo. Creeremo una funzione riutilizzabile che restituisca un numero di linea specifico, poi vogliamo avvolgere la nostra funzione per il riutilizzo richiedendo due input: la posizione del file e il numero di linea specifico che vogliamo restituire.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
Funzione Get-FileData {
Param(
$ourfilelocation
, $specificline
)
Process
{
$newstreamreader = New-Object System.IO.StreamReader($ourfilelocation)
$eachlinenumber = 1
while (($readeachline = $newstreamreader.ReadLine()) -ne $null)
{
if ($eachlinenumber -eq $specificline)
{
$readeachline
break;
}
$eachlinenumber++
}
$newstreamreader.Dispose()
}
}
$savelinetovariabile = Get-FileData -ourfilelocation “C:\logging\logging.txt” -specificline 17
$savelinetovariabile
|
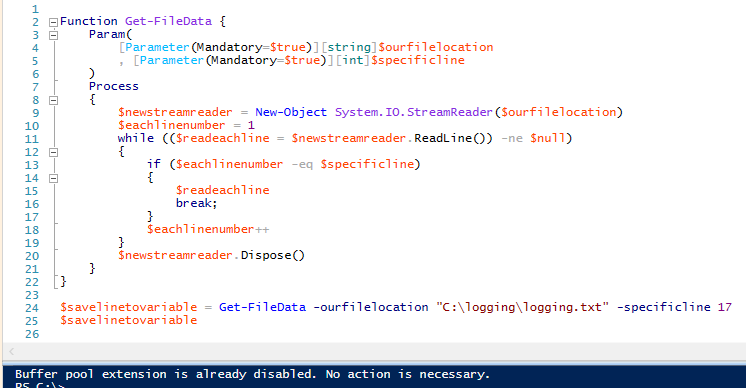
Se controlliamo, la linea 17 restituisce “L’estensione del pool di buffer è già disabilitata. Non è necessaria alcuna azione”. Inoltre, interrompiamo l’istruzione if – poiché non c’è bisogno di continuare a leggere il file una volta ottenuta la linea di dati che vogliamo. Inoltre, il metodo dispose termina l’oggetto, come possiamo controllare chiamando il metodo dalla linea di comando in PowerShell ISE e non restituirà nulla (potremmo anche controllare all’interno della funzione e ottenere lo stesso risultato):
Pensieri finali
Per le prestazioni personalizzate, StreamReader offre più potenziale, in quanto possiamo leggere ogni riga di dati e applicare le nostre funzioni aggiuntive come abbiamo bisogno. Ma non abbiamo sempre bisogno di qualcosa da personalizzare e potremmo voler leggere solo alcune prime e ultime righe di dati, nel qual caso la funzione Get-Content ci va bene. Inoltre, i file più piccoli funzionano bene con Get-Content perché non stiamo mai ottenendo troppi dati alla volta. Fate solo attenzione se i file tendono a crescere nel tempo.
- Autore
- Post recenti

Ha trascorso un decennio lavorando nel settore FinTech, insieme ad alcuni anni in BioTech e Energy Tech. Ospita il gruppo di utenti SQL Server del Texas occidentale, oltre a tenere corsi e scrivere articoli su SQL Server, ETL e PowerShell.
Nel suo tempo libero, è un collaboratore dell’industria finanziaria decentralizzata.
Vedi tutti i post di Timothy Smith
- Data Masking or Altering Behavioral Information – June 26, 2020
- Test di sicurezza con intervalli di volume di dati estremi – 19 giugno 2020
- Messa a punto delle prestazioni di SQL Server – attese RESOURCE_SEMAPHORE – 16 giugno 2020